Mise en place d'une infrastructure Docker Swarm
Frédéric Minne - Université catholique de Louvain
Travail réalisé dans le cadre d'un brevet pour l'obtention du barème d'informaticien expert.
 This work is licensed under a Creative Commons Attribution 4.0 International License.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Plan
- Introduction : présentation générale du contexte et du périmètre de ce travail
- Docker, Docker Swarm et les infrastructures à base de conteneurs : introduction technique à Docker et au mode Swarm
- Mise en place d'une infrastructure de démonstration : documentation et enseignements de la mise en place d'une infrastructure de démonstration
- Déploiement d'applications et livraison continue : recettes de déploiement d'applications, livraison continue avec gitlab, gitlab-ci et docker
- Perspectives : considérations et recommendations pour le passage en production d'une infrastructure Docker Swarm
- Conclusion : conclusion et propositions pour le futur
- Bibliographie et ressources
- Annexes : éléments complémentaires et anciennes versions de l'infrastructure
Introduction
Contexte et enjeux
Apparues au début des années 2000, les infrastructures à base de conteneurs sont devenues un des outils clés de l'informatique moderne. Cette tendance a encore été renforcée par le développement des infrastructures dans le cloud qui supportent de plus en plus souvent le déploiement de conteneurs. On constate donc une multiplication de l'usage des conteneurs, et cette demande en termes de conteneurs va sans doute encore augmenter dans les prochaines années.
Une multiplication de l'usage des conteneurs
Qu’il s’agisse d’applications mises en place au sein des services informatiques ou dans le cadre de projets de recherche ou de fin d'études (mémoires de master…), les demandes pour des infrastructures à base conteneurs se multiplient à l'UCLouvain. Citons par exemple : les infrastructures web pour le nouveau portail web UCLouvain en Drupal (SISG), l'infrastructure elastic search pour le service des bibliothèques (BIB et SISG), l'infrastructure pour DIGIT (SIPS)...
Par ailleurs ce recours de plus en plus fréquent aux conteneurs dans le monde académique ou scientifique n'est pas le monopole de l'UCLouvain et se rencontre dans de nombreuses institutions. L’un des domaines concernés est la mise en place d’infrastructure pour les outils TICE. Les conteneurs sont d'ailleurs devenus un sujet récurrent du JIRES1.
A cela s’ajoute une utilisation de plus en plus fréquente des conteneurs pour la mise en place d’environnements de développement local, que ce soit avec un outil générique comme Docker Compose2 ou avec des solutions spécifiques comme ddev3 pour les applications PHP\MySQL. Il serait dès lors intéressant de pouvoir déployer en production les applications développées au sein des différentes équipes avec les mêmes technologies utilisées par les équipes de développement.
Mais au-delà du développement d'application, les conteneurs permettent aussi un déploiement d'applications pré-configurées (configuration as code), l'upgrade plus sûr des applications en production, des cycles de release plus courts (voire de l'intégration continue)...
De nombreuses applications proposent donc des procédures de déploiement basées sur les conteneurs, par exemple Ceph qui utilise l'orchestrateur Podman pour déployer son cluster, et les compétences dans ce domaine vont devoir se développer au sein des équipes.
Des applications aux besoins variés et plus complexes à mettre en production
De petites applications métier disponibles en ligne sont développées et mises en place afin de rendre des services à l’ensemble des informaticien·ne·s et autres usager·e·s de l'UCLouvain :
- Hébergement d'applications web.
- Applications métier.
- Outils de développement ou de collaboration.
- Outil de gestion des groupes.
- Valves électroniques...
La plupart de ces applications sont développées sur base de technologies et d'environnements d'exécution variés, avec de nombreux impacts pour les équipes qui les gèrent :
- Elles dépendent souvent de versions différentes d’un même langage de programmation ou d'un environnement d'exécution dont la coexistence sur une même machine est problématique.
- Elles nécessitent des versions différentes de services tiers et qui doivent cohabiter sur une même machine (virtuelle le plus souvent)
- Elles sont parfois mal isolées les unes des autres et une faille de sécurité dans une d’entre elles peut compromettre toute la machine qui les héberge
Tout cela peut causer des difficultés lors de l’installation, de la maintenance ou de la configuration des machines d’hébergement et entraîner une consommation parfois inutile de ressources. De plus cela impose souvent de multiplier les machines virtuelles pour les héberger.
L'ère des applications monolithiques est aujourd'hui révolue. La plupart des applications modernes se basent sur une pile applicative constituée de nombreux services (base de données, authentification, environnement d'exécution, service de cache, mailing...) séparés et uns des autres. Cela multiplie les applications à déployer et à maintenir.
Parmi les solutions ont été proposées au fil des années, les technologies de conteneurs (la plus connue étant Docker) répondent à ces enjeux. Elles permettent de déployer et de faire coexister des environnements d’exécution hétérogènes très facilement sur une même machine4. Elles permettent un meilleur contrôle de l’isolation entre ceux-ci et facilitent leur déploiement et leur mise à jour. Elles permettent également une répartition de la charge sur plusieurs machines hôtes. Enfin, elles facilitent le déploiement des applications à partir de fichiers de configuration de piles applicatives.
Ce type d'infrastructure à base de conteneurs pourrait également être déployé dans le cadre d'un hébergement web qui, par nature, est hétérogène et utilise une grande variété de technologies.
Contenu et délivrables du brevet
Afin d'explorer les possibilités des conteneurs et de constituer une base pour développer les compétences des équipes intéressées par ce type d'infrastructure (équipe système, portail...), il s’agira dans ce brevet d’étudier et d’expérimenter la mise en place d’une infrastructure à base de conteneurs. Comme point de départ, j'ai envisagé une infrastructure qui pourrait succéder à l’infrastructure « webapps » actuelle de SISG5,
Au-delà de cette infrastructure proprement dite, il s'agira également de tester des outils permettant l'automatisation des tâches de gestion de l’infrastructure et de déploiement d’applications sur celle-ci.
Il s’agira également d’examiner les perspectives quant à la mise en production d’une telle infrastructure.
Les délivrables sont :
- La mise en place d’une infrastructure de démonstration basée sur Docker pour l’hébergement et le développement d’applications web et qui a servi de base à mon travail.
- Une documentation (le présent document) décrivant la mise en place de l’infrastructure, les étapes nécessaires pour la répliquer ou la reconstruire et les outils permettant d’en automatiser les tâches de gestion. Y sont également abordées les questions relatives à la mise en production d’une telle infrastructure et au déploiement d’applications sur celle-ci.
- Les fichiers techniques (scripts, fichiers de configuration, description des machines virtuels, fichiers images docker…) nécessaire à la mise en place de l'infrastructure et au déploiement d’applications web seront également mis à disposition.
La documentation et les fichiers techniques sont mis à disposition dans un dépôt Gitlab sur la forge institutionnelle.
Organisation du présent document
Dans la première partie de ce document, je donnerai une rapide introduction technique à Docker afin de fournir les bases nécessaires à la compréhension des chapitres suivants. Sa lecture est optionnelle pour les lecteurs ayant déjà utilisé Docker et Docker Swarm.
Dans un second temps, j'aborderai la mise en place d’une infrastructure de démonstration basée sur l'orchestrateur Docker Swarm. La forme que j'ai choisie est celle d'un mode d'emploi, afin de permettre à toute personne intéressée de pouvoir déployer une telle infrastructure.
Dans la troisième partie, je proposerai des solutions pour automatiser le déploiement de cette infrastructure ainsi que des outils permettant de faciliter sa gestion. Il s’agira aussi de décrire la manière dont les applications peuvent être déployées sur cette infrastructure.
Dans la quatrième partie, j'aborderai les perspectives liées à la mise en production de cette infrastructure et au changement technologique qu'elle implique. Il s'agira également de décrire comment le travail réalisé dans la deuxième partie pourra être transcrit en production. J’aborderai enfin quelques pistes pour l'avenir des infrastructures à base de conteneurs à l'UCLouvain.
Il sera alors temps pour moi de conclure et de remettre en contexte le travail réalisé.
Journées Réseaux de l’Enseignement et de la Recherche, organisées tous les deux ans en France https://www.jres.org/fr/
Docker Compose est un orchestrateur pour Docker et facilite le déploiement et la gestion de conteneur Docker sur une machine https://docs.docker.com/compose/
Développé au départ pour faciliter le développement de site Drupal, ddev est une suite d'outil automatisant le déploiement local de pile applicative PHP/MySQL (Wordpress, Drupal, Symfony...) https://ddev.com/
Il est également possible d’utiliser les technologies de conteneur afin de déployer des versions différentes d’un même environnement d’exécution sur une même machine d’hébergement. Il peut s’agir de versions différentes d’un langage de programmation (par exemple PHP 7.0, 7.2, 7.4, 5.6...) ou d’une même version mais avec des modules complémentaires différents. Voir par exemple « Utilisez plusieurs versions de PHP sur un même serveur web » publié dans le numéro 115 de Linux Pratique, sept-oct 2019
actuellement l’hébergement des « webapps » se fait sur l'infrastructure de l'hébergement institutionnel.
Docker, Docker Swarm et les infrastructures à base de conteneurs
- Conteneurs et machines virtuelles deux approches de la virtualisation
- Docker
- Docker Compose
- Docker Swarm
Conteneurs et machines virtuelles deux approches de la virtualisation
Ces 10 dernières années, la virtualisation d’infrastructure informatique, jusqu’alors dominée par les machines virtuelles, a connu un grand changement, et les technologies basées sur les conteneurs sont devenues un incontournable pour de nombreuses applications : développement, hébergement d’application web, calcul intensif, IoT, déploiement d’applications…
Si l’on peut faire remonter l’origine des mécanismes d’isolation de conteneurs à la commande chroot introduite en 1982 dans les systèmes UNIX, c’est au début des années 2000 que cette technologie va prendre sa forme actuelle avec des solutions telles que Linux-VServer (2000), Free BSD Jail (2000), OpenVZ (2005) ou Solaris Containers (2004)1.
Introduite en 2013, Docker n’est pas la seule solution de conteneur existant sur le marché, mais elle reste l'une des plus populaires. Parmi ses concurrents, on peut citer LXC (pour Linux Container) et son successeur LXD (Linux Container Daemon), CoreOS rkt (ou simplement Rkt), OpenVz, Apache Mesos, Podman ou encore containerd.
Devant ce grand nombre de solutions, l'Open Container Initiative (OCI) de la Linux Foundation définit des spécifications afin de garantir l’interopérabilité entre les solutions à base de conteneurs. Elle a défini des spécifications pour le format d’image OCI image-spec le l’environnement d’exécution runtime-spec – basé sur runC développé initialement par Docker.
Conteneurs et machines virtuelles : quelles différences ?
Conteneurs et machines virtuelles sont deux solutions de virtualisation d’infrastructure informatique et permettent d’isoler le fonctionnement d’un programme, donnant l’impression qu’il s’exécute dans un environnement dédié2.
- Une machine virtuelle (VM) virtualise le hardware afin d’exécuter un système d’exploitation complet qui permettra lui-même l’exécution des programmes. Un hyperviseur3 permet alors de contrôler les différentes VM sur une machine hôte.
- Un conteneur (ou conteneur d’application) virtualise uniquement un système d’exploitation qui permettra l’exécution des programmes. Un moteur de conteneurs permet alors de contrôler les différents conteneurs sur une (ou plusieurs) machine·s hôte·s.
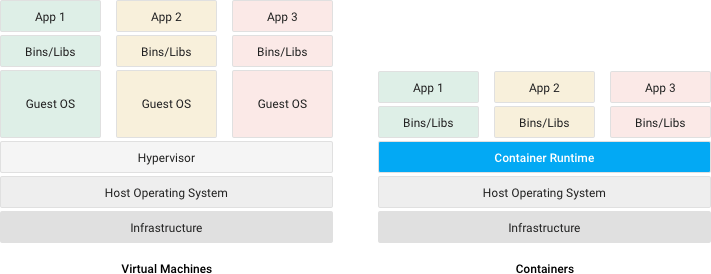
Illustration : Différences entre conteneurs et machines virtuelles – source : documentation du cloud Google
Les infrastructures « cloud » peuvent mettre en œuvre ces 2 mécanismes pour déployer les applications : des machines virtuelles déployées sur un hyperviseur vont servir d’hôtes pour un environnement d’exécution de conteneurs tel que Docker.
Dans les deux cas (machine virtuelle ou conteneur), un orchestrateur peut-être utilisé pour gérer l’infrastructure :
- Un orchestrateur de machines virtuelles (Vagrant, Open Nebula, Open Stack…) permet de gérer un ou plusieurs hyperviseurs (KVM, Virtualbox, VMWare...) et d'y déployer des machines virtuelles.
- Un orchestrateur de conteneurs (Docker Compose, Docker Swarm, Kubernetes, Podman, Amazon ECS, Azure Container Service…) permet de déployer et de gérer les conteneurs sur plusieurs systèmes hôtes.
Note : Certains orchestrateurs comme Vagrant, Open Nebula ou Terraform permettent de gérer tant des VM que des conteneurs.
Avantages et limites des conteneurs
Les conteneurs offrent des avantages par rapport aux machines virtuelles. En voici quelques uns :
- Abstraction : les conteneurs suppriment la dépendance envers l’infrastructure et le besoin d'interagir directement avec le système hôte.
- Automatisation et portabilité : les conteneurs facilitent l’automatisation des tâches (déploiement, mise à jour…) et augmentent ainsi la portabilité des applications.
- Sécurité et isolation : la sécurité des applications conteneurisées (isolation, réseau, pare-feu, accès aux données…) est gérée au niveau de la plateforme, en dehors des conteneurs, ce qui réduit fortement la complexité de leur mise en œuvre. De plus, chaque conteneur s’exécute dans un environnement isolé des autres réduisant ainsi l’impact d’un problème.
- Déploiement sur le cloud : la portabilité des conteneurs et la division des applications en services indépendants permet un déploiement facilité dans le cloud.
- Usage réduit des ressources système : les conteneurs constituent une solution de virtualisation plus légère et avec moins de perte de performances que les machines virtuelles.
- Cycle de vie des applications : les conteneurs facilitent et accélèrent le cycle de vie des applications du développement au déploiement en production. Ils facilitent en particulier le déploiement et la mise à jour de piles applicatives sur un cluster ou sur un grand nombre de systèmes en parallèle (par exemple pour l'IoT).
- Architecture en micro-services : légers et portables, les conteneurs simplifient la mise en place d’infrastructure en micro-services4.
Mêmes s’ils peuvent fortement faciliter leur travail, les conteneurs ne sont pas la solution miracle à tous les problèmes d’un sysadmin ou d’un développeur !
Bien qu’ils isolent les applications entre elles et réduisent ainsi les dangers pour l’infrastructure dans son ensemble, les conteneurs ne résoudront pas les problèmes de sécurité d’une application ! Si une faille permet d’exposer, par exemple, les données des utilisateurs d’un CMS, ce sera toujours le cas dans une infrastructure en conteneurs. En d’autres termes, une application mal écrite restera une application mal écrite même si elle s’exécute dans un conteneur.

Illustration : Isolation d’une application mal écrite dans un conteneur, mème humoristique inspiré de la tapisserie de Bayeux, auteur inconnu
De même, s’ils facilitent la mise en place de micro-services, les conteneurs ne transformeront pas magiquement une application monolithique en micro-services ! Cela requiert un travail au niveau du design des applications elles-mêmes.
Malgré un mythe persistant, les conteneurs ne peuvent remplacer les machines virtuelles dans tous les cas ! Ils fournissent par exemple moins d’isolation que les machines virtuelles, puisque les conteneurs s’exécutent quand même dans un même système hôte. Si l’isolation d’un système est cruciale, une machine virtuelle reste donc préférable. Là où les conteneurs se révèlent intéressants, c’est qu’ils permettent facilement de mieux isoler entre elles des applications qui s’exécutaient déjà sur un même hôte.
Une autre limitation des systèmes de virtualisation à base de conteneur est que, comme ils opèrent au niveau du système d’exploitation et pas du hardware, il n’est pas possible d’exécuter des conteneurs avec un système d’exploitation différent de celui de leur hôte. Ainsi sous Linux, seuls des conteneurs Linux peuvent être exécutés. Il est toutefois possible d’exécuter des distributions Linux différentes de celle du système hôte, par exemple des conteneurs Debian ou CentOS peuvent sans problème s’exécuter sous Ubuntu, et de même une machine Ubuntu 18.04 peut sans problème exécuter d’autres versions même plus récentes d’Ubuntu. Déployer des conteneurs Linux sous MacOSX ou Windows nécessite donc une machine virtuelle Linux.
Ajoutons à cela que la majorité des solutions de virtualisation à base de conteneurs sont disponibles sous Linux uniquement, puisqu’elles se basent pour la plupart sur les mêmes mécanismes du noyau Linux.
Docker
Pourquoi choisir Docker ?
J'ai choisi Docker pour mon infrastructure pour les raisons suivantes :
- Répandu : Même s’il ne consiste pas le seul environnement d’exécution de conteneur disponible, Docker est de loin le plus populaire et le plus utilisé.
- Standard : Poussé par de grands acteurs comme Google, RedHat ou encore Ubuntu, supporté par le cloud Amazon ou Azure, Docker reste encore un standard de facto pour les infrastructures à base de conteneurs.
- Support : La société Docker Enterprise (rachetée par Mirabilis en 2019) offre du support et des services professionnels autour du Docker Engine.
- Multi-plateforme : Docker propose un environnement d’exécution (Docker Engine) disponible sur la plupart des plateformes (Linux, MacOS X et Windows) via Docker Desktop. Toutefois, l'installation serveur du Docker Engine ne fonctionne que sous Linux pour les conteneurs Linux ou Windows pour les conteneurs Windows. Dans tous les autres cas une VM Linux est requise.
- Multi-architecture : Docker est disponible pour diverses architectures matérielles et peut être déployé tant sur des serveurs que sur de l'IoT.
- Large écosystème : Docker fournit et supporte un large écosystème d’outils qui facilitent grandement le travail des informaticiens qu’ils soient administrateurs système, développeurs, packageurs d’application… Docker est de plus intégré comme backend à de nombreux outils : orchestrateurs (Vagrant), plateformes de CI/CD (Gitlab), outils d’automatisation (Ansible)
- Disponibilité d’applications : De nombreuses applications web sont déjà prêtes à être déployées avec Docker via l’outil
docker compose. Des générateurs de configuration sont également disponibles sur le web. - Orchestrateurs : Des outils d’orchestration de parcs informatiques compatibles Docker sont déjà disponibles comme Kubernetes, Rancher, OpenShift… mais Docker lui-même intègre ses propres orchestrateurs permettant le déploiement sur un cluster via Docker Swarm ou sur une machine locale avec Docker Compose.
- Portabilité dans le cloud : Les conteneurs Docker peuvent être déployés dans le cloud (Azure, Amazon AWS) ou sur des « nano-ordinateurs » (Raspberry Pi, Olimex…) afin de mettre en place des solutions IoT (Internet of Things).
- Communauté et documentation : Docker a une large communauté et une grande quantité de documentation (sites web, livres, MOOCS, tutoriels…) est disponible. La documentation officielle est extrêmement complète et est fréquemment mise à jour.
Les technologies derrière Docker
Comme plusieurs autres technologies de conteneurs telles que LXC5, Docker se base sur des mécanismes et services de base du noyau Linux afin d’isoler les applications :
cgroups(control groups) assure la distribution des ressources du système hôte.namespaceassurent l’isolation des processus entre eux.containerdfournit des services nécessaires pour le fonctionnement des conteneurs.
Comme je l'ai déjà évoqué plus haut, Docker est donc une technologie intrinsèquement liée à Linux et ne peut s’exécuter sur les autres systèmes d’exploitation qu’à condition de passer par une machine virtuelle exécutant Linux. Il y a toutefois une exception pour Docker sous Windows qui permet de faire s’exécuter des conteneurs Windows via une implémentation native de runC 6.
Docker s’est vu adjoindre deux standards importants :
- Juin 2015, Open Container Initiative (OCI) : standardise les conteneurs entre les différents moteurs d’exécution existants en définissant des spécifications pour le runtime des conteneurs (Runtime spec) et les images (Image spec).
- Décembre 2016, Container Runtime Interface (CRI) : standardise la gestion des pods (ou stacks) de conteneurs dans le but d’utiliser une interface identique pour les différents moteurs d'exécution (permettant par exemple à Kubernetes d’utiliser Rkt ou Docker de manière identique).
Quelques concepts clés de Docker
- Container : un conteneur Docker est une unité logicielle légère et standardisée qui intègre une application et toutes ses dépendances afin de pouvoir les exécuter sur différents environnements logiciels. Un conteneur isole une application de son environnement et garanti qu’elle se comporte de manière identique sur tous les systèmes hôtes. Cela renforce la sécurité des applications.
- Docker Engine : c’est l’environnement d’exécution des conteneurs Docker. Le Docker Engine fournit aux conteneurs un environnement d’exécution aux propriétés identiques quel que soit le système hôte.
- Docker CLI : c’est l’outil en ligne de commande de Docker. Il propose de nombreuses commandes permettant d’interagir avec le moteur Docker : gérer les réseaux, construire des images, instancier des conteneurs, mettre à jour les services, gérer un cluster Docker Swarm…
- Hôte : machine virtuelle ou physique exécutant le Docker Engine.
- Image : une image Docker est un paquet de programmes exécutable, standalone et léger incluant tout ce qui est nécessaire pour faire fonctionner une application : code, environnement d'exécution, outils et bibliothèques système et configurations. Une image devient un conteneur lorsqu’elle est exécutée par le Docker Engine. Une image doit être construite (build) afin de pouvoir être utilisée.
- Layer : afin de gagner en place et en performance, les conteneurs et images Docker sont divisées en couche appelées layers. Ces couches sont stockées de manière indépendante, ce qui permet de les réutiliser entre plusieurs images. Chaque couche vient ajouter des fonctionnalités et des données à la précédente.
- Dockerfile : les étapes nécessaires à la configuration et à la construction d'une image Docker sont décrites dans un Dockerfile.
- Volume : un volume est un stockage de fichier permanent ou volatile monté dans un conteneur. Un volume peut-être partagé entre plusieurs conteneurs et peut correspondre ou non à un emplacement sur le système de fichier de la machine hôte. Les volumes Docker peuvent également être distants (par exemple en utilisant NFS).
- Réseau : Docker permet de définir des interfaces réseaux virtuelles qui permettent aux conteneurs de communiquer entre eux au sein d’un hôte ou d’une stack ou avec l’extérieur. En particulier, les réseaux de type overlay permettent aux services d’une stack exécutés sur différents nœuds d’un cluster de communiquer entre eux.
- Stack : une stack (pile) est un ensemble de services (c’est-à-dire d'applications qui s'exécutent dans des conteneurs Docker) liés qui partagent une série de dépendances et peuvent être orchestrés (déployés et gérés) ensemble. Dans un Swarm Docker, une stack peut être répartie sur plusieurs hôtes Docker et certains services peuvent être répliqués afin de fournir une répartition de charge. Les stacks permettent la mise en place d’une architecture de type micro-services dans laquelle les composants nécessaires au fonctionnement d’une application (base de données, serveur web, environnement d’exécution PHP…) sont exécutés dans des conteneurs différents.
- Service : un service est un des sous-éléments d’une stack. Un service peut-être répliqué, c’est à dire être rendus par plusieurs containers identiques que l'on nommera des tasks (ou tâches) dans le vocabulaire Docker. Cette réplication permet d’assurer le failover et un load balancing. Lorsque les services sont atomiques (chaque service intégrant une seule fonctionnalité comme un service serveur web, un service base de données et un service environnement d'exécution PHP-FPM), on parle alors de micro-services.
- Orchestrateur : outil de déploiement et de gestion de conteneurs, Docker en propose deux :
- Docker Compose : orchestrateur permettant de définir et de déployer des applications multi-services (stack) localement sur une machine. Cet outil est construit au-dessus de l'API de Docker. Même s'il peut être utilisé en production, il est plutôt destiné au développement ou à des architectures pour lesquelles Docker Swarm ne peut être utilisé (IoT par exemple).
- Docker Swarm : orchestrateur permettant le déploiement de services sur un cluster de plusieurs machines hôtes appelées nœuds. Docker Swarm est adapté pour les besoins de production.
- Fichier docker-compose.yml : bien que Docker fournisse des commandes nécessaires pour déployer directement des services, ceux-ci peuvent également être définis dans un fichier de configuration
docker-compose.ymlqui reprend la définition de ses images, réseaux, volumes, options d’environnement… nécessaires au déploiement. Il devient alors possible de lancer tous les services en une seule commande avec Docker Compose. Ces fichiersdocker-compose.ymlsont également utilisés pour déployer les services sur un cluster Docker Swarm. - Nœud : hôte d’un cluster Docker Swarm. On distingue deux types de nœuds dans un cluster :
- les managers permettent la gestion du cluster (déploiement des services, états des ressources, création de volumes…),
- les workers exécutent les conteneurs des services.
- Registry et Hub : les images Docker une fois construites peuvent être publiées dans un Registry afin d’économiser du temps lors des déploiements. Le Hub est un Registry public regroupant des images pré-construites et téléchargeables par le Docker Engine.
- RAFT : algorithme utilisé entre les noeuds managers d’un Swarm afin d'arriver à un consensus. Cet algorithme contraint le nombre de nœuds managers nécessaires à garantir l'obtention du consensus en cas de crash de l’un d’entre eux.
Fichier Dockefile
Voici un exemple de fichier Dockerfile permettant de construire une image d'environnement d'exécution PHP :
FROM phpdockerio/php72-fpm:latest
WORKDIR /application
# Fix debconf warnings upon build
ARG DEBIAN_FRONTEND=noninteractive
# Install selected extensions and other stuff
RUN apt-get update \
&& apt-get -y --no-install-recommends install php-memcached php7.2-mysql php-redis php-xdebug php7.2-bcmath php7.2-gd php7.2-intl php7.2-soap php-yaml \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
# Install git
RUN apt-get update \
&& apt-get -y install git \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
Fichier Docker Compose
Voici un exemple de fichier docker-compose.yml définissant les services nécessaires à l'exécution d'une stack PHP simple composée de 3 services (memcached, webserver et php-fpm) :
version: "3.1"
services:
memcached:
image: memcached:alpine
webserver:
image: nginx:alpine
working_dir: /application
volumes:
- .:/application
- ./phpdocker/nginx/nginx.conf:/etc/nginx/conf.d/default.conf
ports:
- "8084:80"
php-fpm:
build: phpdocker/php-fpm
working_dir: /application
volumes:
- .:/application
- ./phpdocker/php-fpm/php-ini-overrides.ini:/etc/php/7.3/fpm/conf.d/99-overrides.ini
Cette stack peut être déployée localement avec docker-compose ou sur un cluster avec les commandes docker stack du mode swarm de Docker.
Docker et les pratiques Agile et DevOps
Docker, en particulier via des outils comme Docker Compose, est un outil facilitant la mise en place des approches DevOps et Agile de plusieurs manières.
En voici quelques-unes :
- Docker permet d’effectuer la gestion de l’infrastructure comme de la gestion de code. En effet, les fichiers de déploiement docker-compose.yml ou les Dockerfile peuvent être gérés et versionnés dans un outil de partage de code source tel que git. De plus, les opérations sur le Registry utilise un vocabulaire proche de celui des systèmes de gestion de code source (
push,pull,commit). - A travers la gestion des volumes et des fichiers de variables d’environnement, Docker facilite également la gestion des configurations comme du code.
- Docker permet de mettre en place l'intégration continue en facilitant l'automatisation des tests et de la validation par le déploiement d’environnements d’exécution. En poussant cette logique jusqu’au bout, l’infrastructure elle-même pourrait être testée et validée de manière automatique.
- En automatisant la création des environnements d’exécution, Docker permet la mise en place de la livraison et/ou du déploiement continu des applications.
- Les architectures en micro-services permettent également de limiter les risques lors de la mise en production d’une nouvelle version de l’application et limitant les changements sur l’infrastructure à ce qui a été effectivement modifié et en permettant un retour en arrière en cas de problème (via le système de Registry).
- Docker permet le mise à jour « à chaud » des conteneurs en cours d’exécution et facilite donc la mise à jour des piles applicatives.
Note : Ajoutons à cela que des solutions de CI/CD telles que Gitlab-CI s'intègre très simplement dans un environnement Docker et que Gitlab lui-même propose un repository d'images Docker intégré.
Quelles solutions pour un cluster avec Docker ?
Une solution simple pour déployer des stacks de services avec Docker est d’utiliser Docker Compose. Toutefois, même si elle permet de gérer la réplication des services, cette solution ne fonctionne que sur une seule machine hôte et ne permet donc pas d’assurer un fail-over en cas de crash de la machine hôte ou une répartition de charge sur plusieurs hôtes. Cette solution ne peut donc s’appliquer qu’à l’hébergement d’applications non critiques.
Au niveau des solutions permettant la mise en place d’un cluster d’hôte pour héberger des services basés sur le moteur Docker, la situation a beaucoup évolué ces derniers mois.
Jusqu’en 2020, l’écosystème des solutions à base de conteneurs proposait de nombreuses solutions de gestion et d’orchestration de cluster Docker :
- Docker Swarm : orchestrateur intégré à Docker et utilisant le même format de fichier de configuration de services que docker-compose
- Mesos : orchestrateur basé sur DC/OS de la Apache Foundation et plutôt destiné au calcul scientifique ou aux applications ayant un temps d’exécution de tâches assez long
- Kubernetes : orchestrateur supportant différents types de conteneurs maintenu par la Linux Foundation et sans doute la solution la plus utilisée à ce jour.
- Rancher : solution d’orchestration commerciale bâtie au-dessus d’une implémentation légère de Kubernetes (RKT) rachetée par SUSE
- Microk8s : solution d’orchestration légère et performante compatible avec Kubernetes, Microk8s est développé et maintenu par Canonical et optimisé pour des hôtes Ubuntu
Il existe également des solutions orientées vers la gestion complète d'une infrastructure de cloud telles que
- OpenShift : solution développée par RedHat et construite au-dessus de Kubernetes et de CoreOS.
- Ksphere : solution développée par D2iQ inc., basée sur Kubernetes et plutôt orientée vers le calcul scientifique.
- Mesosphere/Marathon : solution développée par D2iQ inc., basée sur Apache Mesos (ou Kubernetes) et plutôt orientée vers le calcul scientifique.
A cela s’ajoute des solutions liées à des clouds propriétaires :
- Amazon ECS pour le cloud Amazon EC2
- Azure Container Service pour le cloud Azure
- Google Container Engine pour le cloud Google
Toutefois, l’annonce de l’abandon de Dockershim (la couche permettant l'utilisation de Docker comme environnement d'exécution) dans Kubernetes fin 20207 a créé une certaine panique et a changé ce paysage. Depuis sa version 1.24 sortie en 2022, Kubernetes utilise directement containerd sans passer par Docker8.
Cette décision a donc créé deux écosystèmes différents, avec d'un côté les solutions compatibles avec Docker et de l'autre celles qui ont pris la même direction que Kubernetes. Il faudra sans doute encore attendre quelques mois voire quelques années pour voir quelles seront les conséquences de cette situation.
Solution choisie dans le cadre de ce projet
Le cœur de ce brevet est construit autour de la mise en place d’une infrastructure basée sur Docker Swarm.
Pourquoi ce choix ? Simplement par Docker Swarm est intégré à Docker qui était, au moment du démarrage de ce projet, le moteur de conteneur le plus populaire et ayant, de ce fait, la plus grande communauté et le plus de documentation disponible en ligne. De plus, Docker Swarm utilise des fichiers de déploiement de stack identiques à ceux de Docker Compose, lui-même utilisé pour de nombreuses applications. Cela permet d’écrire des fichiers de déploiement Docker Swarm pour de nombreuses applications et avec un minimum de travail d’adaptation.
Toutefois, je discuterai d’autres solutions dans la section consacrée aux perspectives plus loin dans le présent document.
Ajoutons à cela que l’infrastructure que je mets en place est destinée à des applications métier relativement modestes développées au sein des services informatiques.
Pour une infrastructure plutôt orientée vers l’hébergement d’applications web à destination d’un plus large public, une autre infrastructure, voire l’utilisation d’une solution plus complète comme OpenShift, pourrait être envisagée. Cette situation sort toutefois du propos de ce brevet, mais elle sera évoquée dans la section consacrée aux perspectives.
Docker Compose
Docker Compose est un orchestrateur pour Docker destiné à gérer des piles applicatives sur un seul noeud hôte.
Il peut être utilisé pour :
- déployer des services sur une infrastructure à un seul nœud
- développer et tester des applications déployées via Docker sur sa machine locale
- construire et tester des images Docker
Docker Compose fournit un format de déclaration de pile applicative commun avec Docker Swarm.
Docker Swarm
Swarm est un mode d’exécution intégré au Docker Engine pour l’orchestration d’un cluster.
Le mode swarm permet :
- la gestion d’un cluster
- la déclaration et le déploiement de services sur le cluster
- le scaling des applications sur le cluster
- la communication réseau entre les hôtes du cluster
- la répartition de charge entre les nœuds du cluster
- la mise à jour des services
Pourquoi choisir Docker Swarm ? Parce que Docker Swarm Rocks !.
Voici les raisons principales qui m'ont amené à choisir cette outil :
- Docker Swarm est intégré à Docker formant une suite complète : Docker comme moteur d'exécution de conteneurs, Docker Compose comme outil de développement et le mode Swarm pour déployer et gérer les applications en production
- Docker Swarm permet de créer un cluster d'une seule machine et de lui adjoindre des machines supplémentaires si nécessaire alors que la plupart des autres systèmes requièrent une machine d'orchestration séparée des autres nœuds du cluster
- Docker Swarm permet de mettre en place plusieurs nœuds manager
- Très simple à comprendre et à utiliser, le mode Swarm est entièrement basé sur le moteur Docker et ne requiert pas d'apprendre de nouveaux concepts
- Mettre en place un cluster prêt pour la production est très rapide environ 2h tout compris (c'est à dire y compris l'installation et la configuration des VM) pour un cluster de 5 machines; le mode swarm lui-même ne prend que 20 minutes pour sa mise en place !
Note : Le mode Swarm de Docker est basé sur le projet open source Swarmkit9.
Noeuds en mode swarm
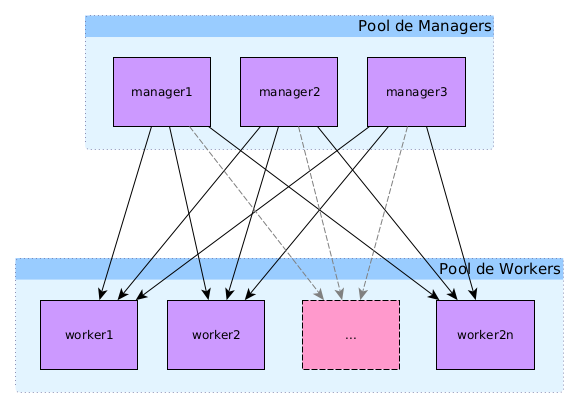
Dans un cluster en mode swarm, il existe deux types de nœuds10 : manager et worker.
Les nœuds de type manager en charge de maintenir l'état du cluster, planifier les services et servir de point d’entrée à l’API REST de docker. Les managers se basent sur l’algorithme de consensus distribué RAFT pour gérer l’état global du cluster
Les nœuds de type worker en charge d’exécuter les conteneurs et services à la demande des nœuds manager.
Note :
- Les commandes
docker node [COMMAND] [OPTIONS]permettent de gérer les nœuds du swarm.- Il est possible de changer le rôle d’un nœud avec les commandes
docker node promoteetdocker node demote.- Il est possible d’exclure un manager des nœuds disponibles pour le déploiement de service du swarm en mettant sa disponibilité à la valeur
Drainvia la commandedocker node update.
Un cluster Docker Swarm, ou plus simplement swarm, est constitué de plusieurs noeud pouvant exercer le rôle de manager ou de worker (ou les deux). Le rôle des managers est de maintenir l'état du swarm. Celui des workers est d'exécuter les tâches des différents services ou les containers "standalone".
Le swarm le plus simple est un swarm d'une seule machine qui tiendra à la fois le rôle de manager et de worker. A ce nœud, on peut ajouter des noeuds supplémentaires nœuds qui pourront également prendre le rôle de manager et/ou de worker.
Toutefois une telle infrastructure ne permet pas d'avoir de la redondance ou de la répartition de charge entre plusieurs machines, et ne convient donc pas à une infrastructure de production. Un swarm sera donc généralement constitué de plusieurs nœuds.
Dans une telle infrastructure à plusieurs nœuds, au moins un des nœuds devra tenir le rôle de manager (le nombre de manager doit obligatoirement être impair), les autres seront les workers.
Quelques remarques importantes concernant le mode swarm
Nœuds uniquement manager
Il est déconseillé (mais pas interdit) qu'un nœud joue à la fois le rôle de manager et de worker. Pour rendre un nœud "manager only" (c'est à dire qu'il ne pourra pas exécuter les tâches des services), il suffit d'exécuter la commande docker node update --availability drain <NODE>.
Remarque : Cette option ne sera pas implémentée dans les swarms présentés ici afin de permettre le déploiement de services sur les managers également (par exemple pour les applications portainer et swarmpit).
Redondance et consensus
Afin d'assurer une redondance des managers, il est possible d'ajouter d'autres manager au swarm. Toutefois,le nombre de manager doit être impérativement impair afin de garantir le consensus sur l'état du swarm lors de la perte d'un des managers.
En particulier, les managers vont élire un Leader parmi eux via le système de consensus RAFT11 12. Celui-ci sera la référence pour l'état du swarm. S'il devient indisponible, les autres managers éliront un nouveau Leader parmi eux.
Typiquement, le nombre de manager sera de 1, 3 ou 5. Au-delà de 5, les performances du swarm risquent de diminuer à cause de la communication nécessaire entre les managers et il est déconseillé de dépasser 7 managers pour un cluster.
Redondance et distribution des managers
Docker Swarm supporte la perte de (N - 1) / 2 managers, où N est le nombre de managers. Il est donc fortement conseillé que chaque manager se trouve isolé dans un data center différent des autres managers, ceci afin d'éviter que la perte d'un data center contenant plus de (N - 1) / 2 managers ne provoque la perte du consensus sur l'état du swarm. Comme on peut le voir dns le tableau ci-dessous, afin de garantir le fonctionnement optimal du cluster et supporter la perte d'un des managers, le nombre minimum de manager est de 3.
| Nombre de managers | Nombre de managers nécessaires pour garantir le quorum | Nombre de managers pouvant être perdus | Répartition (2 zones) | Répartition (avec 3 zones) |
|---|---|---|---|---|
| 1 | 1 | 0 | 1-0 | 1-0-0 |
| 2 | 2 | 0 | ||
| 3 | 2 | 1 | 2-1 | 1-1-1 |
| 4 | 3 | 1 | ||
| 5 | 3 | 2 | 3-2 | 2-2-1 |
| 6 | 4 | 2 | ||
| 7 | 4 | 3 | 4-3 | 3-2-2 |
| 8 | 4 | 3 | 4-4 | 3-3-2 |
| 9 | 5 | 4 | 5-4 | 3-3-3 |
Note :
- Avec 2 managers, le swarm peut parfaitement fonctionner tant qu'il ne faut pas (ré-)élire un leader entre ceux-ci.
- L'infrastructure fournie par SIPR n'a que 2 data centers et ne permet donc pas de résoudre ce problème actuellement. Une piste envisagée serait d'étendre le réseau des data centers jusque Woluwé afin de placer un manager là-bas. Une autre option, mais moins pratique, pourrait être de placer un des managers hors des data centers.
- Mon infrastructure de démonstration ne comprend qu'un seul manager. Il serait très simple de remédier à cette situation en convertissant les 2 workers en managers. Je ne l'ai pas fait à ce stade afin de pouvoir effectuer des tests de déploiement basés sur le rôle des noeuds dans le swarm, mais cela pourrait être fait une production. Une autre option serait simplement d'ajouter deux nouveaux noeuds managers au swarm.
Plus d'informations ainsi que les instructions pour un "disaster recovery" ou en cas de perte du quorum (par exemple lors de la perte de plus de (N-1) / 2 managers) peuvent être trouvées dans le guide d'administration de Docker Swarm : https://docs.docker.com/engine/swarm/admin_guide/
Les infrastructures du portail
L'infrastructure de formation du portail est un exemple de swarm constitué d'un seul nœud qui joue à la fois le rôle de manager et de worker.
L'infrastructure de développement du portail est un exemple d'un swarm avec 1 un seul manager et 2 workers.
Dans le cas des infrastructures de production et de QA du portail, le Swarm est constitué de 3 managers et d'un nombre variables de D*n workers où D est le nombre de data centers dans lequel les nœuds sont déployés et n le nombre de nœuds redondants. Pour les infrastructures du portail, à l'état initial, pour QA n = 1, pour la production n = 3 répartis entre les 2 data centers (D = 2 ). Ce qui nous donne respectivement un total de 5 noeuds (3 managers et 2 workers) pour la QA et 9 pour la production (3 managers et 6 workers).
Gérer les noeuds
Voici quelques commandes de gestion d'un Swarm Docker :
- Sortir un noeud worker (sur le worker à sortir) :
docker swarm leave - Rejoindre le swarm comme worker :
- sur le manager :
docker swarm join-token worker(copier la commande obtenue) - sur le worker :
docker swarm join --token <TOKEN> 10.1.4.63:2377(coller la commandede l'étape précédente)
- sur le manager :
- Lister les noeuds du swarm (sur le manager):
docker node ls - Supprimer un noeud fantôme (sur le manager) :
docker node rm <ID>
Services en mode swarm
Le déploiement d’application en mode swarm se fait en créant des services13. Pour cela, on peut utiliser soit la commande docker service create [OPTIONS], soit des fichiers de configuration de services docker-compose.
Chaque service est l’image d’un microservice d’une application. Il peut s’agir, par exemple, d’un serveur web nginx, d’un environnement d’exécution php ou d’une base de données.
Chaque service nécessite la définition d’une image Docker et de la commande à exécuter dans cette image. On peut aussi spécifier pour chaque service les ports exposés, le réseau à utiliser pour communiquer avec d’autres services du Swarm, des ressources CPU ou mémoire allouées, le nombre de répliques (replicas dans le vocabulaire de Docker)…
Pour chaque service, le manager va planifier (schedule) une tâche par réplique du service, chaque tâche exécutant un conteneur.
Chaque nœud manager est composé
- d'un orchestrateur qui crée les tâches
- d'un allocateur d’adresse IP
- d'un dispatcheur qui assigne les tâches aux différents nœuds
- d'un planificateur (scheduler) qui lance l’exécution des tâches
Chaque nœud worker comprend le worker proprement dit qui va chercher les tâches qui lui sont assignées auprès du dispatcheur et d’un exécuteur qui exécute les tâches proprement dites.
Les services peuvent être répliqués sur 1 ou plusieurs nœuds, c’est-à-dire qu’il exécutera une tâche sur chacun de ces nœuds. Un service global sera répliqué sur tous les nœuds du swarm.
Déploiement et gestion d’un cluster en mode swarm
La mise en place d’un cluster en mode swarm est assez simple14 :
- Déployer les hôtes du cluster (des machines Linux)
- Installer Docker sur les hôtes
- Ouvrir les ports nécessaires à Docker
- Initialiser le cluster sur le nœud manager
docker swarm init [OPTIONS] - Exécuter la commande pour rejoindre le cluster sur les nœuds workers
docker swarm join [OPTIONS]
Une fois ces opérations effectuées, il est alors possible de gérer les services sur le cluster a l'aide des commandes docker service [COMMAND] [OPTIONS] ou de gérer les stacks avec les commandes docker stack [COMMAND] [OPTIONS].
Les étapes du déploiement seront décrites en détail dans la section suivante « Infrastructure de démonstration basée sur Docker Swarm »
Mise à jour des services à chaud
Les services d’une stack peuvent être facilement mis à jour à chaud, par exemple lors d’un changement dans les fichiers de configuration du service.
Prenons comme exemple la modification de la configuration de nginx dans une stack constituée de 3 services : mariadb, php-fpm et nginx.
La première étape consiste à obtenir l’id du service à mettre à jour via la commande docker stack services STACK_NAME :
~$ docker stack services fminne73
ID NAME MODE REPLICAS IMAGE PORTS
cn1jy6ixuy09 fminne73_database replicated 1/1 mariadb/server:latest
iwsqg4zp3i4m fminne73_php-fpm replicated 1/1 dkm-webapps.sipr-dc.ucl.ac.be:5000/drupal_phpfpm73:latest
tb1pfcxly9ea fminne73_webserver replicated 1/1 dkm-webapps.sipr-dc.ucl.ac.be:5000/drupal_webserver:latest
La mise à jour s’effectue alors à l’aide de la commande docker service update [OPTIONS] SERVICE_ID :
~$ docker service update --force tb1pfcxly9ea
tb1pfcxly9ea
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
L’option --force est employée pour forcer le rechargement du service.
Il est également possible de mettre à jour l'image utilisée par un service via la commande docker service update --image SERVICE_ID.
Swarm Routing Mesh et résolution de noms
Docker intègre son propre mécanisme de routing pour joindre les conteneurs quel que soit le noeud sur lequel ils sont déployés. Ce mécanisme appelé Routing Mesh15 est mis en place à travers la définition d'un réseau spécifique, le réseau Ingress.
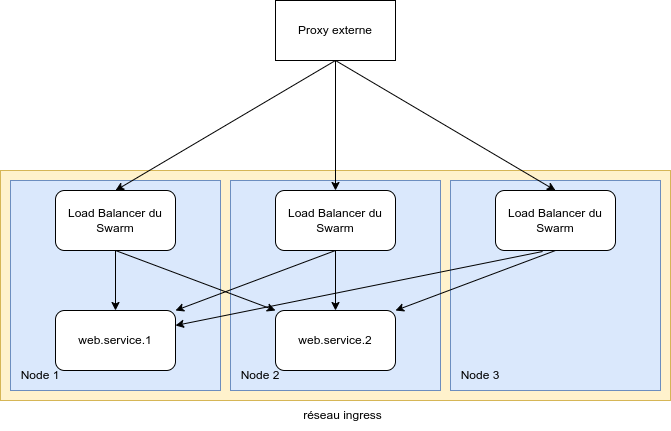
Toute requête adressée sur un port d'un noeud du Swarm sera résolue via ce mécanisme qui intègre un mécanisme de répartition de charge. Il n'est donc pas garanti que le conteneur qui va traiter la requête se trouve sur le noeud qui a reçu la requête.
En plus de ce mécanisme, Docker intègre un système de resolution de nom qui permet joindre n'importe quel service sur base du nom qui lui a été donné lors de son déploiement. Toute requête à ce service passera également par le mécanisme de répartition de charge intégré à Docker Swarm.
Wikipedia OS-level virtualization https://en.wikipedia.org/wiki/OS-level_virtualization
« Difference between Docker and Vagrant » https://www.quora.com/What-is-the-difference-between-Docker-and-Vagrant-When-should-you-use-each-one
Il existe 2 types d’hyperviseur le type 1 (Xen, KVM) s'exécute directement sur une machine physique (hardware), le type 2 (QEMU, VirtualBox, VMware) s'exécute sur un système d’exploitation hôte.
Par opposition à une infrastructure monolithique dans laquelle tous les services d’une application (serveur web, base de données, environnement d’exécution…) sont déployés sur un seul système, les architectures micro-services isolent chaque service dans un conteneur séparé et indépendant, facilitant ainsi leur maintenance (mise à jour, replacement…)
Au départ Docker se basait sur LXC avant de passer à sa propre implémentation : runC.
runc is a CLI tool for spawning and running containers according to the OCI specification https://github.com/opencontainers/runc
Kubernetes Blog « Don't Panic: Kubernetes and Docker » https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/
« Kubernetes is Moving on From Dockershim: Commitments and Next Steps » https://kubernetes.io/blog/2022/01/07/kubernetes-is-moving-on-from-dockershim/
« Swarmkit, a toolkit for orchestrating distributed systems at any scale » https://github.com/docker/swarmkit/
« How nodes work » https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/
« Pour une explication détaillée du consensus Raft » http://thesecretlivesofdata.com/raft/ et https://raft.github.io/
« Raft consensus in swarm mode » https://docs.docker.com/engine/swarm/raft/
« How services work » https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/
« Getting started with swarm mode » https://docs.docker.com/engine/swarm/swarm-tutorial/
Use swarm mode routing mesh https://docs.docker.com/engine/swarm/ingress/
Mise en place d'une infrastructure de démonstration
- Introduction
- Infrastructure à déployer
- Setup inital
- Installation et configuration de Docker
- Déploiement du cluster Docker Swarm
- Système de fichier
- Reverse proxy en entrée du cluster
Introduction
La mise en place de mon infrastructure de démonstration s'est réalisée en plusieurs phases :
- 2018-2019 : mise en place d’une première infrastructure de démonstration et de développement pour le portail UCLouvain
- janvier 2022 : passage en production de l’infrastructure Docker Elastic Search des bibliothèques basée sur cette première infrastructure de démonstration
- avril 2022 : mise en place d’une nouvelle infrastructure de démonstration afin de tenir compte des évolutions de Docker depuis 2019
- juin 2022 : dérivation de l’infrastructure dckr.sisg pour les besoins de production du nouveau portail UCLouvain
L’objectif était d’expérimenter les possibilités de Docker et d’étudier son adéquation avec les besoins des futures infrastructures web, en profitant des opportunités offertes par le développement du nouveau portail UCLouvain.
Infrastructure à déployer
L’infrastructure à déployer mettra à disposition un swarm Docker pour héberger des applications web.
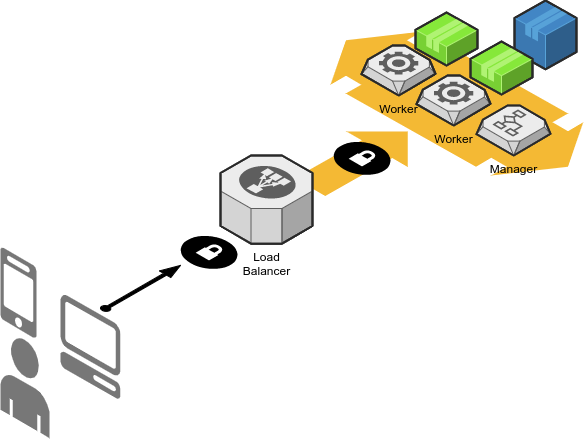
Éléments constitutifs de l'infrastructure :
- Pool de managers : machines qui assurent la gestion du swarm et servent les applications de gestion, de monitoring…
- Pool de workers : machines qui servent les applications exécutées sur le swarm
À cela s'ajoute le load balancer/Proxy (géré par SIPR) qui permet la répartition de charge entre les machines du swarm, redirige les requêtes sur les bonnes machines en fonction du fqdn et assure également la liaison sécurisée https avec les machines clientes
Dimensionnement des machines virtuelles et points de montage
Il y a 3 machines virtuelles pour mon infrastructure.
Voici leur spécification technique.
Manager (1 machine)
- 4 coeurs
- RAM 16G
- Disques :
- / 20G
- /home 20G
- /dockerdata-ceph 40G
- /var/lib/docker 40G
- /var/lib/docker.bk 10G
- OS : Debian 11
- Doit pouvoir faire des requêtes vers l'extérieur sur les ports
- 80, 443 (git vers github)
- 22 (git via ssh sur gitlab.sisg.ucl.ac.be et forge.uclouvain.be)
- 11371 (key server)
Notes :
- Le point de montage
/dockerdata-cephest destiné à contenir les fichiers partagés entre les services déployés sur l'infrastructure et qui seront montés en tant que volumes. Ces données devront être disponibles sur tous les noeuds du cluster et seront dès lors exportées depuis le manager via NFS.- Le point de montage
/var/lib/dockerest destiné au stockage des données propres à Docker- L'usage a montré que le répertoire
/var/lib/docker.bkpouvait grandir rapidement et consommer de l'espace sur le système de fichier racine de la machine. J'ai donc décidé de l'externaliser via un point de montage séparé.- Le choix de Debian 11 était le choix fait à l'origine, mais il n'est en rien obligatoire. Les étapes décrites dans ce chapitre fonctionnent sur n'importe qu'elle distribution basée sur Debian (par exemple Ubuntu) et, avec un peu d'adaptation, sur n'importe quelle distribution Linux. Pour des infrastructures plus récentes, j'ai tendance à lui préférer Ubuntu dans sa dernière version LTS (la 22.04 au moment d'écrire ce texte) qui offre une plus grande stabilité et des paquets plus régulièrement mis à jour que Debian.
Workers (2 machines)
- 4 coeurs
- RAM 16G
- Disques :
- / 20G
- /home 20G
- /var/lib/docker 40G
- /var/lib/docker.bk 10G
- OS : Debian 11
- Doivent pouvoir faire des requêtes vers l'extérieur sur les ports
- 80, 443
Setup inital
Voici les étapes préliminaires nécessaires avant de pouvoir installer Docker sur les machines virtuelles.
Génération de la locale fr_BE.UTF-8
Sur les machines Debian 11 fournies par SIPR, la locale par défaut fr_BE.UTF-8 n'est pas générée. Cela provoque l'affichage d'avertissements lors de l'exécution de nombreuses commandes.
Pour y remédier, il suffit de générer cette locale :
sudo dpkg-reconfigure locales
# Sélectionner fr_BE.UTF-8 dans la liste (avec flèches pour naviguer puis espace pour sélectionner)
# Sélectionner fr_BE.UTF-8 comme locale par défaut (avec flèches pour naviguer puis espace pour sélectionner)
# Choisir OK pour générer les locales
Note : l'idéal serait que la locale
fr_BE.UTF-8soit intégrée dans les templates des images Debian de SIPR.
Configuration du proxy (optionnel)
Si les machines ne sont pas sur le bon gateway, ou si elles ne sont pas encore autorisées à sortir sur les ports nécessaires sur le load balancer HAProxy de SIPR, il peut être nécessaire de configurer le passage par le proxy HTTP(S) des Data Center afin d'accéder à l'Internet et pouvoir installer les paquets requis. Ce proxy doit être configuré pour différentes applications.
Note : Attention toutefois que pour l'utilisation de Docker, les machines devront être capables de faire des requêtes vers l'extérieur sur les ports 22 et 11371 qui ne sont pas pris en charge par le proxy du Data Center. Configurer le proxy HTTP(S) permet toutefois l'installation des paquets nécessaires sur les machines en attendant que la configuration sur le load balancer HAProxy de SIPR soit terminée.
Apt (normalement pas nécessaire)
Normalement le proxy est déjà configuré pour le gestionnaire de paquets apt dans les images Debian 11 de SIPR.
Pour le vérifier :
cat /etc/apt/apt.conf.d/01proxy
# Doit contenir les lignes suivantes :
# Acquire::http::Proxy "http://proxy.sipr.ucl.ac.be:889/";
# Acquire::https::Proxy "http://proxy.sipr.ucl.ac.be:889/";
Si ce n'est pas le cas, il suffit de créer le fichier /etc/apt/apt.conf.d/01proxy :
# vim /etc/apt/apt.conf.d/01proxy
Acquire::http::Proxy "http://proxy.sipr.ucl.ac.be:889/";
Acquire::https::Proxy "http://proxy.sipr.ucl.ac.be:889/";
Wget
Contrairement à curl qui utilise les variables d’environnement pour le proxy, wget utilise sa propre configuration. Il faut ajouter le proxy au fichier /etc/wgetrc.
Les wildcards n'étant pas supportées par la configuratuion, il est nécessaire de scripter l'ajout des IP de machine du sous-réseau de mon infrastructure echo 10.1.4.{1..255},.
# vim /etc/wgetrc
https_proxy = http://proxy.sipr.ucl.ac.be:889/
http_proxy = http://proxy.sipr.ucl.ac.be:889/
no_proxy = `echo 10.1.4.{1..255},`localhost,127.0.0.1,.sipr-dc.ucl.ac.be
Bash
Les wildcards n'étant pas supportées par Bash, il est nécessaire de scripter l'ajout des IP de machine du sous-réseau de mon infrastructure echo 10.1.4.{1..255},.
vim ~/.bashrc
# ajouter les lignes suivantes à la fin du fichier :
export http_proxy='proxy.sipr.ucl.ac.be:889'
export https_proxy='proxy.sipr.ucl.ac.be:889'
export no_proxy=`echo 10.1.4.{1..255},`localhost,127.0.0.1,.sipr-dc.ucl.ac.be
# recharger le fichier .bashrc
. ~/.bashrc
Installation des paquets de base
Installation des paquets requis pour la suite des opérations.
# Mise à jour de la liste des paquets
sudo apt update
# Mise à jour de paquets déjà installés
sudo apt upgrade
# Installation des nouveaux paquets
sudo apt install \
ca-certificates \
gnupg \
lsb-release \
vim \
htop \
ansible \
git
Configuration du proxy pour git
Il reste encore à configurer git pour utiliser le proxy
# Soit de manière globale
git config --global http.proxy http://proxy.sipr.ucl.ac.be:889
# Soit pour le projet courant uniquement
git config http.proxy http://proxy.sipr.ucl.ac.be:889
Ajouts des groupes "admin"
Par facilité, on peut ajouter l'utilisateur courant, ainsi que les autres utilisateurs amenés à gérer la machine, aux groupes adm et staff afin d'éviter de devoir utiliser sudo pour certaines actions. Le groupe adm donne accès aux logs, le groupe staff permet de modifier le contenu du répertoire /usr/local
# Accès aux logs
sudo usermod -aG adm $USER
# Accès à /usr/local
sudo usermod -aG staff $USER
Il faudra se déconnecter et se reconnecter à la session pour que cela soit actif ou utiliser la commande newgrp.
Installation et configuration de Docker
Cette section constitue un mode d’emploi pour la mise en place d’une infrastructure Docker, Certaines opérations sont à réaliser sur tous les types de noeuds du cluster alors que certaines sont spécifiques aux noeuds managers ou workers.
Installation de l'environnement Docker (tous les nœuds)
La procédure d'installation des paquets de Docker est simplement celle décrite sur le site officiel :
# Suppression des versions précédentes de Docker
sudo apt remove docker docker-engine docker.io containerd runc
# Obtention de la clé GPG du dépôt des paquets de Docker
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
# Ajout du dépôt
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Mise à jour de la liste des paquets
sudo apt update
# Installation des paquets Docker
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin
Configuration de Docker (tous les nœuds)
Une fois Docker installé, il reste à le configurer correctement.
Créer un fichier pour systemctl
Par défaut, Docker se lance avec une série d'options que je veux modifier dans mon infrastructure. De plus j'aimerais fournir une partie de ces options via le fichier /etc/docker/daemon.json. Or certaines de ces options risques d'entrer en conflit avec les options par défaut de Docker et le daemon refusera de se lancer.
Pour contourner ce problème, il suffit de modifier les options par défaut passées au service Docker par systemd.
Cela se fait relativement simplement en créant un fichier d'override de configuration pour le service docker.service dans lequel je vais retirer toutes les options passées au daemon Docker (puisqu'elles seront définies dans mon fichier daemon.json). Cela peut se faire soit à la main, soit en utilisant systemctl, l'outil de gestion de systemd.
À la main
sudo mkdir -p /etc/systemd/system/docker.service.d
Ajouter le fichier docker.conf :
# vim /etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd
Avec systemctl
sudo systemctl edit docker.service
Ajouter le code suivant dans la zone prévue en début de fichier :
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd
Configurer Docker via daemon.json
Configuration de base dans daemon.json, sudo vim /etc/docker/daemon.json :
{
"storage-driver": "overlay2",
"log-driver": "local",
"debug": false
}
Note : Les options du driver local pour les logs sont décrites dans la documentation de Docker
Activer l'accès à l'API du daemon Docker via tcp
Deux ports sont possibles : 2375 (HTTP uniquement) ou 2376 (HTTP avec ou sans TLS).
Dans /etc/docker/daemon.json ajouter la configuration des sockets pour dockerd :
{
/* ... */
hosts: ["unix:///var/run/docker.sock", "tcp://0.0.0.0:2376"]
}
Notes :
- L'utilisation de
tcp://0.0.0.0:2376n'est en théorie pas sécurisée car elle permet à n'importe quelle machine de parler au daemon Docker. Néanmoins, dans le cadre de mon infrastructure, cela ne pose pas de problème, puisqu’il est facile de limiter les accès aux machines du cluster elles-mêmes via des règles de firewall. j’ajouterais également, que le port 2376 n'étant accessible que via le VLAN des noeuds Docker, les risques sont assez réduits surtout en comparaison de la simplification qu'ils permettent dans la gestion du cluster.- Je n'ai pas activé le TLS sur le port 2376 à ce stade et ce principalement pour 2 raisons : il n'est pas nécessaire pour les raisons citées plus haut (VLAN + firewall), il requiert un certificat pour lequel il me semble préférable d'attendre qu'une CA "interne" aux Data Center SIPR soit disponible (l'alternative étant un certificat auto-signé).
Configurer un registry non sécurisé
Par défaut, Docker refuse d'utiliser un registry qui ne serait pas accessible via HTTPS. Il est toutefois possible de définir des regitries non sécurisés directement dans la configuration du daemon.
Dans /etc/docker/daemon.json ajouter la configuration du registry (l'installation du registry est décrite plus loin) :
{
/* ... */
"insecure-registries" : [ "private-registry:5000" ]
}
Configurer les métriques pour le monitoring
Dans /etc/docker/daemon.json ajouter la configuration pour l'accès aux métriques via une API REST. Cet accès sera nécessaire pour la mise en place du monitoring :
{
/* ... */
"metrics-addr" : "127.0.0.1:9323",
"experimental" : true,
/* ... */
}
Note : la question du monitoring sera abordée dans le chapitre Perspectives
Mon fichier daemon.json complet
Voici le fichier daemon.json complet :
{
"storage-driver": "overlay2",
"log-driver": "local",
"debug": false,
"metrics-addr" : "127.0.0.1:9323",
"experimental" : true,
"insecure-registries" : [ "private-registry:5000" ],
"hosts": ["unix:///var/run/docker.sock", "tcp://0.0.0.0:2376"]
}
Relancer le daemon Docker
Recharger la configuration de systemd sudo systemctl daemon-reload et relancer docker sudo systemctl restart docker.
Puis relancer Docker : sudo systemctl restart docker
Configurer le proxy (optionnel)
Note : ces étapes ne sont nécessaires que si les machines n'ont pas un accès direct vers l'extérieur sur les ports 80 et 443. Cela ne suffira toutefois pas pour pouvoir construire certaines images Docker qui nécessite soit un accès aux serveurs de clés publiques via le port 11371 ou un accès à git via ssh (port 22).
Options de Docker
sudo vim /etc/default/docker:# Docker Upstart and SysVinit configuration file # # THIS FILE DOES NOT APPLY TO SYSTEMD # # Please see the documentation for "systemd drop-ins": # https://docs.docker.com/engine/admin/systemd/ # # Customize location of Docker binary (especially for development testing). #DOCKERD="/usr/local/bin/dockerd" # Use DOCKER_OPTS to modify the daemon startup options. #DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4" DOCKER_OPTS="--config-file=/etc/docker/daemon.json" # If you need Docker to use an HTTP proxy, it can also be specified here. export http_proxy="http://proxy.sipr.ucl.ac.be:889 export https_proxy="http://proxy.sipr.ucl.ac.be:889 export no_proxy=`echo 10.1.4.{1..255},`,localhost,127.0.0.1,.sipr-dc.ucl.ac.be # This is also a handy place to tweak where Docker's temporary files go. #export DOCKER_TMPDIR="/mnt/bigdrive/docker-tmp"Créer le répertoire de configuration de Docker pour systemd
sudo mkdir /etc/systemd/system/docker.service.dCréer le fichier de configuration du proxy
/etc/systemd/system/docker.service.d/http_proxy.conf[Service] # NO_PROXY is optional and can be removed if not needed Environment="HTTP_PROXY=http://proxy.sipr.ucl.ac.be:889" "HTTPS_PROXY=http://proxy.sipr.ucl.ac.be:889" "NO_PROXY=localhost,127.0.0.0/8,10.1.4.1/24,*.sipr-dc.ucl.ac.be"Recharger les configurations de systemd via
sudo systemctl daemon-reloadVérifier que les options sont bien prises en compte
sudo systemctl show docker --property EnvironmentRedémarrer docker :
sudo systemctl restart docker
Ajout de l'utilisateur courant au groupe Docker (tous les nœuds)
Par facilité, on ajoute l'utilisateur courant au groupe docker afin d'éviter d'avoir à utiliser sudo pour exécuter les commandes Docker :
# Ajout de l'utilisateur au groupe docker
sudo usermod -aG docker $USER
Pour appliquer ce changement, il reste alors à recharger la session, soit en quittant et en se reconnectant, soit via la commande newgrp :
# Rechargement de la session pour tenir compte du changement
newgrp docker
Note :
newgrplance une nouvelle session du shell au sein de la session actuelle. Il faudra donc utiliser la commandeexitdeux fois pour quitter la session.
Installation de Docker Compose (managers uniquement)
L'outil Docker Compose nous permettra d'effectuer le build des images Docker sur le manager. Il permettra également de déployer des stacks localement sur les managers si nécessaire.
curl -L "https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-$(uname -s)-$(uname -m)" -o ./docker-compose
# Installer docker-compose
sudo chmod +x docker-compose
sudo mv docker-compose /usr/local/bin/.
# Commande alternative pour
sudo install -o root -g root -m 0755 docker-compose /usr/local/bin/docker-compose
# Vérifier que l'installation s'est bien passée
docker-compose -v
Si l'utilisateur est déjà dans le groupe staff, il suffit d'exécuter
curl -L "https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose -v
Architectures possibles :
- Un swarm de N noeuds tenant à la fois le rôle d'hôte docker et de noeud glusterfs (c'est à dire /data/.../vol-1 et /mnt/vol-1 sur chacun des noeuds)
- Un swarm de N noeuds couplé à un cluster gluster de M noeuds
Script pour automatiser l'installation et l'update
#!/bin/bash
# Get latest docker compose released tag
COMPOSE_VERSION=$(curl -s https://api.github.com/repos/docker/compose/releases/latest | grep 'tag_name' | cut -d\" -f4)
# Continue ?
echo "Will install docker-compose versin ${COMPOSE_VERSION}"
read -n 1 -s -r -p "Press any key to continue [ctrl-c to abort]"
# Get docker-compose binary
curl -L "https://github.com/docker/compose/releases/download/${COMPOSE_VERSION}/docker-compose-$(uname -s)-$(uname -m)" -o ./docker-compose.${COMPOSE_VERSION}
# Install docker-compose
sudo install -o root -g root -m 0755 docker-compose.${COMPOSE_VERSION} /usr/local/bin/docker-compose
# Cleanup
rm docker-compose.${COMPOSE_VERSION}
# Output compose version
docker-compose -v
exit 0
Installation en tant que plugin Docker
Dans les versions récentes de Docker, Docker Compose est disponible sous la forme d'un plugin pour l'outil en ligne de commande :
sudo apt install docker-compose-plugin
Son utilisation est identique à celle de Docker Compose en version standalone, seule la manière d'appeler la commende change : de docker-compose <command> <option> elle devient docker compose <command> <option>.
Note : L'installation standalone permet d'avoir une version plus à jour de Docker Compose
docker compose version: Docker Compose version v2.17.3docker-compose version: Docker Compose version v2.18.1
De plus la version du plugin est maintenue par les mainteneurs des paquets Docker pour les différentes distributions Linux.
Déploiement du cluster Docker Swarm
Le déploiement du swarm se fait en plusieurs étapes :
- activation du swarm et création du premier manager
- (optionnel) ajout de managers supplémentaires
- ajout des workers
- (optionnel) promotion de workers en managers
L'exemple suivant est basé sur une infrastructure avec 5 noeuds afin de donner une vue plus complète de l'initialisation d'un Swarm Docker. Dans le cas de mon infrastructure de démonstration, je suis directement passé à l'ajout des workers après l'initialisation du Swarm et la création du premier manager.
Activation du swarm et création du premier manager
Pour activer le swarm et créer le premier manager, il suffit d'exécuter la commande suivante :
# Initialisation du swarm
docker swarm init --advertise-addr <IP_DU_MANAGER>
# affiche un résultat du type
# docker swarm join --token <UN_LONG_TOKEN> <IP_DU_MANAGER>:2377
Notes : Le token généré lors de cette commande sera nécessaire pour joindre les autres nœuds au swarm.
La commande docker swarm join-token worker permet d'afficher ce token par la suite.
Après cette opération, on obtient un swarm composé d'un seul nœud qui remplira à la fois le rôle de manager et de worker.
La commande docker nod ls permet de visualiser les neuds du swarm :
# Vérifier l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Leader 20.10.13
Pour un swarm à un seul nœud , comme l'infrastructure de formation du portail, c'est tout ! Le swarm est prêt à être utilisé. Pour un swarm à plusieurs nœuds, il faut maintenant joindre les autres nœuds au cluster.
Ajout des autres noeuds
Une fois le swarm initialisé, il est possible de lui ajouter d'autres nœuds workers ou managers.
Ajout des autres managers
Dans un swarm avec plusieurs managers, il reste à promouvoir les autres managers.
Pour obtenir un consensus sur l'état du cluster, il faut un nombre impair de managers. Afin de combiner redondance et performances, 2 managers supplémentaires sont ajoutés. Ajouter des managers supplémentaires peut se faire de deux manières :
- En spécifiant le rôle de manager dans la commande en exécutant la commande générée par
docker swarm join-token managersur chacun des managers supplémentaires (voir plus haut) - En promouvant les noeuds en manager depuis le premier manager. Cette méthode est décrite plus bas.
Comme ici on sait déjà quels nœuds seront les managers, ils sont ajoutés au swarm directement avec ce rôle en exécutant la commande affichée par docker swarm join-token manager sur chacun d'entre eux :
# Afficher la commande à exécuter sur les workers
docker swarm join-token manager
# Retourne une commande du type à exécuter sur chacun des noeuds manager supplémentaires
docker swarm join --token <UN_LONG_TOKEN> <IP_DU_MANAGER>:2377
On peut alors vérifier l'état du cluster et que les 3 managers sont bien disponibles
# Vérifier l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Leader 20.10.13
0whu7cq053xvrnrrtylrqp52e manager2 Ready Active Reachable 20.10.13
k6h1kd3pd8l5ja9o29jhqmnmf manager3 Ready Active Reachable 20.10.13
Si on ne sait pas encore quels nœuds seront manager ou si on veut donner le rôle de manager à des workers, il est possible de promouvoir un worker. La procédure est décrite plus loin.
Ajout des workers
Il suffit joindre les autres nœuds au swarm en exécutant la commande affichée par docker swarm join-token worker sur chacun d'entre eux :
# Afficher la commande à exécuter sur les workers
docker swarm join-token worker
# Retourne une commande du type à exécuter sur chacun des noeuds worker
docker swarm join --token <UN_LONG_TOKEN> <IP_DU_MANAGER>:2377
On peut vérifier que les noeuds sont bien ajoutés en exécutant la commande docker node ls sur le manager (ici on a ajouté 4 noeuds)
# Vérifier l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Leader 20.10.13
0whu7cq053xvrnrrtylrqp52e manager2 Ready Active Reachable 20.10.13
k6h1kd3pd8l5ja9o29jhqmnmf manager3 Ready Active Reachable 20.10.13
opnn5kj1839pq603m1fbh029i worker1 Ready Active 20.10.13
zqnzuwfmk2argo5eobp4ikegt worker2 Ready Active 20.10.13
A la fin de cette opération, on a donc obtenu un swarm constitué d'un manager et de plusieurs workers comme, par exemple, l'infrastructure de développement du portail. Pour une infrastructure à plusieurs managers, il reste à promouvoir les managers supplémentaires.
Promotion d'un worker en manager (optionnel)
Dans ce scénario, on ajoute les autres nœuds que le manager1 en tant que worker du swarm avec la commande affichée par docker swarm join-token worker :
# Afficher la commande à exécuter sur les workers
docker swarm join-token worker
# Retourne une commande du type à exécuter sur chacun des noeuds worker
docker swarm join --token <UN_LONG_TOKEN> <IP_DU_MANAGER>:2377
Note : ports Docker
- 2376 : port de l'API Docker
- 2377 : port de l'API Docker Swarm
- 5000 : port du registry Docker (machine de build)
L'état du swarm est alors le suivant :
# Afficher l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Leader 20.10.13
0whu7cq053xvrnrrtylrqp52e manager2 Ready Active 20.10.13
k6h1kd3pd8l5ja9o29jhqmnmf manager3 Ready Active 20.10.13
opnn5kj1839pq603m1fbh029i worker1 Ready Active 20.10.13
zqnzuwfmk2argo5eobp4ikegt worker2 Ready Active 20.10.13
Il faut donc promouvoir les nœuds manager2 et manager3 au rôle de manager du swarm. Il suffit pour cela d'exécuter la commande docker promote <NODE> pour chacun de ces nœuds sur le premier manager :
# Promouvoir les autres managers
docker node promote manager2
docker node promote manager3
Il suffit alors de vérifier l'état du swarm avec docker node ls :
# Vérifier l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Leader 20.10.13
0whu7cq053xvrnrrtylrqp52e manager2 Ready Active Reachable 20.10.13
k6h1kd3pd8l5ja9o29jhqmnmf manager3 Ready Active Reachable 20.10.13
opnn5kj1839pq603m1fbh029i worker1 Ready Active 20.10.13
zqnzuwfmk2argo5eobp4ikegt worker2 Ready Active 20.10.13
Remarque sur le statut de Leader des managers
Le Leader est le nœud manager qui a été élu comme référence pour l'état du swarm. Ce Leader n'est pas nécessairement le premier manager ajouté. Cela dépend du consensus trouvé entre les managers.
Par exemple, après un redémarrage des daemon docker sur les hôtes, le statut de Leader a été attribué au manager2 :
# Vérifier l'état du cluster
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
kuj58tn3l1ueyuyt4nnjtulip * manager1 Ready Active Reachable 20.10.13
0whu7cq053xvrnrrtylrqp52e manager2 Ready Active Leader 20.10.13
k6h1kd3pd8l5ja9o29jhqmnmf manager3 Ready Active Reachable 20.10.13
opnn5kj1839pq603m1fbh029i worker1 Ready Active 20.10.13
zqnzuwfmk2argo5eobp4ikegt worker2 Ready Active 20.10.13
Déploiement des applications nécessaires au fonctionnement et à la gestion du swarm
Déploiement des 3 applications suivantes :
- Registry Docker
- Portainer
- Swarmpit
Registry
Le Registry Docker permet de stocker et de distribuer les images Docker "maison" au sein du swarm. Il se déploie sous la forme d'un simple conteneur :
# Déploiement du registry sur le manager1
docker run -d -p 5000:5000 --restart=always --name registry registry:2
Le Registry sera accessible via http://<ip du manager1>:5000.
Ne pas oublier le --restart=always sans quoi le registry ne redémarrera pas automatiquement avec sa machine hôte...
Configuration des hôtes dans /etc/hosts sur les noeuds du cluster afin d'utiliser le même hôte sur toutes les machines
# Ajouter
<IP DU REGISTRY> private-registry
Et dans le fichier /etc/docker/daemon.json ajouter une entrée pour le registry afin d'autoriser celui-ci sur les machines du swarm :
{
/* ... */
"insecure-registries" : [ "private-registry:5000" ]
}
Recharger la config via sudo systemctl reload docker
Et dans les fichiers docker-compose, utiliser images: private-registry:5000/path/to/image:tag pour les images custom tuilisant le registry.
Registry centralisé
Dans un second temps, un registry centralisé pour toutes les infrastructures sera mis en place afin d'éviter le build inutile d'images et de centraliser la gestion des images "approuvées".
Portainer
Il existe deux modes de fonctionnement pour Portainer : le mode Docker "pur" et le mode Docker Swarm. C'est le second qui est utilisé. Il déploie un service pour l'application portainer sur un des managers et un service agent sur chacun des noeuds.
# Récupération du fichier de déploiement de la stack Portainer
curl -L https://downloads.portainer.io/portainer-agent-stack.yml -o portainer-agent-stack.yml
# Déploiement de la stack Portainer (peut prendre du temps)
docker stack deploy -c portainer-agent-stack.yml portainer
Par défaut, le port publié par le service est le port 9000. Il peut être changé dans le fichier portainer-agent-stack.yml ou, temporairement, via docker service update [OPTIONS] <service>.
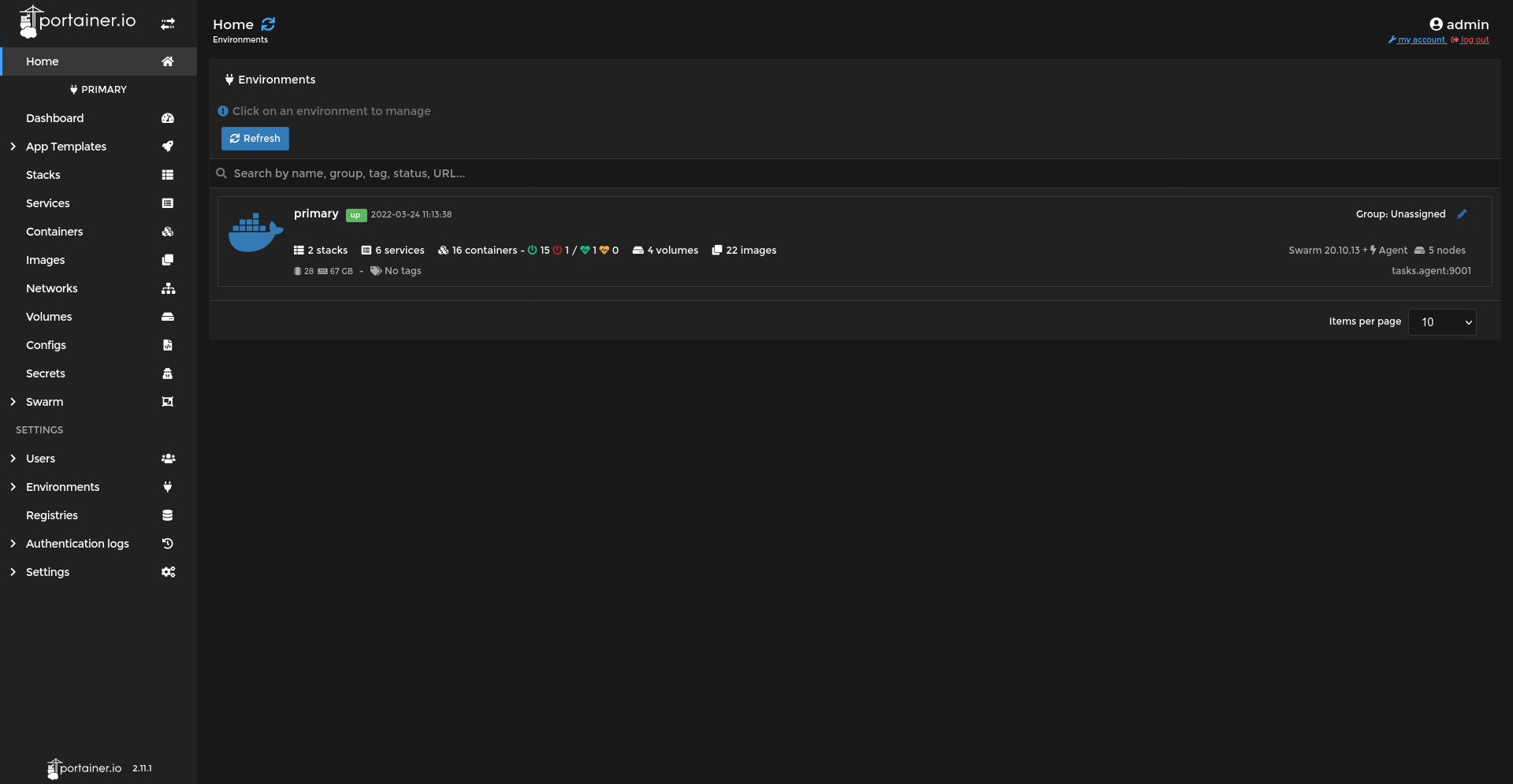
Pour compléter l'installation, il reste à ajouter le Registry dont l'url est http://<ip du manager1>:5000 via l'interface web de Portainer.
Note : l'agent portainer consomme 1 CPU complet lors de son exécution. Afin de limiter l'impact sur les performances des machines, j'ai décidé de limiter la quantité de CPU qu'il peut consommer :
docker service update --limit-cpu 0.5 --force portainer_agentAfin de répercuter le changement lors d'un prochain déploiement de la stack, la limite est ajoutée également dans le fichier de déploiement de la stack portainer :
# portaine-agent-stack.yml services: agent: # ... deploy: # ... resources: limits: cpus: '0.5'Impacts :
- l'agent consomme moins de ressource système lors de son exécution (1/2 CPU)
- l'agent tourne 2 fois plus souvent (toutes les 30 minutes au lieu de toutes les 1h)
L'exécution de l'agent impacte moins les performances et la consommation de ressources des machines hôtes.
Fichier complet de déploiement de Portainer :
version: '3.2'
services:
agent:
image: portainer/agent:2.11.1
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /var/lib/docker/volumes:/var/lib/docker/volumes
networks:
- agent_network
deploy:
resources:
limits:
cpus: '0.5'
mode: global
placement:
constraints: [node.platform.os == linux]
portainer:
image: portainer/portainer-ce:2.11.1
command: -H tcp://tasks.agent:9001 --tlsskipverify
ports:
- "9443:9443"
- "9000:9000"
- "8000:8000"
volumes:
- portainer_data:/data
networks:
- agent_network
deploy:
mode: replicated
replicas: 1
placement:
constraints: [node.role == manager]
networks:
agent_network:
driver: overlay
attachable: true
volumes:
portainer_data:
Pour mettre à jour
# Mettre à jour portainer
docker service update --image portainer/portainer-ce:latest --publish-add 9443:9443 --force portainer_portainer
# Mettre à jour l'agent
docker service update --image portainer/agent:latest --force portainer_agent
Swarmpit
Pour Swarmpit, un installeur est fourni mais requiert un accès illimité à Internet depuis les machines à l'intérieur du container de l'installateur. Comme cela n'est pas encore possible au moment de l'installation du cluster, il faut utiliser la méthode manuelle :
# Récupération des fichiers de déploiement de la stack Swarmpit
git clone https://github.com/swarmpit/swarmpit.git
# Déploiement de la stack Swarmpit (peut prendre du temps)
docker stack deploy -c swarmpit/docker-compose.yml swarmpit
Swarmpit installe plusieurs services : les 3 services de l'application elle-même et un agent répliqué sur chaque nœud du cluster.
Par défaut, le port publié par le service est le port 888. Ce port a été changé en 81 via Portainer de manière temporaire afin de tester l'application. Alternativement, ce changement de port peut-être effectué en ligne de commande via la commande docker service update [OPTIONS] <service> ou configuré de manière définitive dans le fichier swarmpit/docker-compose.yml.
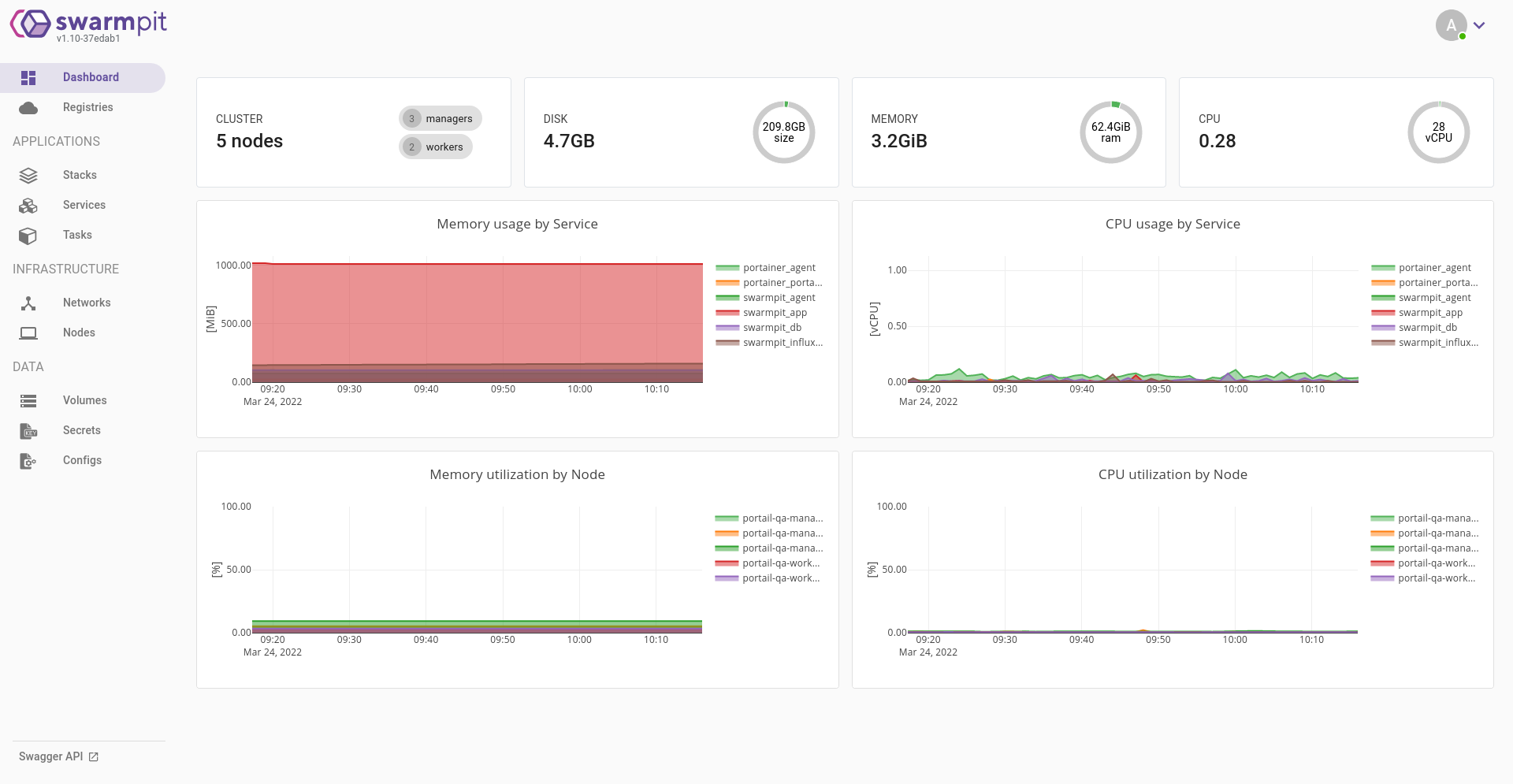
Vérification de l'état des services
Après l'installation des différentes stacks, l'état des services sur le cluster est le suivant :
# Vérification de l'état des services
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
iwq8kvzazmj2 portainer_agent global 5/5 portainer/agent:2.11.1
h18n3f8ym5v6 portainer_portainer replicated 1/1 portainer/portainer-ce:2.11.1 *:8000->8000/tcp, *:9000->9000/tcp, *:9443->9443/tcp
pmkzydpr79bz swarmpit_agent global 5/5 swarmpit/agent:latest
tdg75vh6w91c swarmpit_app replicated 1/1 swarmpit/swarmpit:latest *:81->8080/tcp
jdq8z2hff3oy swarmpit_db replicated 1/1 couchdb:2.3.0
zlxjgbtoiwy6 swarmpit_influxdb replicated 1/1 influxdb:1.7
Le registry n’apparaît pas car il ne tourne pas au sein d'une stack :
# Sur le manager1 sur lequel le registry est déployé
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
33794adc956f swarmpit/swarmpit:latest "java -jar swarmpit.…" 20 hours ago Up 20 hours (healthy) 8080/tcp swarmpit_app.1.0mix46fd7260lyinkmf47rmw4
4e9eca7df72f swarmpit/agent:latest "./agent" 20 hours ago Up 20 hours 8080/tcp swarmpit_agent.kuj58tn3l1ueyuyt4nnjtulip.gkzen5bg8bjzhqije1fs858cg
d3ef3c549d05 portainer/agent:2.11.1 "./agent" 20 hours ago Up 20 hours portainer_agent.kuj58tn3l1ueyuyt4nnjtulip.8x0869dns4rbuui1zei7ypbp4
9b4d6c22da5d registry:2 "/entrypoint.sh /etc…" 25 hours ago Up 25 hours 0.0.0.0:5000->5000/tcp, :::5000->5000/tcp registry
Quelques commandes utiles
Voir https://docs.docker.com/reference/ pour la référence complète des commandes et options disponibles.
- Commandes générales
docker swarm <COMMAND> [OPTIONS]: gérer le cluster Docker Swarmdocker node <COMMAND> [OPTIONS] [NODE]: gérer les noeudsdocker stack <COMMAND> [OPTIONS] [stack name]: gérer les stacks applicativesdocker service <COMMAND> [OPTIONS] [service]: gérer les services
- Commande d'état
docker ps: liste les tâches en cours d'exécution sur un hôtedocker service ls: affiche la liste des services en cours d'exécutions sur le swarmdocker service inspect <SERVICE>: afficher les informations sur un service (ajouter--prettypour un affichage "human-readable")docker node ls: affiche la liste des nœuds du swarm et leur étatdocker node inspect <NODE>: afficher les informations sur un nœud (ajouter --pretty pour un affichage "human-readable")
- Commandes de modification
docker service update [OPTIONS] <SERVICE>: modifier un service en cours d'exécutiondocker service scale <SERVICE>=<NUMBER_OF_TASKS>: modifier le nombre de répliques d'un servicedocker node update --label-add <LABEL> <NODE>: ajouter une étiquette sur un noeud , les labels peuvent être de la formeetiquetteouNAME=valeur
Système de fichier
Partage via NFS
Configuration des ACL
# Installer le paquet acl
sudo apt install acl
# Trouver le chemin de /dockerdata-ceph
df -a
/dev/vdf1 40972492 24 38858988 1% /dockerdata-ceph
# Vérifier que le filesystem supporte acl (remplacer /dev/vdd1 par le chemin correct)
sudo tune2fs -l /dev/vdf1
# Changer le groupe et le rendre "sticky"
sudo chgrp docker /dockerdata-ceph
sudo chmod g+s /dockerdata-ceph
sudo chmod g+rwX /dockerdata-ceph
# Ajouter les droits du groupe via les acl
sudo setfacl -Rdm g:docker:rwx /dockerdata-ceph/
Export via NFS
Sur le manager1
Installation du paquest nfs-kernel-server
sudo apt install nfs-kernel-server
Ajout du partage vers les nœuds du swarm dans /etc/exports
/dockerdata-ceph 10.1.4.26(rw,no_subtree_check,no_root_squash,async) 10.1.4.27(rw,no_subtree_check,no_root_squash,async) 10.1.4.28(rw,no_subtree_check,no_root_squash,async) 10.1.4.29(rw,no_subtree_check,no_root_squash,async)
Rechargement du daemon nfs-kernel-server
sudo systemctl reload nfs-kernel-server
Sur les autres noeuds
Ajout du partage dans /etc/fstab
10.1.4.25:/dockerdata-ceph /dockerdata-ceph nfs defaults,noatime
Creation du répertoire cible et montage du partage nfs
sudo mkdir /dockerdata-ceph
sudo mount -a
ls -al
total 24
drwxrwsr-x 3 root docker 4096 11 mar 14:29 .
drwxr-xr-x 20 root root 4096 4 avr 15:27 ..
drwx------ 2 root root 16384 11 mar 14:29 lost+found
Reverse proxy en entrée du cluster
En plus du répartiteur de charge/reverse proxy haproxy mis en place pour l'infrastructure SIPR, j'ai mis en place un service Docker de reverse proxy en entrée du cluster Docker Swarm.
La raison de ce choix est de répondre aux besoins suivants :
- centralisation de l'exposition des applications hébergées, sans cela, chaque application devrait être exposée à l'extérieur du cluster et rendue accessible dans le haproxy de SIPR
- certaines configurations telles que la récupération de l'IP du client, les logs... seront gérées au niveau du proxy et de manière transparente pour les applications qu'il expose
- seul le proxy est exposé à l'extérieur, ce qui réduit fortement le nombre de ports ouverts en entrée sur les hôtes du cluster (actuellement uniquement 80 et 443, mais d'autres pourraient l'être dans le futur pour exposer des web services, des websockets...)
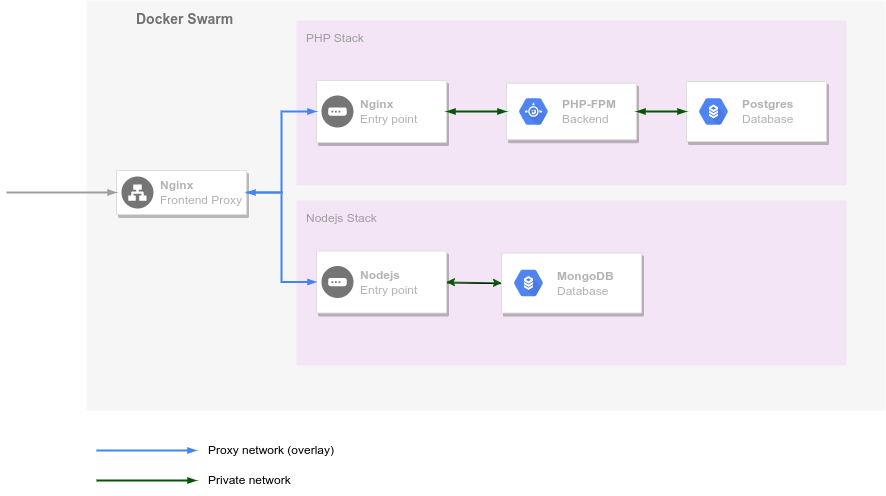
Mise en place du reverse proxy avec nginx
Afin de rencontrer les besoins exprimés plus haut, le reverse proxy nginx sera déployé globalement sur le cluster (c'est-à-dire qu'un répliqua sera créé sur chacun des hôtes). D'un point de vue technique, cela est mis en place à travers le mode global de la directive deploy du fichier de définition du service.
Afin de fournir les fichiers de configuration nécessaires au reverse proxy, 5 volumes sont montés en mode bind :
./config/nginx/conf.d:/etc/nginx/conf.d: fichiers de configurations chargés automatiquement pour tous les sites./config/nginx/sites:/etc/nginx/sites: fichiers de définitions des virtual hosts./config/nginx/nginx.conf:/etc/nginx/nginx.conf: configuration de base de nginx./config/nginx/includes:/etc/nginx/includes: fichiers de configuration pouvant être inclus dans les définitions des virtual hosts./config/ssl:/etc/nginx/ssl: certificats et clés pour la connection sécurisée via SSL
Comme je l'ai expliqué dans le chapitre technique sur Docker et Docker Swarm, le mode Swarm intègre une répartition de charge à travers son réseau ingress. L'utilisation d'un reverse proxy interne au cluster va nous permettre de profiter de cette fonctionnalité pour diriger les requêtes vers le bon noeud du Swarm et pour répartir la charge entre les conteneurs d'un même services sans que le HAProxy ou le proxy interne du cluster n'aient à avoir connaissance de la localisation de ces conteneurs.
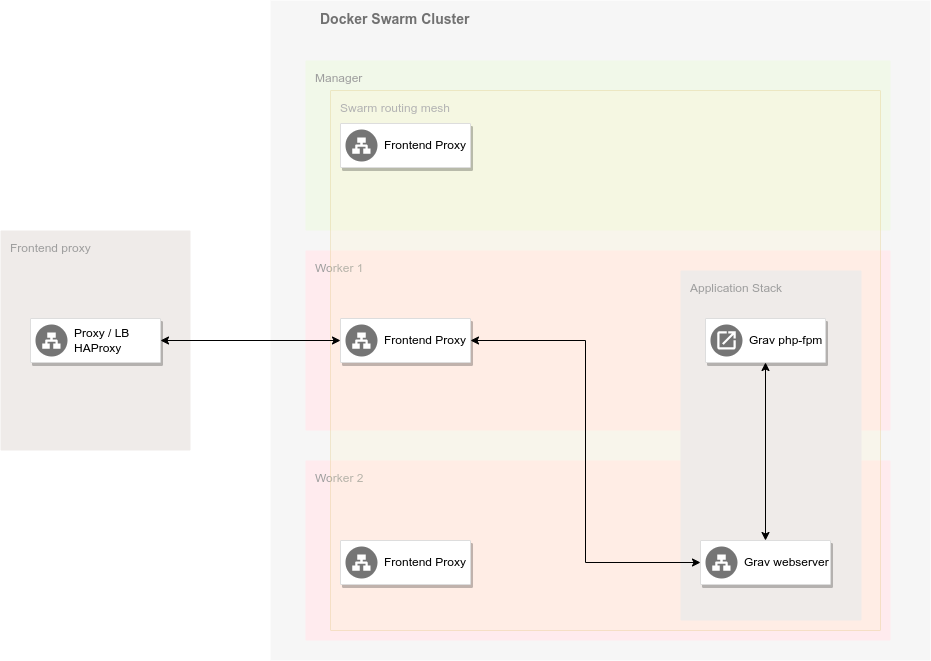
Mais ce qui est vrai pour un service en général l'est aussi par défaut pour le proxy interne : une requête arrivant sur HAProxy va être balancée sur un des noeuds du Swarm et, ensuite, via le routing mesh, sur l'un des noeuds exécutant le proxy interne. Le proxy interne lui-même passera par le routing mesh pour accéder au service de l'application demandée par le client. Nous avons donc deux niveaux de répartition de charge avant d'arriver au service demandé. L'idéal serait d'éviter d'avoir recours au routing mesh pour accéder au proxy interne.
Pour garantir cela, nous allons « exclure » le proxy interne du routing mesh de Docker Swarm en exposant les ports 80 et 443 du service directement sur les machines hôtes. Cela se fait via le mode host dans la définition des ports du service. Il s'agit d'une pratique conseillée pour la plupart des solutions de reverse proxy tournant en conteneur.
En tenant compte de tout cela, le fichier de définition du service est le suivant :
# proxy-compose.yml
version: "3.9"
services:
proxy:
image: nginx:latest
deploy:
mode: global
ports:
- target: 80
published: 80
mode: host
- target: 443
published: 443
mode: host
volumes:
- ./config/nginx/conf.d:/etc/nginx/conf.d
- ./config/nginx/sites:/etc/nginx/sites
- ./config/nginx/nginx.conf:/etc/nginx/nginx.conf
- ./config/nginx/includes:/etc/nginx/includes
- ./config/ssl:/etc/nginx/ssl
networks:
- proxy_public
networks:
proxy_public:
external: true
name: proxy_public
Le fichier de configuration de nginx a dû être adapté afin de permettre la récupération de l'adresse IP du client:
# config/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
server_names_hash_bucket_size 256;
# Retrieve real remote host ip address from Docker ingress network
set_real_ip_from 10.0.0.0/16;
# Retrieve real remote address from SIPR load balancer if ports exposed on host
set_real_ip_from 10.1.4.0/24;
real_ip_recursive on;
real_ip_header X-Forwarded-For;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
gzip on;
include /etc/nginx/conf.d/*.conf;
# Automatically load sites definitions
include /etc/nginx/sites/*.conf;
}
Un fichier de configuration SSL/TLS fournit la configuration commune à toutes les applications :
# config/nginx/includes/ssl.conf
ssl_session_timeout 1d;
ssl_session_cache shared:MozSSL:10m; # about 40000 sessions
ssl_session_tickets off;
# modern configuration
ssl_protocols TLSv1.3;
ssl_prefer_server_ciphers off;
# HSTS (ngx_http_headers_module is required) (63072000 seconds)
add_header Strict-Transport-Security "max-age=63072000" always;
# OCSP stapling
ssl_stapling on;
ssl_stapling_verify on;
ssl_certificate /etc/ssl/server.pem;
ssl_certificate_key /etc/ssl/server.key;
ssl_trusted_certificate /etc/ssl/server_interm.cert;
Avant de lancer le service, il faut également créer le réseau overlay sur lequel les applications devront être exposées.
`docker network create --opt encrypted --driver overlay --attachable proxy_public`
Il reste alors à lancer le proxy via docker stack deploy -c proxy-compose.yml proxy
Les fichiers de configuration des différents sites n'ont plus qu'à être placés dans le répertoire ./config/nginx/sites et seront chargés soit au démarrage du service, soit lors de son rechargement via docker service update proxy_proxy.
Voici par exemple le fichier donnant accès à l'instance de Portainer sur mon infrastructure :
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
access_log /var/log/nginx/portainer.log main;
server_name
portainer.dckr.sisg.ucl.ac.be;
include /etc/nginx/includes/ssl.conf;
location / {
include /etc/nginx/includes/access.conf;
proxy_pass http://portainer_portainer:9000;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header Host $host;
}
# replace with the IP address of your resolver
# resolver 127.0.0.1;
}
Une commande pour générer les configurations des sites automatiquement
Afin de déployer plus rapidement les applications sur mon infrastructure, j'ai écrit une petite commande permettant la génération des fichiers de configuration de site sur base d'un template et de variables d'environnement.
Template de configuration de site :
# Basic site configuration template
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
access_log /var/log/nginx/{{VIRTUAL_HOST}}.log main;
server_name {{VIRTUAL_HOST}};
include /etc/nginx/includes/{{SSL_FILE}};
include /etc/nginx/includes/fileprotect.conf;
location / {
include /etc/nginx/includes/proxy.conf;
include /etc/nginx/includes/fileprotect.conf;
proxy_pass {{VIRTUAL_PROTO}}://{{VIRTUAL_SERVICE}}:{{VIRTUAL_PORT}};
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
}
# replace with the IP address of your resolver
# resolver 127.0.0.1;
}
Commande bash pour la génération des configurations :
#!/bin/bash
SCRIPT_cmdname=${0##*/}
SCRIPT_DIR="$( cd "$( dirname "$0" )" && pwd )"
if [[ -f ${1} ]]; then
echo "Loading variables from ${1}"
source ${1}
fi
if [[ -z "${VIRTUAL_HOST}" || -z "{VIRTUAL_SERVICE}" ]]; then
echo "At least VIRTUAL_HOST and VIRTUAL_SERVICE must be defined in the environment or the given variable file."
exit 1
fi
render_template() {
cp "${SCRIPT_DIR}/../config/nginx/site.tpl.txt" "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
sed -i s/\{\{VIRTUAL_HOST\}\}/"${VIRTUAL_HOST}"/ "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
sed -i s/\{\{SSL_FILE\}\}/"${SSL_FILE:-ssl.conf}"/g "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
sed -i s/\{\{VIRTUAL_SERVICE\}\}/"${VIRTUAL_SERVICE}"/g "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
sed -i s/\{\{VIRTUAL_PORT\}\}/"${VIRTUAL_PORT:-80}"/g "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
sed -i s/\{\{VIRTUAL_PROTO\}\}/"${VIRTUAL_PROTO:-http}"/g "${SCRIPT_DIR}/../config/nginx/sites/${VIRTUAL_HOST}.conf"
}
render_template
docker service update proxy_proxy
Exemple de variables d'envirronment à fournir via un fichier :
SITE_HOST=myapp.apps.sisg.ucl.ac.be
SSL_FILE=apps-ssl.conf
VIRTUAL_SERVICE=myapp_webserver
VIRTUAL_PORT=8080
VIRTUAL_PROTO=http
Exécution de la commande
newsite /path/to/site/envfile
Le nouveau site est alors accessible sur l'infrastructure.
Note : Cette commande est encore expérimentale et ne fonctionne pas dans 100% des cas, mais elle permet de simplifier les déploiements en attendant de passer à une solution plus solide comme
nginx-proxyque j'aborderai dans le chapitre sur les Perspectives.
Déploiement d'applications et livraison continue
- Contexte et motivation
- Déployer les configurations spécifiques à chaque instance avec Docker
- Déploiement d’applications avec Ansible et Docker-Compose
- Optimisation de la taille des conteneurs et build multi-step
- Livraison continue avec Gitlab CI
Contexte et motivation
La livraison continue fait partie des pratiques CI/CD (pour Continuous Integration/Continous Delivery or Deployment) qui sont au coeur des méthodes agiles ou des pratiques DevOps. L'objectif de ces pratiques est de mettre en production les nouvelles fonctionnalités d'une application rapidement et de manière automatisée.
L'intégration continue se centre sur les développeurs en automatisant la validation l'intégration des modifications qu'ils effectuent dans la base de code de l'application. Avec la livraison continue, les nouvelles fonctionnalités sont testées et mises à disposition automatiquement dans un dépôt (par exemple un dépôt git) afin que les équipes d'exploitation puissent les déployer en production. Quant au déploiement continu, il automatise le déploiement en production des applications mises à disposition sur le dépôt.
Dans le cadre des applications déployées dans des conteneurs, le CI/CD s'étend à l'infrastructure elle-même via :
- La construction automatisée des images Docker
- La mise à disposition des configurations des services
- Le déploiement des services basés sur ces configurations
- La mise à jour des services et de leurs configurations
- La gestion des configurations (et des secrets...) interne au Swarm Docker
- ...
Un des problèmes à résoudre pour le déploiement d'application dans différents environnements est la possibilité de fournir des configurations spécifiques pour chacun d'entre eux. Idéalement, ces configurations devraient être versionnées et déployables en utilisant les mêmes outils que le code des applications elles-mêmes. Ce principe est appelé "configuration as code".
Dans ce chapitre, je vais aborder plusieurs techniques, outils et exemples permettant de mettre en place une livraison continue pour des infrastructures Docker Swarm. Je vais en particulier m'intéresser au concept de "configuration as code" et de la manière dont cette technique peut s'appliquer à Docker à travers la composition de fichier Docker Compose ou l'utilisation de variables d'environnement. J'aborderai également les outils Ansible et Gitlab CI.
Déployer les configurations spécifiques à chaque instance avec Docker
Docker propose plusieurs mécanismes qui simplifient le déploiement des configurations :
- La composition de fichier Docker Compose qui permet d'écraser ou de définir certaines directives de déploiement des piles applicatives
- Le support des variables et fichiers d'environnement qui permet de définir des valeurs spécifiques à chaque environnement
- Le support des contextes Docker qui permet de joindre un environnement Docker donné depuis une seule machine
- Les mécanismes de secrets et configurations qui permettent de spécifier des éléments de configuration directement dans un Swarm Docker pour les mettre à disposition des services déployés
Note : Ansible permet directement d'exécuter des actions spécifiques à certains environnements et ses fichiers peuvent être versionnés. Je vais donc me concentrer sur les mécanismes intégrés à Docker dans cette section.
Composition de fichiers de configuration de services avec docker-compose
Docker Compose permet de diviser la configuration des services en plusieurs fichiers qui seront chargés successivement lors de l’initialisation des conteneurs1. Cela permet, par exemple, d’avoir un fichier générique de déploiement d’application fonctionnant partout mais dans lequel certaines options sont manquantes et d’isoler les modifications nécessaires pour un déploiement « custom » dans un second fichier.
Par exemples, un premier fichier pourrait définir le service de base :
version: "3.7"
services:
webserver:
image: nginx:alpine
volumes:
- .:/application
- ./config/nginx-application.conf:/etc/nginx/sites-enabled/default
Et un autre indiquer les ports à utiliser pour ce service :
version: "3.7"
services:
webserver:
ports:
- "8001:80"
Docker Compose charge automatiquement deux fichiers de configuration si rien d’autre n’est précisé :
docker-compose.yml: fichier chargé par défaut lors de l’exécution de la commandedocker-compose updocker-compose.override.yml: s’il existe, ce fichier sera charger automatiquement à la suite du fichierdocker-compose.yml
Note : le nom alternatif
compose.ymlest également reconnu automatiquement
Mais on peut également en ajouter d’autres, par exemple une configuration pour chaque environnement cible, par exemple :
- docker-compose.local.yml : pour un déploiement local
- docker-compose.swarm.yml : pour un déploiement sur un swarm docker
- docker-compose.staging.yml : pour un déploiement en QA
- docker-compose.prod.yml : pour un déploiement en production
- …
La composition doit être faite explicitement lors de l’appel à la commande docker-compose avec l’option --file (en raccourci -f) pour lister les fichiers à charger et l’ordre dans lequel les charger :
docker-compose -f docker-compose.yml -f docker-compose.local.yml up -d
ou via la commande docker stack et l’option --compose-file (ou -c en raccourci) sur le cluster
docker stack deploy --compose-file docker-compose.yml -c docker-compose.prod.yml <STACK_NAME>
Notes :
- Afin de pouvoir être composés, des fichiers Docker Compose doivent impérativement utiliser le même numéro de version
- Certaines directives des fichiers Docker Compose peuvent être étendues, d'autres ne peuvent être redéfinies2.
Docker et les variables d'environnement
Docker prend en compte les variables d’environnement. Celles-ci peuvent être passées aux commandes Docker ou via les fichiers Docker Compose soit via des variables individuelles, soit en utilisant des fichiers de variables d'environnement.
L'intérêt des variables d'environnement est de créer des fichiers de déploiement (Docker Compose, Dockerfile...) génériques et de définir les valeurs spécifiques à chaque déploiement sur la machine hôte.
Notes :
- La syntaxe est la même que pour les variables shell :
${<VAR_NAME>:-<DEFAULT_VALUE>}- Si un fichier
.envexiste dans le répertoire courant, il est chargé automatiquement par Docker- Les variables d'environnement peuvent également être accédées dans les fichiers Dockerfile avec la syntaxe
$VAR_NAMEet passé via les options-e VAR_NAME=VAR_VALUEou--env-file /path/to/env-filede la commande de construction d'image ou via le fichier Docker Compose.
Docker Secrets and Docker Config
Docker Swarm fournit deux mécanismes permettant de mettre à disposition des configurations partagées entre conteneurs :
- Pour les fichiers de configuration simple, ils peuvent être mis à disposition via la commande
docker config3 et ensuite montés dans un service d'une manière similaire à n'importe quel volume ou fichier. - Pour les fichiers contenant des données confidentielles (clés, certificats X509 ou SSH, credentials...), il est préférable d'utiliser la commande
docker secret4 qui permet de les stocker de manière sécurisée (ils sont chiffrés dans les journaux de RAFT et transmis vers les managers via une connexion TLS).
Voici un court exemple d'utilisation des configurations et secrets pour fournir les informations nécessaires à un proxy nginx :
version: "3.9"
# ...
services:
proxy:
image: nginx:latest
# ...
configs:
- source: nginx_default_site
target: /etc/nginx/sites/default.conf
mode: 0440
- source: nginx_shared_proxy
target: /etc/nginx/includes/proxy.conf
mode: 0440
secrets:
- source: ssl_cert
target: /etc/ssl/certs/proxy.pem
- source: ssl_interm
target: /etc/ssl/certs/proxy_interm.cer
- source: ssl_private_key
target: /etc/ssl/private/proxy.key
# ...
configs:
nginx_default_site:
file: ./config/nginx/sites/default.conf
nginx_shared_proxy:
external: true
secrets:
ssl_cert:
external: true
ssl_interm:
external: true
ssl_private_key:
external: true
# ...
Note : Les secrets et configs Docker sont une raison pour laquelle il peut être intéressant de déployer Docker Swarm même pour une infrastructure avec un seul noeud, plutôt que de se contenter de Docker Compose.
Exemples
Voici deux exemples qui illustrent l'utilisation de ces mécanismes pour le déploiement de piles applicatives.
Déploiement d'une pile Wordpress
L'exemple suivant combine variables définies dans l'environnement du shell qui exécute la commande de déploiement (par exemple via un fichier .env) et fichiers d'environnement dans un même fichier Docker Compose, afin de déployer une instance de Wordpress:
version: '3.7'
volumes:
dbdata:
wpdata:
networks:
net1:
services:
mysql:
image: mysql:${MYSQL_VERSION:-5.7}
env_file:
- db.env
networks:
- net1
volumes:
- type: volume
source: dbdata
target: /var/lib/mysql
pma:
image: phpmyadmin:${PMA_VERSION:-latest}
networks:
- net1
env_file:
- pma.env
wordpress:
image: wordpress:${WP_VERSION:-latest}
networks:
- net1
volumes:
- type: volume
source: wpdata
target: /var/www/html
env_file:
- wp.env
Le fichier d'environnement correspondant est :
# db.env
MYSQL_ROOT_PASSWORD=secret
MYSQL_DATABASE=wp1db
MYSQL_USER=wp1user
MYSQL_PASSWORD=wp1pass
Les variables passées peuvent également être utilisées dans les conteneurs eux-mêmes. Voici un exemple d'une telle utilisation dans l'entrypoint d'un service pour déployer la plateforme Moodle :
# entrypoint.sh
#!/bin/bash
# Configuration de Moodle à partir du template
echo "[$0]:creation du fichier de config."
sed \
-e "s,MOODLE_WWWROOT,${MOODLE_URL:-http://127.0.0.1:8000}," \
-e "s,MOODLE_LANG,${MOODLE_LANG:-fr_FR}," \
-e "s,MOODLE_DBTYPE,${MOODLE_DBTYPE:-pgsql}," \
-e "s,MOODLE_DB_HOST,${MOODLE_DB_HOST:-db}," \
-e "s,MOODLE_DB_NAME,${MOODLE_DB_NAME:-moodle}," \
-e "s,MOODLE_DB_USER,${MOODLE_DB_USER:-moodleuser}," \
-e "s,MOODLE_DB_PASSWORD,${MOODLE_DB_PASSWORD:-moodlepass}," \
-e "s,MOODLE_DB_TABLE_PREFIX,${MOODLE_DB_TABLE_PREFIX:-mdl_}," \
/tmp/config-dist.php > /var/www/html/config.php
exec "$@"
Cet exemple utilise sed afin de replacer des chaînes dans un template de configuration :
# config-dist.php
// ...
$CFG->lang = 'MOODLE_LANG';
$CFG->dbtype = 'MOODLE_DBTYPE'; // 'pgsql', 'mariadb', 'mysqli', 'auroramysql', 'sqlsrv' or 'oci'
$CFG->dblibrary = 'native'; // 'native' only at the moment
$CFG->dbhost = 'MOODLE_DB_HOST'; // eg 'localhost' or 'db.isp.com' or IP
$CFG->dbname = 'MOODLE_DB_NAME'; // database name, eg moodle
$CFG->dbuser = 'MOODLE_DB_USER'; // your database username
$CFG->dbpass = 'MOODLE_DB_PASSWORD'; // your database password
$CFG->prefix = 'MOODLE_DB_TABLE_PREFIX'; // prefix to use for all table names
// ...
Déploiement des piles Drupal pour le Portail
Dans la cadre du developpement du nouveau portail Drupal, j'ai été amené à résoudre plusieurs contraintes techniques liées au déploiement d'application. J'intègre cette problématique ici car sa résolution pourrait être appliquée à d'autres piles applicatives.
Les contraintes étaient :
- Le déploiement dans des environnements multiples
- Le déploiement sur des environnements d'exécution Docker différents
Déploiement dans des environnements multiples
La pile applicative du portail devait pouvoir être déployée dans des environnements de test (sur les machines locales des développeurs), des instances spécifiques à certains usages (test, formation, migration, démonstration...) et, bien entendu, la pré-production (QA) et la production. Chacun de ces environnements avait ses spécificités quant à la configuration de la pile applicative.
En particulier, la topologie de la pile (cluster avec 1 ou plusieurs noeuds), localisation de la base de donnée (dans la pile applicative ou sur un hôte distant), le montage de volume supplémentaires pour les migrations...
Déploiement sur des environnements d'exécution différents
Afin de répondre tant aux besoins des développeurs que de prestataires externes, les piles ont dû être rendues compatibles avec les environnements d'exécution Docker Compose, utilisé sur les machines locales sous MacOSX ou Windows, et Docker Swarm, utilisé sur les clusters distants ou sur les machines locales sous Linux.
Variables d'environnements et composition de piles Docker
J'ai implémenté la prise en compte de ces contraintes en utilisant 2 mécanismes : la composition de fichiers docker-compose de description des piles applicatives Docker (déjà abordée plus haut), et le mécanisme de variables d'environnement.
L'idée centrale était de décrire les spécificités de chaque déploiement dans un fichier de variables UNIX .env situé à la racine.
En voici un exemple pour un déploiement du portail sur un cluster Docker Swarm local derrière un reverse proxy nginx-proxy :
# Environnement d'exécution Docker (valeurs autorisées : swarm ou compose)
MODE=swarm
# Topologie de l'environnement Docker (ici mono nœud, valeurs autorisées mono ou multi)
SWARM_TOPO=mono
# Fichier de description de plie Docker à utiliser, dans ce cas un environnement utilisant nginx-proxy
SWARM_ENV=nginx-proxy
# Variable spécifiques à l'installation de l'application
BRANCH=develop
PORTAL_MODE=dev
PORTAL_INSTANCE=dev
POSTGRES_DB=drupal
POSTGRES_USER=drupal
POSTGRES_PASSWORD=password
DB_HOST=database
DB_PORT=5432
DRUPAL_PASSWORD=password
# Variables spécifiques à nginx-proxy
PORTAL_VHOST=portal.docker.localhost
PORTAL_VPROTO=http
PORTAL_VPORT=80
J'ai créé pour la pile applicative un fichier docker-compose.yml de base reprenant les directives et options communes à tous les environnements.
version: '3.7'
services:
webserver:
image: nginx:latest
depends_on:
- "php-fpm"
command: ["/bin/wait-for-it.sh", "php-fpm:9000", "--", "nginx", "-g", "daemon off;"]
env_file:
- docker/nginx/nginx.env
- .env
working_dir: /var/www/portail-next
volumes:
- ./var/www/portail-next:/var/www/portail-next/
- ./docker/wait-for-it.sh:/bin/wait-for-it.sh
- ./docker/nginx/conf.d:/etc/nginx/conf.d
- ./docker/nginx/sites:/etc/nginx/sites-enabled
- ./docker/nginx/nginx.conf:/etc/nginx/nginx.conf
php-cli:
image: private-registry:5000/drupal_phpfpm81:latest
build:
context: ./docker/php-fpm
dockerfile: dockerfile
cache_from:
- private-registry:5000/drupal_phpfpm81:latest
env_file:
- docker/php-fpm/php-fpm.env
- .env
working_dir: /var/www/portail-next
volumes:
- ./docker/php-fpm/php-ini-overrides.ini:/etc/php/8.1/fpm/conf.d/99-overrides.ini
- ./var/www/portail-next:/var/www/portail-next/
- ./bin:/var/www/portail-next/bin
command: ["tail", "-f", "/dev/null"]
php-fpm:
image: private-registry:5000/drupal_phpfpm81:latest
build:
context: ./docker/php-fpm
dockerfile: dockerfile
cache_from:
- private-registry:5000/drupal_phpfpm81:latest
env_file:
- docker/php-fpm/php-fpm.env
- .env
working_dir: /var/www/portail-next
volumes:
- ./docker/php-fpm/php-ini-overrides.ini:/etc/php/8.1/fpm/conf.d/99-overrides.ini
- ./var/www/portail-next:/var/www/portail-next/
- ./bin:/var/www/portail-next/bin
Ensuite, pour chaque valeur d'environnement spécifique SWARM_ENV et chaque topologie SWARM_TOPO, j'ai fourni un fichier environments/<SWARM_ENV>/docker-compose.<SWARM_TOPO>.yml contenant les directives et options spécifiques à chaque environnement.
# environments/prod/docker-compose.multi.yml
version: '3.7'
services:
webserver:
deploy:
mode: global
placement:
constraints:
- node.role!=manager
networks:
- portail_ntwrk
- proxy_public
volumes:
- /portail-data:/var/www/portail-next/web/sites/default/files/private
php-cli:
deploy:
replicas: 1
placement:
constraints:
- node.role==manager
networks:
- portail_ntwrk
volumes:
- /portail-data:/var/www/portail-next/web/sites/default/files/private
php-fpm:
deploy:
mode: global
placement:
constraints:
- node.role!=manager
networks:
- portail_ntwrk
volumes:
- /portail-data:/var/www/portail-next/web/sites/default/files/private
networks:
portail_ntwrk:
driver: overlay
attachable: true
proxy_public:
name: proxy_public
external: true
Enfin, j'ai créé une commande Bash (mais cela aurait pu être fait avec une commande ansible également) permettant de créer les piles applicatives, les démarrer et les arrêter en se basant sur les variables d'environnement définies pour sélectionner les bons fichiers de définition de pile.
En pratique, la personne devant déployer l'application n'a plus qu'à définir les variables correspondant à l'environnement sur lequel il ou elle effectue le déploiement dans un fichier nommé .env et situé à la racine du répertoire de son instance du portail. Il lui suffit ensuite d'exécuter le script permettant la création de la pile et de lancer celle-ci.
Le cas de Docker Compose est un peu particulier, puisqu'une personnalisation du fichier docker-compose.override.yml est nécessaire. Ce fichier docker-compose.override.yml doit également se trouver à la racine du répertoire de l'application à déployer.
Généralisation
Bien que créé spécifiquement pour le portail, ce mécanisme peut être généralisé avec un minimum d'effort et intégrer à d'autres piles applicatives. Il pourrait également être transformé en un ensemble de tâches Ansible ou être appelé par le mécanisme de livraison continue.
Déploiement d’applications avec Ansible et Docker-Compose
Une des solutions pour automatiser les opérations de déploiement de conteneurs consiste à utiliser Ansible et Docker Compose.
Automatisation de déploiement d’application avec Ansible : un exemple avec Kanboard, une application PHP élémentaire
Un premier cas de déploiement a été décrit plus haut avec l'application Kanboard. Il s’agissait d’un cas élémentaire ne demandant aucune installation autre que le téléchargement de l’application et le déploiement des services de la stack. La seule particularité était la gestion des droits sur le répertoire des données de l’application.
Afin de pouvoir fonctionner, cette application demande des extensions particulières pour le service php-fpm.
Celles-ci sont fournies par le générateur de squelette de déploiement docker-compose PhpDocker.io. Ce site permet de créer des stacks contenant la version de PHP, extensions et services tiers (bases de données, mail…) requis par une application PHP.
Fichier de configuration de services
Fichier docker-compose.yml :
version: "3.1"
services:
webserver:
image: nginx:alpine
container_name: kanboard-webserver
working_dir: /application
volumes:
- ./kanboard:/application
- ./docker/nginx/nginx.conf:/etc/nginx/conf.d/default.conf
php-fpm:
build: docker/php-fpm
container_name: kanboard-php-fpm
working_dir: /application
volumes:
- ./kanboard:/application
- ./docker/php-fpm/php-ini-overrides.ini:/etc/php/7.4/fpm/conf.d/99-overrides.ini
Fichier docker-compose.local.yaml :
version: "3.1"
services:
webserver:
ports:
- "8001:80"
Fichier de construction de l’image php-fpm
FROM phpdockerio/php74-fpm:latest
WORKDIR "/application"
# Fix debconf warnings upon build
ARG DEBIAN_FRONTEND=noninteractive
# Install selected extensions and other stuff
RUN apt-get update \
&& apt-get -y --no-install-recommends install php7.4-sqlite3 php7.4-bcmath php7.4-gd php7.4-intl php7.4-ldap php7.4-xsl php-yaml \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
# Install git
RUN apt-get update \
&& apt-get -y install git \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
Playbook de déploiement avec Ansible
---
- name: "Deploying Kanboard application locally"
hosts: localhost
connection: local
tasks:
- name: Check if kanboard folder exists
stat:
path: ../kanboard
register: kanboard_folder
- name: Get Kanboard
git:
repo: https://github.com/kanboard/kanboard.git
dest: ../kanboard
when: kanboard_folder.stat.exists == false
- name: Check if kanboard db exists
stat:
path: ../kanboard/data
register: kanboard_data
- name: Change file ownership, group and permissions
file:
path: ../kanboard/data
state: directory
recurse: yes
mode: 0777
when: kanboard_data.stat.mode != 0777
- name: Check if docker-compose.local file exists
stat:
path: ../docker-compose.local.yml
register: local_compose
- name: Deploy application containers with local compose file
args:
chdir: ../
shell: docker-compose -f docker-compose.yml -f docker-compose.local.yml up -d
when: local_compose.stat.exists == true
- name: Deploy application containers with default compose file
args:
chdir: ../
shell: docker-compose up -d
when: local_compose.stat.exists == false
Ce fichier automatise toutes les tâches nécessaires pour déployer l’application :
- récupération du code de l’application depuis un dépôt distant
- modifications de droits d’accès sur le répertoire des données de kanboard
- déploiement de l’application via docker-compose
Le déploiement de l’application en local se fait via la commande ansible-playbook :
ansible-playbook --connection=local playbooks/deploy.yml
Pour aller plus loin : gestion des droits d’accès pour un déploiement sur le cluster
Ce qui précède fourni le nécessaire pour déployer une application sur une machine locale. Toutefois, son déploiement sur le cluster Swarm demande une petite modification au niveau des droits d’accès sur les répertoires afin de correspondre aux ACL définies sur le cluster.
La modification est relativement simple : il suffit d’utiliser le groupe 'docker' pour l’accès aux fichiers. Toutefois, ce groupe n’existant pas dans notre conteneur php-fpm, une modification du fichier Dockerfile est nécessaire pour l’ajouter :
FROM phpdockerio/php74-fpm:latest
WORKDIR "/application"
# Fix debconf warnings upon build
ARG DEBIAN_FRONTEND=noninteractive
# Install selected extensions and other stuff
RUN apt-get update \
&& apt-get -y --no-install-recommends install php7.4-sqlite3 php7.4-bcmath php7.4-gd php7.4-intl php7.4-ldap php7.4-xsl php-yaml \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
# Install git
RUN apt-get update \
&& apt-get -y install git \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
# Ligne ajoutée pour créer le groupe docker dans le conteneur
# Attention le numéro du groupe dépend de la distribution
RUN groupadd --gid 999 docker
Il faudra également modifier le fichier de configuration du pool de php-fpm docker/php-fpm/php-ini-overrides.conf afin d’utiliser le groupe 'docker' au lieu le groupe 'www-data' utilisé par défaut.
Pour cela, il suffit de remplacer
[www]
user = www-data
group = www-data
par
[www]
user = www-data
group = docker
Il reste encore à modifier de la tâche de modification des droits d’accès dans le playbook de déploiement :
- name: Change file ownership, group and permissions
file:
path: ../kanboard/data
state: directory
group: docker
recurse: yes
mode: 0775
when: kanboard_data.stat.gr_name != 'docker'
Déploiement sur le swarm
version: "3.1"
services:
redis:
image: redis:alpine
container_name: framemo-redis
deploy:
replicas: 1
placement:
constraints:
- node.role!=manager
webserver:
image: nginx:alpine
container_name: framemo-webserver
working_dir: /application
volumes:
- ./framemo:/application
- ./config/nginx/default.conf:/etc/nginx/conf.d/default.conf
- ./wait-for-it.sh:/usr/local/bin/wait-for-it.ch
command: ["bash /usr/local/bin/wait-for-it.sh", "framemo-nodejs:3000", "--", "nginx", "-g", "daemon off;"]
deploy:
replicas: 1
placement:
constraints:
- node.role!=manager
depends_on:
- nodejs
nodejs:
image: dkm-webapps.sipr-dc.ucl.ac.be:5000/framemo_node:latest
build:
context: .
cache: dkm-webapps.sipr-dc.ucl.ac.be:5000/framemo_node:latest
container_name: framemo-nodejs
working_dir: /application
volumes:
- ./framemo:/application
- /application/node_modules
- ./config/framemo/config.js:/application/config.js
command: node /application/server.js --port 3000
deploy:
replicas: 1
placement:
constraints:
- node.role!=manager
Le script wait-for-it.sh permet d’attendre qu’un service soit disponible avant d’exécuter une commande. C’est particulièrement important pour éviter une erreur lors du démarrage du service nginx. Ce script est disponible dans les fichiers techniques ou sur github.
- name: "Deploying framemo application on a swarm"
hosts: localhost
connection: local
tasks:
- name: Check if framemo folder exists
stat:
path: ../framemo
register: framemo_folder
- name: Get framemo
git:
repo: https://framagit.org/framasoft/framemo.git
dest: ../framemo
when: framemo_folder.stat.exists == false
- name: Check if docker-compose.swarm file exists
stat:
path: ../docker-compose.swarm.yml
register: swarm_compose
- name: Deploy application containers with swarm compose file
args:
chdir: ../
shell: docker stack deploy -c docker-compose.yml -c docker-compose.swarm.yml framemo
when: swarm_compose.stat.exists == true
Analyses de cas
Framemo, une application nodejs + redis
L’application Framemo est une version modifiée mise à disposition par le collectif Framasoft de l’application de post-it en ligne Scrumblr. Son code source est disponible via le service gitlab framagit.org.
Il s’agit d’une application Nodejs relativement simple utilisant un serveur Redis pour le stockage de ses données. Elle utilise également le gestionnaire de paquet npm pour son installation. J’ai décidé d’ajouter un proxy Nginx à la stack, mais ce n’est pas nécessaire. En effet, le service nodejs de la stack pourrait servir de point d’entrée.
J’ai choisi cet exemple pour deux raisons :
- les exemples simples de déploiement d’application Nodejs avec docker-compose sont plutôt rares
- l’installation des paquets via le gestionnaire de paquet
npmlors de la construction de l’image docker du micro-service de l’application
Les principales contraintes que je m’étais fixées pour cet exemple sont :
- utiliser des images disponibles sur le hub de Docker
- ne pas exécuter la commande
npmsur la machine hôte, mais bien dans son conteneur - ne pas modifier les fichiers de l’application récupérés depuis gitlab
Configuration des services de l’application
Le fichier docker-compose.yml est le suivant :
version: "3.1"
services:
redis:
image: redis:alpine
container_name: framemo-redis
webserver:
image: nginx:alpine
container_name: framemo-webserver
working_dir: /application
volumes:
- ./framemo:/application
- ./config/nginx/default.conf:/etc/nginx/conf.d/default.conf
depends_on:
- nodejs
nodejs:
image: framemo_node
build: .
container_name: framemo-nodejs
working_dir: /application
volumes:
- ./framemo:/application
- /application/node_modules
- ./config/framemo/config.js:/application/config.js
command: node /application/server.js --port 3000
Remarques :
- Les noms des conteneurs des services ont été fixés dans le fichier pour faciliter le déploiement. Dans le cas contraire,
docker-composeattribue automatiquement comme nom le nom du répertoire suivi d'un "_" puis du non du service. Il est tout à fait possible de laisser docker le faire, mais dans ce cas des variables et des templates devront être utilisés pour les configurations des services et applications de la stack.- A part en ce qui concerne nodejs, cette stack utilise uniquement des images officielles disponibles depuis le hub de docker.
- Le port utilisé pour servir l'application Framemo a été modifié via
--port 3000, mais le port par défaut de l’application (8080) aurait pu être utilisé.
Un second fichier permet de modifier le port exposé par le serveur web Nginx afin de ne pas avoir de collision sur le port 80 :
version: "3.1"
services:
webserver:
ports:
- "8002:80"
Playbook Ansible pour un déploiement local
Le playbook de déploiement via Ansible est assez simple dans le cas de cette application. Il est responsable des actions suivantes :
- récupérer le code de l’application depuis son dépôt gitlab
- lancement de la stack avec les fichiers de configuration
docker-composedisponibles
Pour un déploiement local, le fichier est le suivant :
---- name: "Deploying framemo application locally" hosts: localhost connection: local tasks: - name: Check if framemo folder exists stat: path: ../framemo register: framemo_folder - name: Get framemo git: repo: https://framagit.org/framasoft/framemo.git dest: ../framemo when: framemo_folder.stat.exists == false - name: Check if docker-compose.local file exists stat: path: ../docker-compose.local.yml register: local_compose - name: Deploy application containers with local compose file args: chdir: ../ shell: docker-compose -f docker-compose.yml -f docker-compose.local.yml up -d when: local_compose.stat.exists == true - name: Deploy application containers with default compose file args: chdir: ../ shell: docker-compose up -d when: local_compose.stat.exists == false
Build de l’image pour nodejs
Un build de l’image utilisée pour Nodejs est nécessaire à la récupération des paquets npm nécessaires à notre application via la commande npm install.
Les volumes montés pour le build par docker-compose sont les suivants :
./framemo:/application: le répertoire de l’application/application/node_modules: pour récupérer les paquets installés parnpm./config/framemo/config.js:/application/config.js: pour personnaliser la configuration de l’application afin qu’elle puisse fonctionner dans la stack
Pour construire l’image, j’ai décidé d’utiliser une image node:alpine sur laquelle sera exécutée l’installation des paquets via npm.
Le fichier Dockerfile correspondant est :
# On part d’une image disponible sur le hub docker
FROM node:alpine
# Le répertoire de travail est le volume de l’application déclaré
# dans le fichier docker-compose.yml
WORKDIR /application
# On copie le fichier conteant la liste des dépendances de l’application
# ATTENTION le chemin est relatif au fichier Dockerfile !
COPY ./framemo/package.json .
# Exécution de la commande d’installation des paquets, ceux-ci seront installés dans
# /application/node_modules
RUN npm install --quiet
# Copie des fichiers récupérés afin de les rendre disponibles hors de l’image docker
COPY . .
Notes :
-
Ce fichier est inspiré par un exemple trouvé en ligne, toutefois aucun de ces exemples ne répondait aux contraintes et aux spécificités de l’application Framemo
-
Le chemin pour intégrer le fichier
package.jsonest relatif au fichierDockerfile, j’ai décidé de placer celui-ci à la racine du projet de déploiement -
Pour permettre l’installation des paquets
npmet leur accès sur le filesystem de l’hôte, il a fallu ajouter le montage/application/node_modulesau fichierdocker-compose.yml
Configuration de l’application et de nginx
Une modification de la configuration de l'application est nécessaire afin de pouvoir accéder au service Redis de la stack. Elle consiste à simplement remplacer dans une copie de la configuration originale la ligne
var redis_conf = argv.redis || '127.0.0.1:6379';
par
var redis_conf = argv.redis || 'framemo-redis:6379';
où framemo-redis est le nom interne utilisé par docker pour le routage des requêtes réseau vers le service redis au sein de la stack.
L’application peut alors être lancée via la commande node /application/server.js --port 3000dans le fichier docker-compose.yml.
Le choix du port est arbitraire et correspond à celui indiqué dans la configuration du serveur web Nginx :
server {
listen 80 default;
client_max_body_size 108M;
access_log /var/log/nginx/framemo.access.log;
root /application;
location / {
proxy_pass http://framemo-nodejs:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
où framemo-nodejs est le nom interne utilisé par docker pour le routage des requêtes réseau vers le service nodejs au sein de la stack.
Déploiement de l’application
Le déploiement de l’application en local se fait via la commande ansible-playbook :
ansible-playbook --connection=local playbooks/deploy.yml
Dont le résultat est
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match
'all'
PLAY [Deploying framemo application locally] ***************************************************************************
TASK [Gathering Facts] *************************************************************************************************
ok: [localhost]
TASK [Check if framemo folder exists] **********************************************************************************
ok: [localhost]
TASK [Get framemo] *****************************************************************************************************
skipping: [localhost]
TASK [Check if docker-compose.local file exists] ***********************************************************************
ok: [localhost]
TASK [Deploy application containers with local compose file] ***********************************************************
changed: [localhost]
TASK [Deploy application containers with default compose file] *********************************************************
skipping: [localhost]
PLAY RECAP *************************************************************************************************************
localhost : ok=4 changed=1 unreachable=0 failed=0
Il suffit alors de se rendre sur l'url http://localhost:8002 pour accéder à l’application.
Autres applications
- Le CMS Grav
- Une application d’exemple basée sur Nodejs + Yarn
Optimisation de la taille des conteneurs et build multi-step
Les fichiers Dockerfile permettent de définir des recettes de construction d'image en plusieurs étapes. C'est en particulier utile lorsqu'une image est nécessaire pour construire une application, mais qu'une autre image sera utilisée pour exécuter l'application. C'est typiquement le cas des applications web basées sur Node.js (Angular, React...)
# Image Node.js 16 pour construire l'application React
FROM node:16-bullseye-slim as builder
RUN set -ex \
&& apt-get update && apt-get install -y git ca-certificates --no-install-recommends \
&& apt-get clean && rm -rf /var/lib/apt/lists/*
RUN set -ex \
&& mkdir -p /opt/fari \
&& git clone https://github.com/fariapp/fari-app.git /opt/fari \
&& cd /opt/fari \
&& npm install
RUN apt-mark auto '.*' > /dev/null \
&& find /usr/local -type f -executable -exec ldd '{}' ';' \
| awk '/=>/ { print $(NF-1) }' \
| sort -u \
| xargs -r dpkg-query --search \
| cut -d: -f1 \
| sort -u \
| xargs -r apt-mark manual \
&& apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false
RUN set -ex \
&& cd /opt/fari \
&& npm run build
# Image nginx permettant de servir l'application
FROM nginx:1.23.1
COPY --from=builder /opt/fari/dist /usr/share/nginx/html
Dans cet exemple, l'image node a laquelle j'ai attribué le nom builder (via FROM ... as builder) n'est utilisée que pour récupérer le code source de l'application depuis github et construire celle-ci. Une fois cette étape effectuée, les fichiers générés sont copiés dans une image basée sur nginx via COPY --from=builder. A la fin du build, seule cette seconde image sera conservée. Dans le cas de cette application, l'image de build pèse 1.92Go alors que l'image finale ne pèse que 135Mo !
Un autre exemple est le fichier que j'utilise pour déployer la version web de ce brevet :
# Image Rust temporaire permettant de construire l'application à déployer
FROM rust:1.67 AS builder
RUN cargo install mdbook mdbook-toc mdbook-mermaid
WORKDIR /opt/src
COPY . .
RUN mdbook build
# Image nginx qui permettra de servir l'application construite
FROM nginx:latest
COPY --from=builder /opt/src/book/html /usr/share/nginx/html
Ici le builder est une image contenant l'environnement d'exécution du langage Rust et installant d'installer l'outil mdbook et ses modules supplémentaires. Mdbook exécutent ensuite la génération du site web à partir des fichiers markdown de mon brevet. Les fichiers générés sont alors de nouveau copiés dans un conteneur nginx.
Note :
- le backend buildkit, utilisé par défaut depuis la version 23 de Docker mais disponible sur les versions précédentes, permet un plus grand contrôle sur les build multi-step. Il est par exemple possible de générer l'image d'une étape donnée d'un fichier Dockerfile multi-step.
- le processus de build ne gardera que la dernière image générée par défaut. En cas de build fréquent basé sur une même image, il est conseillé de télécharger cette image via
docker image pullafin d'éviter de gaspiller de la bande passante et du temps de téléchargement inutile. Les imagesrust:1.67ounode:16-bullseye-slimde mes deux exemples font chacune plus de 1Go.
Livraison continue avec Gitlab CI
La livraison continue est un mécanisme issu des pratiques DevOps et qui consiste à déployer une application lorsqu’une nouvelle version prête pour la production est disponible.
Ce mécanisme se distingue du déploiement continu par le fait que l’action est déclenchée ici à la demande des développeurs et non de manière automatique à chaque changement de la base de code de l’application. Le déploiement continu est généralement combiné avec l’intégration continue qui consiste, en gros, à valider les changements effectués sur une application sur base de tests automatisés. Le déploiement continu ne s’effectuera donc que si ces tests ont réussi.
La livraison continue permet donc d’avoir un plus grand contrôle sur le produit déployé et est plus sécurisant pour des applications critiques.
Dans la livraison continue, le déploiement d’une application peut être déclenché par plusieurs mécanismes comme l’exécution d’une commande depuis un outil d’automatisation ou sur base d’un événement comme le changement poussé sur une branche donnée dans le dépôt de son code source.
On distingue deux stratégies de déploiement pour mettre en place un mécanisme de livraison continue :
- Push-based : dans cette première stratégie, c’est une modification du code source d’une application qui va déclencher l’exécution des tâches de déploiement. C’est le mécanisme le plus souvent rencontré. Il est utilisé par Gitlab-CI, Jenkins, Travis CI… Le défaut de cette approche est que l’application ne sera déployée que si le code de l’application est modifié. Les changements sur les images Docker ne seront quant à eux pas pris en compte automatiquement.
- Pull-based : dans ce cas de figure, un agent (appelé opérateur) de l’environnement de déploiement va observer le dépôt du code source de l’application ainsi que le dépôt des images. Il déclenchera le déploiement s’il détecte une modification de l’un d’entre eux. C’est le fonctionnement mis en œuvre par GitOps, par exemple.
Afin de mettre en place ce mécanisme, j’ai choisi d’utiliser les outils suivants :
- Gitlab comme dépôt pour les fichiers de déploiement des applications et, lorsqu’il s’agit d’un développement interne, leur code source
- Gitlab-CI est le moteur d'exécution des tâches d'intégration continue, livraison continue et déploiement continu (CI/CD) de Gitlab
- Gitlab-Runner est l'outil qui permet l'exécution des taches de CI/CD sur les machines distantes
Note : Gitlab intègre un registre d'images Docker qui pourra être utilisé comme registry externe pour le Swarm. Le registre a été activé sur la Forge UCLouvain et sur le GItlab de SISG. Le mécanisme contient deux parties :
- Un service gitlab-runner doit être déployé sur la machine qui exécutera les tâches de déploiement
- Ce service doit être configuré dans les runners disponibles sur Gitlab. Un runner peut être soit
sharedpour l'ensemble des projets hébergés sur l'instance Gitlab, soit dédié à un groupe de projets ou à un projet spécifique.
L'enregistrement d'un runner se fait via l'interface de Gitlab, chaque runner se voit associé un token qui l'identifie et un autre qui permet au service gitlab-runner de s'enregistrer auprès de gitlab.
Les opérations à exécuter sont définies dans une pipeline. Les différentes tâches (jobs) seront exécutées par le runner. Les jobs d'une pipeline peuvent être traités en parallèles et exécutés par des runners différents (par exemple un runner chargé de construire l'application, un autre chargé de son déploiement). Les pipelines sont définis dans un fichier YAML nommé .gitlab-ci.yml.
L'exécution d'une pipeline peut être déclenchée par différents événements :
- Opération push sur un dépôt qui peut-être systématique ou avec des conditions (filtrage par branche, push sur un tag...)
- A la main via un click dans l'interface de gitlab
- De manière planifiée via un scheduler intégré à gitlab
- Via l'API de gitlab
La mise en place du mécanisme est relativement simple et est détaillée dans la documentation de Gitlab. Toutefois, le nombre d'options disponibles pour les pipelines est assez élévé et la consultation d'exemples peut s'avérer rapidement nécessaire.
Dans le cadre d'une infrastructure Docker, l'idéal est de déployer les services gitlab-runner sous la forme de conteneurs Docker afin de lui donner facilement accès aux opérations sur les services déployés dans le Swarm.
Voici un exemple de fichier de déploiement de Gitlab Runner :
version: '3.9'
volumes:
config:
home:
cache:
services:
runner:
image: gitlab/gitlab-runner:${RUNNER_VERSION:-latest}
restart: always
env_file:
- formation-swarm.env
entrypoint: "bash"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- config:/etc/gitlab-runner
- home:/home/gitlab-runner
- cache:/cache
healthcheck:
test: "gitlab-runner verify --name ${COMPOSE_PROJECT_NAME} 2>&1 | grep -q alive"
start_period: 10s
interval: 10s
timeout: 10s
retries: 10
command: |
-c 'set -e
printf "\\nSetting configuration...\\n"
mkdir -p /etc/gitlab-runner
echo -e " log_level = \"warning\"\n concurrent = $${CONCURRENT}\n check_interval = $${CHECK_INTERVAL}\n\n [session_server]\n session_timeout = 3600 " > /etc/gitlab-runner/config.toml
printf "\\nRegistering runner...\\n"
gitlab-runner register --non-interactive --executor docker --docker-image docker:dind --locked=false --docker-privileged --run-untagged=${RUN_UNTAGGED:-false} --tag-list=${RUNNER_TAG_LIST:-deploy}
printf "\\nRunning runner...\\n"
gitlab-runner run --user=gitlab-runner --working-directory=/home/gitlab-runner'
Note :
- le runner doit s'exécuter avec un utilisateur qui a des droits suffisants pour accéder aux fichiers du répertoire de travail pour le déploiement (ici respectivement gitlab-runner et /home/gitlab-runner).
- le runner utilise une image "docker in docker"
docker:dindafin de pouvoir exécuter des commandes docker depuis le conteneur lui-même
Et le fichier d'environnement correspondant qui définit les paramètres nécessaires à l'exécution du runner.
COMPOSE_PROJECT_NAME=fari.app-swarm
GITLAB_SERVER_URL=https://forge.uclouvain.be/
RUNNER_TOKEN=<TOKEN GENERE PAR GITLAB>
RUNNER_NAME=fari.app-swarm
API_URL=https://forge.uclouvain.be/api/v4
CI_SERVER_URL=https://forge.uclouvain.be/ci
REGISTRATION_TOKEN=<TOKEN GENERE PAR GITLAB>
CONCURRENT=-1
CHECK_INTERVAL=-1
DOCKER_VOLUMES=/var/run/docker.sock:/var/run/docker.sock
RUN_UNTAGGED=false
RUNNER_TAG_LIST=deploy
Les commandes qui seront exécutées par le runner sont définies dans un fichier .gitlab-ci.yml situé à la racine du projet concerné. Il suffit alors de déclarer un pipeline dans le projet Gitlab et de configurer ses conditions d'exécution, sa fréquence d'exécution et des variables additionelles. Si ce n'est pas fait, le runner devra être exécuté à la main via "Run pipeline".
Note : Des exemples plus complets peuvent être trouvés en ligne, par exemple sur https://gitlab.actilis.net/formation/gitlab/deploy-runner
Chaque Pipeline se caractérise par des "étages" (stages) qui seront exécutés dans l'odre de leur déclaration. Par exemple :
stages:
- prebuild
- build
- depls
- postdeploy
On définit alors des jobs qui seront assignés à chaque étage
build-docker-image
stage: build
script:
- docker compose build
deploy-on-swarm
stage: deploy
script:
- docker stack deploy -c compose-swarm.yml fari
Il y a également des directives prédéfinies comme before_script ou after_script qui seront exécutées respectivement avant et après chaque exécution d'une commande script. Chaque job peut lui-mème déclarer ses propres directives before_script ou after_script.
Gitlab CI constitue donc un outil extrêmement flexible et complet pour mettre en place la livraison continue avec Docker Swarm. Les pipelines et le runner sont relativement simples à mettre en place et à configurer.
« Share Compose configurations between files and projects » https://docs.docker.com/compose/extends/
« Share Compose configurations between files and projects » https://docs.docker.com/compose/extends/
« Store configuration data using Docker Configs » https://docs.docker.com/engine/swarm/configs/
« Manage sensitive data with Docker secrets » https://docs.docker.com/engine/swarm/secrets/
Perspectives
- Mise en place d'une infrastructure de production
- Monitoring, alertes et logs
- Étude de solution pour résoudre le problème du partage de données entre les noeuds du cluster
- Vers une infrastructure de production
- Vers une infrastructure basée sur Kubernetes et Rancher
- Vers la mise en place d’un cloud d’entreprise basé sur les conteneurs dans l'infrastructure SIPR
Mise en place d'une infrastructure de production
Bien que l'infrastructure Docker Swarm mises en place dans le cadre de mon brevet soit parfaitement fonctionnelle, il est possible de l'améliorer et de lui ajouter certains mécanismes permettant de mieux la gérer en production.
Dans ce chapitre, je donne des pistes et des propositions pour de telles améliorations.
Le proxy interne du cluster
Le principal problème du reverse proxy interne que j'ai mis en place est qu'il ne permet pas une détection automatique des services déployés. Une autre de ses limitations est que si l'un des services exposés via mon proxy vient à ne plus répondre pour une raison ou pour une autre, c'est l'entièreté du proxy qui refusera de redémarrer. Cette situation peut se produire simplement si une pile applicative est arrêtée ou détruite et que le fichier de configuration du site correspondant n'a pas été supprimé du disque.
Corriger ces quelques problèmes n'est pas impossible, mais requierait la mise en place de mécanismes qui existent déjà au sein d'autres solutions de reverse proxy.
Les principales solutions de reverse proxy utilisées avec les conteneurs Docker sont les suivantes :
- Nginx : solution de serveur web, reverse proxy et répartiteur de charge open source très légère et très performante
- Caddy : un serveur web open source très léger utilisant HTTPS par défaut
- Traefik : un reverse proxy / répartiteur de charge open source conçu pour faciliter le déploiement d’application en micro services via des API
- HAProxy : une solution de proxy et répartiteur de charge performante
- Nginx Proxy Manager : proxy nginx avec une interface web de gestion des sites et configurations
- Nginx Unit : version de nginx spécialisée pour les applications web et fournissant une API REST de contrôle et de configuration
- nginx-proxy : reverse proxy basé sur nginx et intégrant une détection automatique des conteneurs exposés
| Solution | Détection auto. |
|---|---|
| Nginx | non |
| Nginx Unit | non |
| HAProxy | non |
| Nginx Proxy Manager | non |
| Traefik | oui |
| Caddy | oui (*) |
| nginx-proxy | oui |
(*) avec un module complémentaire
Les solutions les plus adaptées a Docker sont Caddy, Traefik et nginx-proxy.
Parmi ces solutions, Traefik est la plus perfectionnée et offre des fonctionnalités adaptées à la mise à disposition de microservices sous forme d'API, mais nginx-proxy est de loin la plus simple à mettre en place. C'est à elles deux que je vais m'intéresser dans la suite, et plus spécifiquement à nginx-proxy.
Solution n°1 : nginx-proxy
Dans ce projet, j'ai décidé de me baser sur nginx-proxy afin de remplacer mon reverse proxy maison. Il s'agit d'un reverse proxy basé sur Nginx et qui est capable de détecter les conteneurs automatiquement sans nécessiter ni rechargement du service ni génération de configuration en interrogeant directement le daemon Docker.
Afin d'assurer la détection automatique des services exposés, nginx-proxy repose sur la déclaration de variables d'environnement :
VIRTUAL_HOSTest le fqdn via lequel le service est appelé depuis l'extérieur du SwarmVIRTUAL_PROTOest le protocole avec lequel appeler le service à l'intérieur du Swarm (https ou http), par défaut il est identique à celui utilisé depuis l'extérieur du SwarmVIRTUAL_PORTest le port sur lequel est accessible le service dans le Swarm, par défaut il est identique à celui utilisé depuis l'extérieur du Swarm
Mais pour que nginx-proxy puisse joindre les services, il faut encore les connecter sur un réseau overlay partagé avec celui-ci. Le proxy détecte les services exposés via le socket Docker de la machine et sur base des variables d'environnement défines plus haut. Ensuite, un système de templates permet de générer les configurations de sites.
Note: Nginx proxy peut gérer le renouvellement automatique des certificats SSL soit via letsencrypt soit via ACME. Il peut aussi utiliser des certificats pré-générés fournis dans des fichiers locaux.
Voici un exemple de fichier de déploiement du proxy :
## docker-compose-proxy.yml
version: '3.7'
services:
# Déclaration du service du proxy
nginx-proxy:
image: nginx-proxy/nginx-proxy
container_name: nginx-proxy
restart: unless-stopped
ports:
- target: 80
published: 80
mode: host
protocol: tcp
- target: 443
published: 443
mode: host
protocol: tcp
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ${PWD}/certs:/etc/nginx/certs
networks:
- proxy
# Declaration du réseau overlay sur lequel les services exposés doivent être connectés
networks:
proxy:
name: proxy
attachable: true
driver: overlay
driver_opts:
encrypted: 1
Remarquons qu'on aurait également pu utiliser la commande docker secret pour ajouter les certificats et clés privées au proxy.
Exemple de fichier docker-compose qui ajoute le réseau proxy et les variables d'environnement nécessaire pour connecter un service nommé webserver au reverse proxy.
## docker-compose.proxy-override.yml
version: '3.7'
networks:
proxy:
name: proxy
external: true
services:
webserver:
environment:
- VIRTUAL_HOST=wp.dckr.sisg.ucl.ac.be
- VIRTUAL_PROTO=https
- VIRTUAL_PORT=443
networks:
- proxy
Les fichiers SSL du serveur sont fournis via dckr.sisg.ucl.ac.be.cert et dckr.sisg.ucl.ac.be.key pour l'ensemble des applications du serveur.
Voici un autre exemple complet qui déploie un service NodeRed (une plateforme de développement low code basée sur nodejs) :
version: "3.7"
services:
node-red:
image: nodered/node-red:latest
environment:
- TZ=Europe/Amsterdam
# ports:
# - "1880:1880"
networks:
- node-red-net
- proxy
volumes:
- node-red-data:/data
environment:
- VIRTUAL_HOST=nodered.docker.localhost
- VIRTUAL_PROTO=http
- VIRTUAL_PORT=1880
volumes:
node-red-data:
networks:
node-red-net:
proxy:
name: proxy
external: true
Ou encore le fichier permettant de déployer le site de mon brevet sur mon poste :
version: '3.7'
services:
mdbook-app:
image: private-registry:5000/fminne/brevet:latest
build: .
environment:
- VIRTUAL_HOST=brevet.docker.localhost
- VIRTUAL_PROTO=http
- VIRTUAL_PORT=80
networks:
- proxy
networks:
proxy:
name: proxy
external: true
Note: Du fait du mécanisme très simple pour la détection et l'exposition des services, nginx-proxy peut s'utiliser tant en mode Compose qu'en mode Swarm.
Cette solution a toutefois le défaut de sa simplicité : elle fait perdre la possibilité de générer des configurations spécifiques pour certaines applications. Néanmoins, il est possible d'ajouter des configurations spécifiques en ajoutant des fichiers qui viendront écraser la configuration par défaut d'un VHOST. Il est également possible d'ajouter des sites "à la main", puisque nginx-proxy n'est jamais qu'un proxy Nginx modifiés.
Il n'est pas non plus possible d'exposer 2 ports d'un même service sur des fqdn ou path différents. Si ce genre d'utilisation s'avère nécessaire, il faudra soit ajouter des configurations "à la main" dans nginx-proxy, soit passer à une solution utilisant d'autres techniques (par exemple les labels pouvant être associés à un service), comme Traefik.
Le concepteur de nginx-proxy fournit un outil de génération automatique de configuration pour Nginx nommé
docker-genqui est intégré dans nginx-proxy et pourrait être utilisé pour générer des configurations plus spécifiques.
Configuration du proxy pour les applications lourdes
Nginx-proxy prévoit de pouvoir surcharger les configurations par défaut du reverse proxy, soit globalement, soit pour un vhost donné.
Certaines applications plus lourdes, par exemple Drupal, demandent d'augmenter la taille des buffers de nginx. Il peut aussi être intéressant de modifier les options passées via le proxy.
# proxy.conf
# HTTP 1.1 support
proxy_http_version 1.1;
proxy_buffering off;
proxy_set_header Host $http_host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $proxy_connection;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $proxy_x_forwarded_host;
proxy_set_header X-Forwarded-Proto $proxy_x_forwarded_proto;
proxy_set_header X-Forwarded-Ssl $proxy_x_forwarded_ssl;
proxy_set_header X-Forwarded-Port $proxy_x_forwarded_port;
proxy_set_header X-Original-URI $request_uri;
# Buffers
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
proxy_connect_timeout 300;
proxy_read_timeout 300;
proxy_send_timeout 300;
Le fichier doit être monté dans le container sur le chemin /etc/nginx/proxy.conf :
version: '3.7'
services:
nginx-proxy:
image: nginxproxy/nginx-proxy:latest
container_name: nginx-proxy
restart: unless-stopped
ports:
- target: 80
published: 80
mode: host
protocol: tcp
- target: 443
published: 443
mode: host
protocol: tcp
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ./nginx-data/certs:/etc/nginx/certs
- ./nginx-data/proxy.conf:/etc/nginx/proxy.conf
networks:
- proxy_public
deploy:
mode: global
networks:
proxy_public:
name: proxy_public
# attachable: true
# driver: overlay
# driver_opts:
# encrypted: 1
external: true
Notes :
- Comme pour mon reverse proxy « maison », la récupération de l'IP réelle du client demande de modifier le fichier nginx.conf du service. La manière de procéder est totalement identique (récupérer le fichier original depuis le conteneur, par exemple avec
docker cp), ajouter les lignes manquantes et monter le nouveau fichier à l'emplacement/etc/nginx/nginx.conf. Il est également possible de le faire directement dans un fichier Dockerfile qui construit l'image de nginx-proxy.- nginx-proxy est en développement actif et des nouvelles fonctionnalités s'ajoutent régulièrement. L'état du projet peut être consulté via son dépôt Github.
Pour aller encore plus loin : Traefik
La solution nginx-proxy est tout à fait satisfaisante pour la mise en place d'une infrastructure d'hébergement d'application web de type "single page", blog ou autre CMS. Elle est par contre moins adaptée s'il s'agit de mettre en place une infrastructure donnant accès à des web services via des API REST, GraphQL, SOAP... Dans ce cas de figure, Traefik est la solution la plus adaptée.
La solution la plus adaptée a Docker Swarm est Traefik. Traefik offre une grande souplesse dans la définition des règles de proxy pour les différents services. En particulier, il permet la publication d'un même service sur plusieurs fqdn ou sur des paths différents d'un même fqdn, la publication de plusieurs ports d'un même service sur des endpoints (paths ou fqdn) différents, la gestion fine des droits d'accès... Bref tout ce qui est nécessaire pour fournir à la fois un hébergement d'application web et la publication de services via des API.
Le prix à payer est une plus grande complexité dans sa prise en main.
Contrairement à nginx-proxy qui utilisait des variables d'environnement, Traefik se base sur les labels associés à un service lors de son déploiement. Cela signifie que Traefik ne peut pas être utilisé de manière transparente en mode Compose ou en mode Swarm puisque la déclaration des labels est différente entre ces deux situations.
A titre d'exemple, voici le fichier permettant de déployer Portainer avec Traefik dans un Swarm :
version: '3.2'
services:
agent:
image: portainer/agent:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /var/lib/docker/volumes:/var/lib/docker/volumes
networks:
- agent_network
deploy:
mode: global
placement:
constraints: [node.platform.os == linux]
portainer:
image: portainer/portainer-ce:latest
command: -H tcp://tasks.agent:9001 --tlsskipverify
ports:
- "9443:9443"
- "9000:9000"
- "8000:8000"
volumes:
- portainer_data:/data
networks:
- agent_network
- proxy_net
deploy:
mode: replicated
replicas: 1
placement:
constraints: [node.role == manager]
labels:
- "traefik.enable=true"
- "traefik.docker.network=proxy_net"
- "traefik.http.routers.portainer.rule=Host(`portainer.docker.localhost`)"
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
networks:
proxy_net:
external: true
agent_network:
driver: overlay
attachable: true
volumes:
portainer_data:
Automatiser le renouvellement des certificats TLS avec ACME
Il est aujourd'hui possible de renouveler les certificats des serveurs automatiquement avec ACME. Toutefois cette solution demande des adaptations au niveau du load balancer SIPR. En effet, dans l'implémentation actuelle, le proxy HTTP et la gestion du certificat SSL se font au niveau du load balancer. Or, le renouvellement du certificat via ACME se fera au niveau des conteneurs.
Une solution est de passer à une répartition de charge TCP et laisser le proxy de l'infrastructure gérer les connexions sécurisées.
Une autre, beaucoup plus intéressante, est de déplacer le renouvellement automatique des certificats sur le load balancer de SIPR. Les connexions sécurisées entre ce dernier et les machines du Data Center pourrait se faire avec des certificats internes certifié par une CA interne aux Data Centers.
Les avantages de cette seconde solution sont multiples :
- Éviter la duplication des clés privées et certificats entre le load balancer et les machines du Data Center, et les erreurs que cela peut entraîner
- Permettre le renouvellement automatique des certificats sur le load balancer lui-même, ce qui devrait éliminer les erreurs dues aux certificats expirés
- Permettre un inventaire des différents FQDN utilisant des certificats puisque tous se trouvent sur le load balancer
- Augmenter la sécurité en facilitant la révocation des certificats ou la suppression d'une clé privée
- Déplacer la responsabilité de la gestion des clés et certificats aux équipes applicatives, qui n'ont pas toujours la maîtrise de ces outils et technologies, vers l'équipe système ou sécurité qui les maîtrise
De plus, la CA interne pourrait être utilisée pour générer des certificats pour d’autres usages, par exemple sécurisé les connexions entre les nœuds de notre cluster Docker Swarm.
Note : la tendance actuelle, poussée par les GAFAM, est de réduire la durée de vie de certificats TLS. Passée de 3 ans à 1 an il y a quelques années, il est aujourd'hui question de réduire encore celle-ci à 90 jours. La gestion manuelle du renouvellement des certificats deviendra dès lors quasiment impossible, et l'automatisation du renouvellement sera obligatoire.
Monitoring, alertes et logs
Afin de pouvoir surveiller l'infrastructure et détecter les problèmes, il reste encore à mettre en place des outils de monitoring de l'infrastructure.
Portainer et, surtout, Swarmpit intègrent des fonctionnalités de monitoring, toutefois ces 2 solutions restent limitées. Côté infrastructure, Observium permet de surveiller les machines virtuelles.
Mais il existe d'autres outils spécialisés, standards et mieux adaptés au monde des conteneurs.
Sources de métriques pour Docker
Afin de pouvoir surveiller nos conteneurs et nos machines, nous avons besoin de statistiques et de chiffres. Il existe de nombreuses possibilités pour les obtenir.
Commande stats
Docker fournit des statistiques sur les conteneurs à travers la commande docker stats. Ces statistiques sont toutefois difficilement exploitables pour du monitoring et sont plutôt destinées au debugging des conteneurs.
Commande system info et cadvisor
D'autres métriques peuvent être exposées via les Control-Groups (cgroups) et la commande docker system info --format '{{ .CgroupVersion }}-{{.CgroupDriver }}'. Les données peuvent alors être extraites des fichiers (cpu|io|memory).statde chaque conteneur.
Cela n'est toutefois pas pratique à utiliser si l'on désire un monitoring en temps réel. Une option plus réaliste est d'utiliser cadvisor qui collecte et expose des métriques concernant le système, les VM et les conteneurs.
API de métriques du daemon Docker
Une autre source de métriques est fournie par le démon dockerd lui-même. Pour cela, il est nécessaire d'activer le service dans le fichier daemon.json de Docker :
{
/* ... */
"metrics-addr": "127.0.0.1:9323",
"experimental": true,
/* ... */
}
Il est alors possible d'accéder à ces métriques via une API REST curl -s http://127.0.0.1:9323/metrics.
Note : Il existe d'autres outils comme
ctopqui permettent d'obtenir des informations en temps réel sur les conteneurs exécutés sur un hôte.#!/bin/bash ctop() { docker run --rm -it --name=ctop -v /var/run/docker.sock:/var/run/docker.sock quay.io/vektorlab/ctop } ctop
Monitoring avec Prometheus et Grafana
Il ne reste plus qu'à assembler nos deux sources principales de métriques que sont cadvisor et l'API de métriques de Docker. La solution la plus utilisée pour cela est Prometheus couplé à l'outil de visualisation de données Grafana.
La configuration de Prometheus se fait à travers un fichier prometheus.yml :
# prometheus.yml
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_configs:
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'docker'
static_configs:
- targets: ['<ip-du-serveur-docker-à-monitorer>:9323']
- job_name: 'cadvisor'
static_configs:
- targets: ['<ip-du-serveur-docker-à-monitorer>:8081']
Il faut également déclarer Prometheus comme source de données pour Grafana :
# datasources/prometheus_ds.yml
datasources:
- name: Prometheus
access: proxy
type: prometheus
url: http://prometheus:9090
isDefault: true
Le déploiement des différents services se fait alors via un fichier Docker compose :
# docker-compose.yml
version: '3.9'
networks:
default:
name: monitoring
volumes:
prometheus_data:
grafana_data:
services:
prometheus:
image: prom/prometheus
ports:
- published: 9090
target: 9090
protocol: tcp
volumes:
- type: bind
source: ${PWD}/prometheus.yml
target: /etc/prometheus/prometheus.yml
- type: volume
source: prometheus_data
target: /prometheus
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.retention=72h
networks:
- default
cadvisor:
image: gcr.io/cadvisor/cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
command: -logtostderr -docker_only
networks:
- default
grafana:
image: grafana/grafana
ports:
- 3000:3000
restart: unless-stopped
volumes:
- ${PWD}/datasources:/etc/grafana/provisioning/datasources
- grafana_data:/var/lib/grafana
networks:
- default
Ce fichier déploie Prometheus, cadvisor et Grafana.
Plugins de Grafana
La mise en place du monitoring d'un swarm Docker n'est pas une tâche très compliquée, mais elle est relativement complexe du fait du nombre de service à intégrer et, surtout, du nombre de plugins disponibles pour Grafana ! Trouver le plugin le plus adapté à ses besoins peut-être une tâche longue et fastidieuse faite d'expérimentation et d'essais et erreurs. Il faudra également dans de nombreux cas modifier la configuration de Prometheus et/ou ajouter d'autres sources de données pour Grafana.
Une option est l'utilisation d'une solution clé en main telle que swarmprom ou vegasbrianc/prometheus. Ces solutions sont hélas souvent non mises à jour, mais elles peuvent servir de base à la mise en place du monitoring.
Agrégation des logs
Pour ce qui est de l'agrégation des logs, Docker intègre directement Graylog via le driver gelf1.
{
"log-driver": "gelf",
"log-opts": {
"gelf-address": "udp://1<remote_address>:<remote port>"
}
}
Son intégration à l'infrastructure mise en place par USSI ne devrait donc poser aucun problème.
Étude de solution pour résoudre le problème du partage de données entre les noeuds du cluster
Actuellement, le partage des données de runtime entre les noeuds du swarm se fait grâce au partage NFS d'un volume depuis le manager1 du cluster. Cela permet de très bonnes performances lors des builds, mais l'indisponibilité du manager1 provoquera l'indisponibilité de tous le swarm. Cette solution bien que fonctionnelle n'est pas tellement désirable en production. Ce problème peut être mitigé par la mise en place de mesures en concertation avec l'équipe système :
- le déplacement du manager 1 vers un autre Data Center lors des interventions planifiées
- une procédure pour réinstancier rapidement le manager 1 en cas de crash
- un monitoring méticuleux de l'infrastructure afin de détecter rapidement une indisponibilité
De plus le temps limité nécessaire à la ré-instanciation du manager 1 limite la durée d'indisponibilité des services.
Note: cette situation n'est pas spécifique à mon infrastructure. En effet, la situation serait la même en cas de perte de la plateforme Ceph Gateway qui permet le partage NFS dans les Data Centers, mais avec un plus gros impact puisque c'est l'ensemble des infrastructures applicatives qui dépendent de NFS qui tomberaient (Portail, Moodle...)
Afin de résoudre ce point de rupture, plusieurs solutions peuvent être appliquées selon le type de données.
Docker lui-même fournit des solutions pour stocker et partager les données entre ses conteneurs :
- Données purement statiques pourraient être copiées dans l'image Docker d'une application, mais dans ce cas, le fichier Dockerfile devra être écrit correctement afin d'éviter la reconstruction inutile de layers.
- Les fichiers de configurations peuvent être mis à disposition via la commande
docker config - Les fichiers contenant des données confidentielles (clés, certificats, credentials...) peuvent être rendues disponibles de manière sécurisée via la commande
docker secret - Les données internes générées au runtime par les conteneurs ou durant le build des images peuvent être mises à disposition via des volumes Docker (commande
docker volume)
Ces méthodes permettent d'isoler les données et de ne les rendre accessibles qu'aux seuls conteneurs. Toutefois, cela signifie qu'il est impossible par exemple de modifier en temps réel ces données depuis l'hôte. Or, dans certains cas, ce type de modification est nécessaire afin d'éviter de passer par des opérations longues telles que le build d'images, la copie de fichier dans un volume depuis un conteneur...
Il existe également de nombreuses solutions en dehors de Docker. En voici quelques unes :
- Pour des données où les performances ne sont pas un problème et où l'indisponibilité du volume a peu d'impact, un montage NFS (par exemple depuis le Ceph Gateway de SIPR) est envisageable. Remarquons que le montage NFS peut se faire soit via Docker lui-même, pûisqu'il fournit un driver NFS pour ses volumes, soit directement sur l'hôte en montant un répertoire local dans les conteneurs Docker.
- Pour des données où la redondance et la résistance à un crash sont importantes, une solution comme GlusterFS ou CephFS peuvent être indiquées.
- Pour les données modifiées rarement (exemple uniquement en cas de mise à jour), on pourrait imaginer d'utiliser un mécanisme de synchronisation de système de fichier tel que rsync. Toutefois cette solution requiert un mécanisme d'automatisation pour être vraiment efficace.
Comparaison de solutions de stockage redondant
Solution Performances Redondance Temps réel NFS depuis le manager 1 + - oui GlusterFS - + oui NFS via Ceph Gateway - - oui Synchro via rsync - + non Chacune de ces solutions est indiquées pour certains types d'application :
- NFS depuis la machine de build : infrastructures non critiques où les performances d'écriture sont importantes, en production uniquement s’il est possible de garantir la stabilité et la disponibilité du serveur NFS
- Gluster FS : infrastructure avec N managers, petit nombre de fichier à écrire, ne convient pas si les performances d'écriture sont essentielles
- NFS via Ceph Gateway : production ou performances d'écriture non essentielles
- CephFS : plutôt destiné à des grosses infrastructures, à étudier avec SIPR
- Synchronisation via rsync : uniquement pour les fichiers read-only et lors de l'install; nécessite l'espace disque suffisant sur tous les hôtes
Stockage de fichier redondant avec GlusterFS
Afin d'étudier la possibilité d'ajouter un stockage redondant sur mon infrastructure, j'ai mis en place une petite infrastructure de démonstration avec GlusterFS.
Note: Cette infrastructure n'a au final pas été mise en place car ses performances sont identiques à celles du Ceph Gateway de SIPR pour l'écriture d'un grand nombre de petits fichiers, ce qui la rendait inutilisable pour certaines applications complexes.
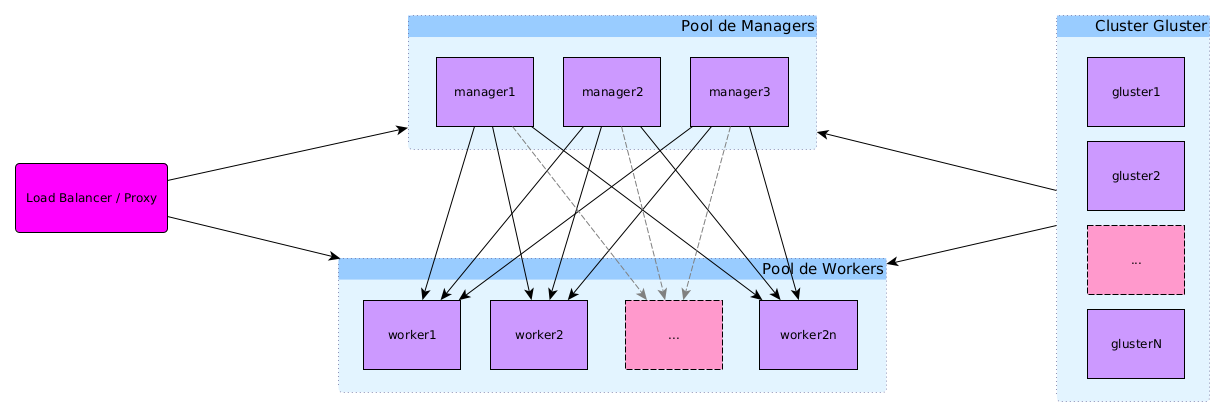
Nombre de noeuds
Le nombre minimum de noeud pour un cluster de production est de 3 afin d'éviter les problèmes de "split-brain", c'est-à-dire une incohérence sur l'état du cluster entre les différents noeuds. Dans mon cas, je me suis toutefois limité à 2 noeuds puisqu'il s'agissait uniquement d'un test.
Installer et configurer un cluster glusterfs (Debian 11)
Sur chaque noeud :
sudo apt install glusterfs-server
sudo systemctl start glusterd
sudo systemctl enable glusterd
Note : toutes les commandes suivantes s'effectuent en tant que
rootou viasudo.
Modifier /etc/hosts pour ajouter les nœuds du cluster sur chaque nœud :
## gluster node 1
127.0.0.1 localhost gluster01
<IP GLUSTER NODE 2> gluster02
...
<IP GLUSTER NODE N> glusterN
Enregistrer les nœuds (sur le premier nœud uniquement) :
gluster peer probe gluster02
## ...
gluster peer probe glusterN
Vérifier le statut avec gluster peer status et lister les noeuds dans le pool avec gluster pool list :
gluster pool list
UUID Hostname State
da6f41b1-a3e5-4015-b37e-a08a8e40f5ff gluster02 Connected
b9647657-67ad-4cdf-84cc-532bbc0009ec gluster03 Connected
bb3d1da6-a6fb-4ccb-89af-cae71b326c07 localhost Connected
Volume répliqué avec Gluster
Créer un volume glusterfs répliqué (exemple)
## /data doit être un stockage hors du system root
sudo mkdir -p /data/glusterfs/vol-1/brick
## si /data est dans le système root il faut ajouter force (pour des besoins de test par exemple)
sudo gluster volume create vol-1 replica 3 gluster01:/data/glusterfs/vol-1/brick gluster02:/data/glusterfs/vol-1/brick gluster03:/data/glusterfs/vol-1/brick
sudo gluster volume start vol-1
Test sur tous les hôtes
sudo mkdir -p /mnt/vol-1
sudo mount -t glusterfs gluster01:vol-1 /mnt/vol-1
Pour ajouter dans
/etc/fstab:sudo vim /etc/fstab ## ajouter gluster01:/vol-1 /mnt/vol-1 glusterfs defaults,_netdev 0 0 ## monter les volumes mount -a
Reste encore à gérer les droits d'accès sur le montage :
- Version hardcore :
sudo chmod ugo+rwx /mnt/vol-1 - Version avancée : utiliser les acl POSIX comme pour NFS
Nettoyer après les tests :
## sur tous les hôtes
sudo umount /mnt/vol-1
## sur gluster01
sudo gluster volume stop vol-1
sudo gluster volume delete vol-1
Montage via /etc/fstab et performances pour la production
Les options par défaut de glusterfs sont insuffisantes pour la production.
Au niveau des volumes gluster, les variables de performances sont :
- performance.write-behind-window-size – the size in bytes to use for the per file write behind buffer. Default: 1MB.
- performance.cache-refresh-timeout – the time in seconds a cached data file will be kept until data revalidation occurs. Default: 1 second.
- performance.cache-size – the size in bytes to use for the read cache. Default: 32MB.
- cluster.stripe-block-size – the size in bytes of the unit that will be read from or written to on the GlusterFS volume. Smaller values are better for smaller files and larger sizes for larger files. Default: 128KB.
- performance.io-thread-count – is the maximum number of threads used for IO. Higher numbers improve concurrent IO operations, providing your disks can keep up. Default: 16.
Source : https://www.jamescoyle.net/how-to/559-glusterfs-performance-tuning
Elles peuvent être configurées via le client CLI de gluster :
gluster volume set [VOLUME] [OPTION] [PARAMETER]
Exemple:
gluster volume set myvolume performance.cache-size 1GB
Ou dans le fichier de configuration /etc/glusterfs/glusterfs.vol.
Les options à indiquer dans /etc/fstab sont :
<GLUSTER HOST>:<VOLUME> <MOUNT PATH> glusterfs defaults,direct-io-mode=disable,_netdev 0 0
Configuration afin d'améliorer les performances
gluster volume set vol-1 client.event-threads 32 ## was 2
gluster volume set vol-1 server.event-threads 32 ## was 2
gluster volume set vol-1 features.cache-invalidation on ## was off
gluster volume set vol-1 features.cache-invalidation-timeout 600 ## was 60
gluster volume set vol-1 performance.cache-invalidation on
Consensus et Glusterfs
Comme pour Docker Swarm, un nombre paire de répliques de volumes peuvent causer un "split-brain", c'est-à-dire une situation dans laquelle aucun consensus ne peut être trouvé pour l'état du volume. Il est conseillé d'avoir un nombre impair de noeuds (minimum 3) pour Glusterfs.
https://docs.gluster.org/en/latest/Troubleshooting/resolving-splitbrain/
Schéma de l'infrastructure avec le cluster Gluster
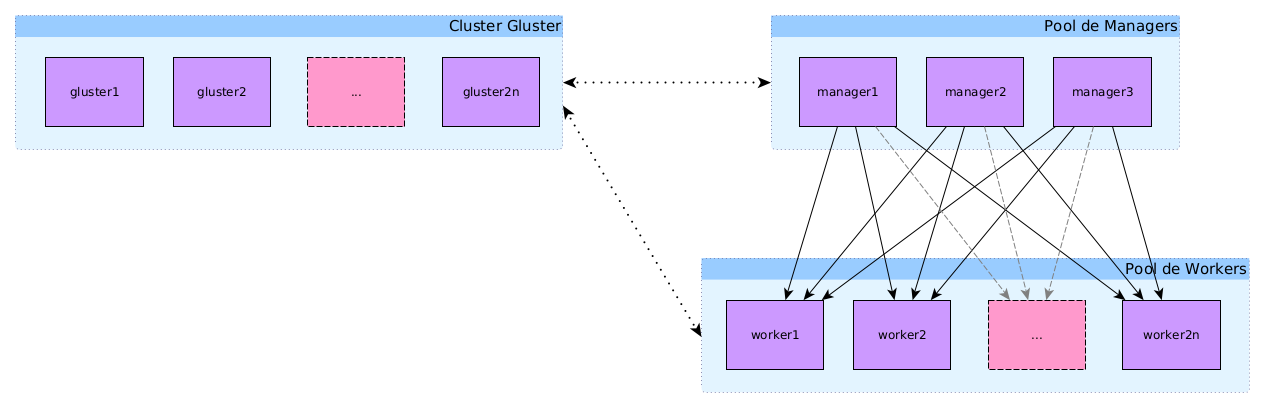
Conclusion
Après plusieurs tentatives infructueuses et la consultation de plusieurs sources, il s'avère que l'utilisation de GlusterFS ne convient pas pour l'écriture d'un grans nombre de petits fichiers. Or, de nombreuses applications PHP modernes utilisent le gestionnaire de paquets composer et vont donc dépendre d'un très grand nombre de tels petits fichiers qui devront être partagés entre les hôtes du cluster.
A titre d'exemple, une installation de Drupal compte plusieurs dizaines de milliers de fichiers ! Cela exclut GlusterFS pour ce type d'application et donc pour mon infrastructure.
Synchronisation via Rsync
Une autre possibilité envisageable dans certains cas est de synchroniser les fichiers source de l'application via rsync après récupération du code source. Une automatisation pourrait être mise en place afin de synchroniser tout changement automatiquement. Ce système très simple et performant ne gère cependant pas les problèmes d'accès concurrent sur les fichiers durant la synchronisation.
Autres solutions envisageables
Après discussion avec l'équipe SIPR, d'autres solutions pourraient être étudiées dans le futur :
- DRBD + GFS2
- CephFS
Autres points d'attention
- Registry centralisé et sécurisé (option celui de gitlab --> permet ci/cd)
- Build via gitlab-ci + scan des images construites
- Sécurisation de la connexion au démon Docker
- Backup : Docker et Baccula
- Intégration à l'infrastructure SIPR : Docker et Open Nebula
- Stockage redondant, quelles solutions ?
- Docker Swarm et le cloud Azure ?
- Passage à Kubernetes
Vers une infrastructure de production
Même si elle pourrait être déployée en production telle quelle, l’infrastructure proposée présente encore quelques problèmes à traiter.
- le point de rupture constitué par la machine manager qui héberge l’orchestrateur et le stockage de fichiers partagé
- la mise à jour des images afin de garantir une sécurité optimale des applications
- l’automatisation de la mise à jour des machines hôtes
Docker Swarm en production
Reste bien dans la course, mais peut-être moins adapté à des infrastructures de grande taille. Néanmoins, il a l'énorme avantage de la facilité de déployer des applications disponibles pour Docker Compose (c'est à dire de nombreuses applications !).
L'infrastructure décrite dans mon brevet pourrait toutefois être facilement industrialisable, par exemple pour l'hébergement web.
Une infrastructure de ce type devrait avoir
- plusieurs nœuds managers : 3 semble un bon compromis entre redondance et performance, mais l'idéal est d'avoir un manager au moins dans chaque Data Center
- un plus grand nombre de nœuds workers
Un registry centralisé
Pourquoi ? Un registry centralisé pourrait avoir de nombreux avantages :
- éviter de devoir construire les images sur chaque infrastructure
- avoir des images à jour
- permettre de forcer la mise à jour des images des services afin de garantir la sécurité
Une solution simple est d'utiliser le registry intégré à Gitlab afin d'assurer la centralisation des images et l'interopérabilité avec Gitlab.
Résoudre le point de rupture du manager
Le point faible de notre infrastructure : le manager et le système de fichiers partagé sont sur une seule et même machine sans redondance. En cas d’indisponibilité de cette machine tout le système s’écroule.
La perte du manager provoque actuellement un downtime de l’ensemble de l’infrastructure car
- On perd la machine qui assure la gestion du cluster. Ce problème peut-être résolu en multipliant le nombre de machine manager et assurer ainsi la redondance. Toutefois, le nombre de machine manager nécessaire est imposé par l'implémentation de l’algorithme de consensus entre les nœuds manager 23.
- On perd le partage système de fichiers NFS entre les nœuds du cluster. Si le manager tombe, les workers perdront donc l'accès à leurs données. Une solution possible est le montage d’un file system partagé depuis le stockage Ceph de SIPR, soit en utilisant NFS (mais nos tests à ce sujet ont mis en évidence des pertes sensibles de performances et ont justifié le partage du file system depuis le manager), soit en passant à un protocole de partage mieux adaptés aux conteneurs comme par exemple GlusterFS4.
Il faudra donc mettre en place une redondance et un fail over soit au niveau du manager, soit au niveau du montage partagé lui-même. Cette question sera abordée plus en détail dans le chapitre des perspectives consacré à la mise en place d’une infrastructure de production.
Solutions testées à ce jour :
- Export NFS depuis un manager : très performant, pas de redondance, perte du cluster en cas de perte du manager
- Export NFS depuis un cluster Ceph : peu performant, pas de redondance, perte du cluster en cas de perte du serveur NFS
- Cluster GlusterFS : peu performant, redondant, ne convient pas pour les builds
A tester :
- Utiliser un répertoire local et utiliser rsync pour synchroniser entre machine : pas temps réel, peu performant
Mise à jour des images et services : la livraison continue appliquée à l’infrastructure
La mise à jour (automatique) des images et le rafraîchissement des services : la livraison continue appliquée à l’infrastructure.
Une manière de résoudre cela est d’automatiser le build des images en utilisant un pipeline Jenkins.
Source : https://blog.nimbleci.com/2016/08/31/how-to-build-docker-images-automatically-with-jenkins-pipeline/
Vers une infrastructure basée sur Kubernetes et Rancher
De « Docker Swarm is dead ? » à « Kubernetes will drop Docker support ! » : (r)évolutions et troubles dans le petit monde des conteneurs
Plusieurs annonces récentes posent question quant à l’avenir de la solution proposée dans ce brevet :
- Fin 2019, la maintenance de l’orchestrateur Docker Swarm annoncée jusque fin 2022 qui laissait penser à un abandon de cette solution suite au rachat de Docker Enterprise par Mirantis et de nombreuses rumeur annoncaient même la mort de Docker Swarm567
- Début 2020, toutefois, l’annonce de la continuation du développement et du support de Docker Swarm par Mirantis8 est venue contredire les rumeurs de fin 2019
- Fin 2020, l’annonce de l’abandon du support du moteur Docker par Kubernetes au profit d’autres solutions respectant la spécification CRI (Container Runtime Interface)9 10 est venue semer le trouble dans le petit monde des conteneurs. De son côté, la société Mirantis a annoncé dans les semaines suivantes qu'elle continuerait le développement d'une version compatible avec la spécification CRI de l'interface Docker pour Kubernetes.
- Depuis 2022, l'abandon de Docker au profit de containerd dans Kubernetes est effectif.
À ce stade, l’infrastructure mise en place dans le présent projet n’est pas directement menacée par ces bouleversements, et elle reste parfaitement indiquée tant pour l’infrastructure webpps que pour son utilisation pressentie pour le futur portail web de l'UCLouvain.
Toutefois, Docker Swarm présente quelques limitations par rapport à Kubernetes pour une utilisation sur des infrastructures à plus grande échelle. En particulier, il n’est pas compatible avec autant de solution d’hébergement cloud que Kubernetes et ses dérivés.
Ce chapitre s’intéressera donc à quelques considérations importantes en vue d’un passage à une infrastructure basée sur Kubernetes.
L’écosystème Kubernetes
De nombreuses solutions existent pour la gestion de cloud] que cela concerne les environnements d’exécution, les orchestrateurs, les stockages ou encore le provisioning… La CNCF (Cloud Native Computing Foundation) dresse un portrait de toutes ces solutions11. Parmi celles-ci, les plus représentées font partie de l’écosystème Kubernetes.
Kubernetes a été initialement développé par Google et est soutenu par les gros acteurs du monde Linux dont RedHat, Ubuntu, la Apache Foundation… C’est aujourd’hui le leader des orchestrateurs de conteneurs basés sur Docker.
Il a l'avantage de reposer et de proposer une série d’API et de spécifications standardisées qui ont permis l'émergence d'une grande quantité de solution compatibles et d’orchestrateurs alternatifs.
Kubernetes est un système extrêmement personnalisable, en particulier via ses 3 définitions d’interface :
- Container Network Interface (CNI) : spécifie les interfaces réseaux utilisables par Kubernetes (p. ex. Calico, Flannel ou Canal)
- Container Runtime Interface (CRI) : spécifie l'interaction avec l’environnement d’exécution des conteneurs et intègre complètement les standards Open Container Initiative (OCI) (par exemple cri-conbtainerd, cri-o ou encore frakti)
- Container Storage Interface (CSI) : spécifie les volumes utilisables comme stockage de Kubernetes
Kubernetes et Docker
Bien qu’il soit une solution concurrente via Docker Swarm, Docker a été utilisé comme environnement d’exécution de conteneurs par défaut de Kubernetes depuis le départ.
Kubernetes en collaboration avec les acteurs liés au développement de plusieurs environnements d'exécution de conteneurs (Core OS, Hyper, Google…) a défini une API pour l’utilisation des conteneurs et la définition des images : la spécification CRI (Container Runtime Interface).
Plusieurs implémentations de cette API ont vu le jour dont les 2 principales sont CRI-Containerd (implémentation au-dessus de containerd) et CRI-O (pour les environnements compatibles avec les standards de l’Open Container Initiative).
De son côté, Docker n’est pas compatible directement avec la spécification CRI et est connecté à Kubernetes via une couche supplémentaire appelée dockershim. Mais, depuis la mise en place de CRI-Containerd, Docker (lui-même construit au-dessus de containerd) constitue aujourd’hui une surcouche inutile entre Kubernetes et containerd.
Tout cela a amené Kubernetes à abandonner le support de dockershim et, par extension, de Docker lui-même auprofit de containerd.
Kubernetes versus Docker Swarm
Kubernetes est plus perfectionné et plus complet que Docker Swarm. Il est également beaucoup plus flexible puisqu’il permet d’utiliser d’autres moteurs de conteneurs que Docker.
Permet une plus grande configuration des ressources allouées aux conteneurs.
Vocabulaire : service vs pod
Les solutions d’orchestration pour Kubernetes
Il existe de nombreuses implémentations de l'orchestrateur Kubernetes spécialisées selon l'usage qui en est attendu :
| Produit | Types | Éditeur | Description |
|---|---|---|---|
| Kubernetes | dev, prod | Kubernetes | Implémentation officielle via les services kubeadm, kubelet et kubectl. Extrêmement puissante mais, en conséquence, assez difficile à prendre en main. Plutôt destinée à de grosses infrastructures. |
| Minikube | dev | Kubernetes | Orchestrateur destinés aux développeurs et permettant le déploiement d'un cluster local pour tester le déploiement d'applications. Pas adapté à une infrastructure de production. |
| Microk8s | dev, prod | Canonical | Orchestrateur léger maintenu par Canonical. Il était au départ destiné au développement et à l'IoT, mais il convient également aux infrastructures de production. |
| Rancher | prod | Rancher | Orchestrateur complet et performant destiné à des infrastructures de production via le RKT (Rancher Kubernetes Toolkit). |
| OpenShift | prod | RedHat | Plateforme complète destinée à la mise en place d'un cloud kubernetes d'entreprise12. |
| Kind | dev | kind | Alternative à minikube et microk8s pour le test local d'un cluster kubernetes |
| Podman | dev, prod | RedHat | Alternative à Docker et orchestrateur pour Kubernetes |
Il existe d’autres solutions, mais elles sont moins répandues que celles citées ci-dessus. Ajoutons que des solutions de gestion de cloud intègre parfois la gestion de conteneurs, par exemple OpenNebula.
Les deux candidats les plus appropriés pour une infrastructure du type de celle étudiée ici sont Rancher et Microk8s.
- Microk8s a l’avantage de pouvoir fonctionner tant sur la machine d’un développeur que pour le déploiement sur une infrastructure cloud ou pour le déploiement sur des devices IoT.
- Rancher pour sa part est simple à mettre en œuvre, mais requiert un outil supplémentaire ou d’installer Rancher en local (ce qui n’est pas nécessairement évident à faire) pour tester les déploiements sur une machine de développement (par exemple minikube ou kind).
De son côté, Kubernetes est plus complexe et plus lourd à mettre en oeuvre. Comme Rancher, il requiert un outil supplémentaire pour les développeurs. Quant à OpenShift son cadre d’application est celui d’un cloud d’entreprise.
Des outils supplémentaires :
- Helm : permet la gestion des applications Kubernetes via un format de paquets appelé Charts et intégrant la gestion des dépendances, la dépréciation, la gestion des sources…
- Terraform : outil permettant la gestion du déploiement d’infrastructure comme du code via son propre langage de déclaration (également compatible avec Docker, et avec les clouds Azure et Amazon)
- Harbor : registre d’applications pour Kubernetes
Rancher : Kubernetes-as-a-service
Rancher est l’un des orchestrateurs Kubernetes les plus utilisés. Il est relativement simple à installer et à prendre en main. C’est de plus une solution qui se prête bien aux petites ou moyennes infrastructures. Il est de ce fait plus adapté pour l'infrastructure visée par ce brevet que OpenShift ou Kubeadm.
La principale limitation de Rancher est qu’il n’est pas officiellement supporté sur toutes les distributions Linux (le site de Rancher fournit une liste des versions supportées). En particulier, il n’est pas officiellement supporté sous Debian13.
Cela ne constitue toutefois pas un problème dans le cadre de l'UCLouvain puisque plusieurs distributions compatibles sont disponibles dans l'infrastructure de SIPR. On pourrait par exemple faire le choix d’une distribution Ubuntu LTS qui est dérivée de Debian et utilise donc les mêmes outils.
Outils :
- Rancher : une interface web
- Rancher CLI : outil de gestion en ligne de commande
- Rancher API Server : ensemble de services web pour la gestion du cluster
- Rancher Agent : agent de contrôle des nœuds du cluster
- Rancher Kubernetes Engine (RKE) : distribution Kubernetes légère et performante intégrée à Rancher et conçue pour s’exécuter dans des conteneurs
Vers la mise en place d’un cloud d’entreprise basé sur les conteneurs dans l'infrastructure SIPR
Voici finalement quelques pistes pour améliorer la prise en charge de Docker dans l'infrastructure système de SIPR.
Docker, Kubernetes et Rancher dans Open Nebula
Tout d'abord, Open Nebula, le logiciel de gestion d'infrastructure utilisé par SIPR, permet d’intégrer Docker et Kubernetes14 et, depuis la version 5.12, Open Nebula prévoit l’intégration de Rancher15.
Voir aussi :
- OpenNebula Kubernetes Appliance : https://docs.opennebula.io/appliances/service/kubernetes.html
- OpenNebula Docker Appliance : https://docs.opennebula.io/appliances/service/docker.html
Backup et conteneurs
Au niveau des backups, Bacula Enterprise, la solution utilisée pour l’infrastructure UCLouvain, propose des solutions de backup et restauration pour les conteneurs :
- Docker Container Backup and Restore https://www.baculasystems.com/docker-container-backup/
- How to Backup and Restore Docker Containers with Bacula Enterprise? https://www.baculasystems.com/how-to-backup-and-restore-docker-containers-with-bacula-enterprise/
- Kubernetes Backup and Restore https://www.baculasystems.com/kubernetes-backup-restore/
- How to Backup and Restore or Migrate a Kubernetes Cluster? https://www.baculasystems.com/how-to-backup-and-restore-kubernetes-clusters/
Vers une intégration des conteneurs dans l'infarstructure SIPR ?
Il est donc tout à fait possible d'intégrer directement les conteneurs dans les pratiques actuelles de SIPR. Toutefois ces outils demandent encore à être testés afin de montrer les adéquations avec les demandes de conteneurs à l'UCLouvain.
Graylog Extended Format logging driver https://docs.docker.com/config/containers/logging/gelf/
L’algorithme utilisé est RAFT, pour plus de détails, voir la page « Raft consensus in swarm mode » de la documentation Docker https://docs.docker.com/engine/swarm/raft/
Les règles concernant le nombre de nœuds manager nécessaire pour garantir le quorum sont définies dans le guide d’administration et de maintenance de Docker Swarm https://docs.docker.com/engine/swarm/admin_guide/
Voir par exemple « Tutorial: Create a Docker Swarm with Persistent Storage Using GlusterFS » https://thenewstack.io/tutorial-create-a-docker-swarm-with-persistent-storage-using-glusterfs/
La fin du support de Docker swarm avait été annoncée pour 2022. Sauf reprise par la communauté ou une société tierce, cela aurait marqué la mort de ce produit. Toutefois la société Mirabilis a par la suite annoncé qu'elle continuerait le développement de Swarm.
What We Announced Today and Why it Matters, November 13, 2019 https://www.mirantis.com/blog/mirantis-acquires-docker-enterprise-platform-business/
Notons que la fin de Docker Swarm est une rumeur qui revient souvent dans les discussions depuis au moins 2017 https://www.bretfisher.com/is-swarm-dead-answered-by-a-docker-captain/
Mirantis will continue to support and develop Docker Swarm (24/02/2020) https://www.mirantis.com/blog/mirantis-will-continue-to-support-and-develop-docker-swarm/
« Don't Panic: Kubernetes and Docker » https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/
« Kubernetes (Sorta) Drops Docker Support: It's Not as Bad It Sounds » https://www.cbtnuggets.com/blog/devops/kubernetes-sorta-drops-docker-its-not-as-bad-it-sounds
CNCF Cloud Native Interactive Landscape https://landscape.cncf.io/
What is OpenShift? https://www.openshift.com/learn/what-is-openshift
En pratique, il est tout à fait possible d’installer Rancher sous Debian.
Documentation d’OpenNebula, Docker and Kubernetes http://docs.opennebula.io/5.12/advanced_components/applications_containerization/index.html
Intégration de Rancher dans la documentation d’OpenNebula http://docs.opennebula.io/5.12/advanced_components/applications_containerization/rancher_integration.html
Kubernetes dropping Docker runtime support – what it means for enterprises (10/12/2020) https://www.avenga.com/magazine/kubernetes-dropping-docker/
Conclusion
Presque 10 ans ! C'est le temps qu'il m'aura fallu pour enfin terminer mon brevet principal. Après un premier projet avorté qui avait pour thème le développement agile dans le projet Portail, j'ai finalement abouti à quelque chose que je pense être « montrable » avec cette infrastructure Docker Swarm.
J'ai en tous cas beaucoup appris lors de la réalisation de ce brevet et il y a encore énormément de choses que j'aurais aimé aborder et expérimenter (les contextes Docker qui permettent de contrôler plusieurs environnements Dockerdepuis une même machine, les labels sur les noeuds du Swarm pour une gestion plus fine du cluster et des déploiements, la manière dont Docker et Docker Swarm ont accéléré le développement du Portail UCLouvain...). Mais à un moment, il a bien fallu faire des choix sans quoi ce document n'aurait jamais été terminé.
J'ai aussi exploré des pistes que j'ai dû abandonner, mais dont j'ai laissé le contenu en annexe car elles pourraient servir à d'autres équipes.
Accomplissements
La mise en place de mon infrastructure de démonstration et sa duplication pour différents projets ont montré que des infrastructures basées sur Docker Swarm tenaient la route que ce soit pour du développement (projet Portail) ou de la production (bibliothèques et bientôt le Portail). Pour ma part, j'utilise Docker et Docker Swarm sur ma machine locale pour la quasi-totalité de mes projets de développement ou de déploiement.
Je pense avoir montré que Docker Swarm est un environnement à la fois puissant et simple à mettre en place et à utiliser. Ses possibilités sont énormes depuis le déploiement sur la machine locale d'un développeur, jusqu'au cluster multi-noeud, et depuis l'hébergement d'applications web jusqu'aux pratiques CI/CD.
Docker et les conteneurs s'intègrent de plus parfaitement dans les pratiques agiles ou les cycles de livraison court, et simplifient la déploiement, la maintenance et la mise à jour des infrastructures. Ils permettent un partage de pratiques et d'outils depuis les développeurs jusqu'aux équipes de production. Les fichiers de déploiement de piles applicatives permettent une grande souplesse et la déclinaison d'une même pile applicative sur différents environnement de production.
Difficultés rencontrées
J'aimerais dire un petit mot concernant les difficultés que j'ai rencontrées durant ce projet.
Outre la crise COVID ou les difficultés rencontrées dans le projet Portail, qui ont fortement impacté mon travail sur ce brevet et sur lesquels je ne m'étendrai pas, d'autres éléments plus spécifiques ont contribué à retarder la réalisation de mon projet.
Tout d'abord, la mise en place d'un cluster de test avec Vagrant, bien que très intéressante d'un point de vue technique (voir Annexes), s'est révélée plus compliquée que je ne l'avais anticipé. Heureusement, la possibilité de déployer un Swarm Docker sur ma machine locale a débloqué la situation et m'a permis de rattraper rapidement le temps perdu.
Les bouleversements qui ont touché le monde de Docker en 2019 m'ont durant un temps fait envisager l'abandon de Docker au profit d'une autre technologie comme Rancher ou Kubernetes. Cette situation était d'autant plus problématique que j'avais déjà bien avancé sur la piste Docker Swarm et que la mise en place d'un banc de test local pour Kubernetes s'est révélée des plus ardues. En effet, une grande partie des tutoriels et de la documentation que j'ai pu trouver ne fonctionnait tout simplement plus avec les dernières versions de ces technologies ! Après quelques semaines perdues sur cette piste, la fin de la période de doute autour de la survie de Docker Swarm a finalement débloqué la situation et m'a permis de reprendre mon idée originale.
Toutefois, ces pertes de temps m'ont demandé de revoir une partie de mon document (en particulier la mise en place de mon infrastructure de démonstration), tant les technologies que j'utilise évoluent rapidement et avaient rendu une partie de mon travail obsolète.
Heureusement, et malgré quelques longues périodes de doute, de découragement et de questionnement, j'ai pu mener ce projet à terme !
Améliorations
Il reste des améliorations à effectuer sur mon infrastructure pour la rendre 100% prête pour la production, mais celles-ci pourront être faites au fur et à mesure de son utilisation et des besoins.
La plupart d'entre elles ont été listées dans la section Perspective, mais je pense important de revenir ici sur les principales.
Le premier point qu'il reste à résoudre est le plus important : il s'agit de la question du stockage redondant. En effet, à ce stade, l'export du système de fichier via NFS depuis l'un des managers constitue un "single point of failure" pour l'infrastructure. Je n'ai pas encore trouvé d'alternative offrant des performances suffisantes pour l'écriture des fichiers. Une piste serait l'utilisation de Ceph FS, mais les tests demandent la mise en place d'un cluster Ceph qui aurait pris trop de temps dans le cadre de ce brevet.
Un autre point concerne la gestion des images Docker et le registre qui les stocke. Dans une infrastructure de production, il est indispensable d'avoir un plus grand contrôle sur les images Docker déployées et exécutées. En particulier, la mise à jour des images Docker est un enjeu crucial pour la sécurité. Des images trop anciennes peuvent en effet contenir des failles de sécurité mettant en danger l'ensemble de l'infrastructure. L'utilisation d'un registre centralisé couplés à des outils de CI/CD pour les images maison et à des outils de mise à jour automatique d'images (comme Watchtower) pour les images "officielles" pourraient constituer une piste de solution.
Un troisième point d'attention concerne les plages d'adresse IP pour les réseaux internes de Docker qui peuvent entrer en collision avec celles utilisées dans les Data Center. J'ai déjà eu une discussion avec SIPR à ce sujet et certaines plages d'adresse sont réservées pour Docker. Il faudra toutefois vérifier si ces plages sont suffisantes et configurer les infrastructures pour les utiliser.
Malgré ces points non résolus, je pense que mon travail constitue une bonne base sur laquelle de futures infrastructures pourront être construites.
L'avenir
Il faut également regarder vers le futur. Docker a été la technologie de conteneur la plus populaire durant de nombreuses années. Mais d'autres solutions, portées par des acteurs majeurs, s'imposent peu à peu comme des nouveaux standards, Kubernetes en tête. Des alternatives à Docker lui-même se développent, par exemple Podman qui est l'outil de référence pour le déploiement d'un cluster Ceph. Le cloud a également fortement transformé les pratiques avec des outils comme Terraform qui permettent de définir les infrastructures sur base de code (paradigme "infrastructure as code" dont j'ai déjà parlé). D'autres comme Open Shift intègre l'entièreté de la gestion d'un cloud d'entreprise dans une solution.
Il faudra donc suivre l'évolution du marché dans les années qui viennent pour voir quelles solutions s'imposeront.
Remerciements
Je tiens tout d'abord à remercier mon collègue Mike De Man avec qui j'ai pu explorer les possibilités offertes par Docker pour le portail UCLouvain et sans lequel ce brevet n'aurait peut-être pas existé. Un grand merci à mes collègues Laurent Dubois, Raphaël Lebacq, Laurent Grawet, Fabrice Charlier, Olivier Delcourt, ainsi que les membres du groupe de travail Docker que nous avons mis en place, et dont les apports ont enrichi mon travail.
Je tiens également à remercier François Micaux qui m'a conforté dans mes choix techniques lors de la formation Docker qu'il a animée pour les équipes du SGSI et qui m'a permis d'améliorer ma maîtrise de Docker.
Je remercie aussi mon coach Thomas Keutgen dont les conseils et le soutien m'ont permis de mener à bien ce brevet, ainsi que mon évaluateur Jean-Luc Martou pour ses encouragements à terminer mon projet.
Et bien entendu, je remercie Valérie qui m'inspire tous les jours.
Bibliographie et ressources
Livres
- Pierre-Yves Cloux, Thomas Garlot, Johann Kohler, Docker, 2ème édition, Dunod, 2019
- Rafał Leszko, Continuous Delivery with Docker and Jenkins, Packt Publishing, 2018
- Randall Smith, Docker Orchestration, Packt Publishing, 2017
- Jon Langemak, Docker Networking Cookbook, Packt Publishing, 2016
Supports de formation
- François Micaux, Formation Docker Base, support de formation, 2022
- François Micaux, Formation Docker Advanced, support de formation, 2022
Articles et magazines
- « Utilisez plusieurs versions de PHP sur un même serveur web », Sébastien Lamy, Linux Pratique n°115, Sept-Oct 2019, p 72
- « Docker est-il déjà obsolète ? », David Blaskow, Linux Magazine France n°229, Sept 2019, p 14
- « Conteneurs : LXC, gros plan sur les options avancées », Cédric Pellerin, Linux Pratique n°118, Mars-Avril 2020, p 38
- « Orchestration : Créez et déployez votre premier cluster avec Kubernetes », Guillaume Morini, Linux Pratique n°118, Mars-Avril 2020, p 46
- « Le DevOps dans le monde réel », Cédric Pellerin et Sidoine Pierrel, Linux Pratique n°118, Mars-Avril 2020, p 66
- Dossier « État du Cloud », DataNews n°3, 5 juin 2020
Vidéos
- « Below Kubernetes : demystifying container runtimes », Thierry Carrez, FOSDEM 2020, https://www.youtube.com/watch?v=MDsjINTL7Ek
Documentation et liens
Docker et Docker Swarm
- Documentation officielle Docker
- Docker Compose : https://docs.docker.com/compose/
- Swarm Mode : https://docs.docker.com/engine/swarm/
- Networking : https://docs.docker.com/network/
- Reference (API, CLI, Specifications) : https://docs.docker.com/reference/
- Tutoriels
- Docker for Beginners : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker101/
- Getting Started with Dockerfile : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker101/dockerfile/
- Creating a Private Registry : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker101/registry/
- Docker Networks : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker101/networking/
- Docker for Intermediates : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker201/
- Getting Started with Docker Compose : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker201/gettingstarted/
- Getting Started with Docker Swarm : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker201/swarm/
- Introduction to Docker Networking : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker201/networking/
- Docker et Ansible : https://docs.ansible.com/ansible/latest/collections/community/docker/docsite/scenario_guide.html
- Docker for Beginners : https://docker.github.io/get-involved/docs/communityleaders/eventhandbooks/docker101/
- Autres sites
- Docker Swarm Rocks : https://dockerswarm.rocks/
GlusterFS
- https://yallalabs.com/linux/how-to-create-a-replicated-glusterfs-volumes/
- https://blog.devgenius.io/replica-volume-in-glusterfs-b05324ce1b6f
- https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html/administration_guide/sect-creating_replicated_volumes
- https://yallalabs.com/linux/how-to-mount-a-glusterfs-in-a-client-machine/
- https://access.redhat.com/solutions/234033
- https://www.jamescoyle.net/how-to/559-glusterfs-performance-tuning
- Performances
- https://docs.gluster.org/en/latest/Administrator-Guide/Performance-Tuning/
- https://www.gluster.org/gluster-tiering-and-small-file-performance/
- https://www.jamescoyle.net/how-to/559-glusterfs-performance-tuning
Annexe 1 : Quelques considérations techniques sur Docker
- Configurer le proxy dans les fichiers Dockerfile
- Proxy, VIP de sortie et Rate Limit sur Docker Hub
- Quelques variables d'environnement de Docker
Configurer le proxy dans les fichiers Dockerfile
Ajouter les variables d'environnement au début du fichier Dockerfile :
# Set proxy
ENV http_proxy http://proxy.sipr.ucl.ac.be:889
ENV https_proxy http://proxy.sipr.ucl.ac.be:889
ENV no_proxy localhost,127.0.0.0,127.0.1.1,127.0.1.1,local.home
Alternativement cela peut être fait dans les fichiers docker-compose.yml, voici un exemple :
services:
<service_name>:
# ...
environment:
HTTP_PROXY: 'http://host:port'
HTTPS_PROXY: 'http://host:port'
NO_PROXY: 'localhost, 127.0.0.1'
# autres variables d'environnement ...
Proxy, VIP de sortie et Rate Limit sur Docker Hub
Il y a de plus une limite de 100 pulls par 6h pour un utilisateur anonyme. Le proxy risque donc d'assez vite atteindre cette limite.
Il faudra donc :
- le désactiver le proxy dès que les machines peuvent sortir via le port 80 et 443
- à terme prendre un abonnement https://www.docker.com/pricing/
- une fois le problème résolu, le proxy peut-être ré-activé
NB : une solution de proxy plus pérenne doit encore être mise en place côté SIPR
Le même problème peut également se poser avec la VIP de sortie de haproxy qui est unique pour tous les services situés derrière celui-ci. L'idéal serait d'avoir une VIP de sortie par projet afin d'éviter tout problème de type rate limit ou max connection sur des services tiers.
Configuration complète du daemon
{
"storage-driver": "overlay2",
"log-driver": "syslog",
"debug": false,
"metrics-addr" : "127.0.0.1:9323",
"experimental" : true,
"insecure-registries" : [ "<HOSTNAME DU REGISTRY>:5000" ]
}
Quelques variables d'environnement de Docker
DOCKER_HOST: chemin (url ou socket unix) utilisé pour se connecter à l'API de Docker. Par défaut, la valeur estunix://var/run/docker.sock. Autres protocoles supportés :tcp://<host>:portetssh://<user>@<host>(Docker 18.04+)DOCKER_API_VERSION: version de l'PI Docker utilisée sur l'hôte. Par défaut c'est la version la plus récente supportée par Docker-Py.DOCKER_TIMEOUT: timeout pour les appaels à l'APIDOCKER_CERT_PATH: chemin du répertoire contenant le certificat client, celui du CA, ainsi que la clé privée du clientDOCKER_SSL_VERSION: version SSl utiliséeDOCKER_TLS: sécuriser les connexions à l'API en TLS sans vérifier l'authenticité de l'hôte DockerDOCKER_TLS_VERIFY: sécuriser les connexions à l'API en TLS et vérifier l'authenticité de l'hôte Docker
Annexe 2: Première infrastructure de démonstration (2018)
- Description de l’infrastructure
- Utilisation de l’infrastructure de démonstration
- Mise en place de l’infrastructure
- Outils de monitoring
- Évolution de l’infrastructure au cours du temps
- Résolution de problèmes sur l’infrastructure
- Tous les conteneurs sont instanciés sur un seul des 2 workers
- Un seul replica du proxy des workers a été instancié
- Aucun conteneur ne se lance à part les conteneurs système (registry, portainer...)
- Le service du proxy des workers ne démarre pas
- Erreur 502 persistante
- Désactiver et réactiver un service
Note : Ce chapitre décrit la première infrastructure de démonstration et de développement basée sur Docker Swarm que j'ai mise en place. Cette démarche a depuis été remplacée par celle décrite au chapitre 3 lors de l'instanciation de la nouvelle infrastructure de démonstration de ce projet, et suite aux améliorations du moteur Docker et de mes compétences dans son utilisation.
Ce projet a énormément changer depuis la première version de l'infrastructure de démonstration mise en place en 2018-2019 détaillée en annexe :
- Intégration les nouvelles fonctionnalités offertes par les versions récente de Docker et en particulier au niveau du mode Swarm. Ces nouveautés simplifient énormément la gestion et la mise en place du cluster.
- Utilisation d'un registre docker privé non sécurisé afin d'éviter les difficultés liées à la mise en place du certificat SSL sur le cluster. Ce registre sera de plus complété par celui fourni par Gitlab afin d'assurer la centralisation des images.
- Abandon des configurations des services via systemd au profit des options de redémarrage des services intégrées à Docker Swarm et qui permettent plus de souplesse
- Abandon du proxy frontal nginx mis en place sur une machine virtuelle séparée au profit du load balancer Haproxy déployé par SIPR
Ancienne infrastructure "LVS" de 2018-2019
Ces infrastructures utilisent l'ancien load balancer de SIPR et nécessite des machines proxy supplémentaires.
Par exemple : infrastructure de démonstration de 2018-2019 et infrastructure de développement du portail de 2019
Nouvelle infrastructure "HAProxy"
Par exemple : seconde infrastructure de démonstration dckr.sisg et nouvelles infrastructures de développement, qa et production du portail
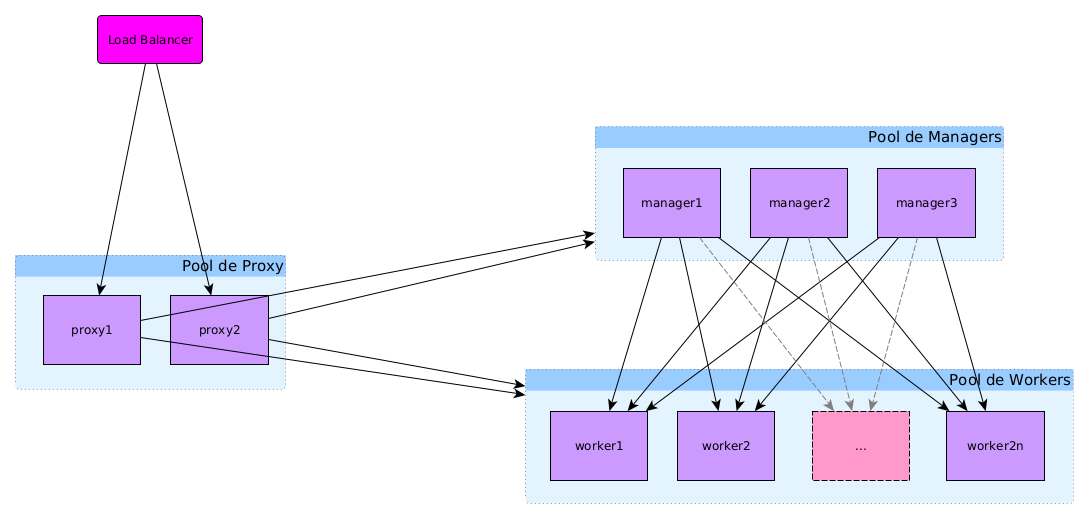
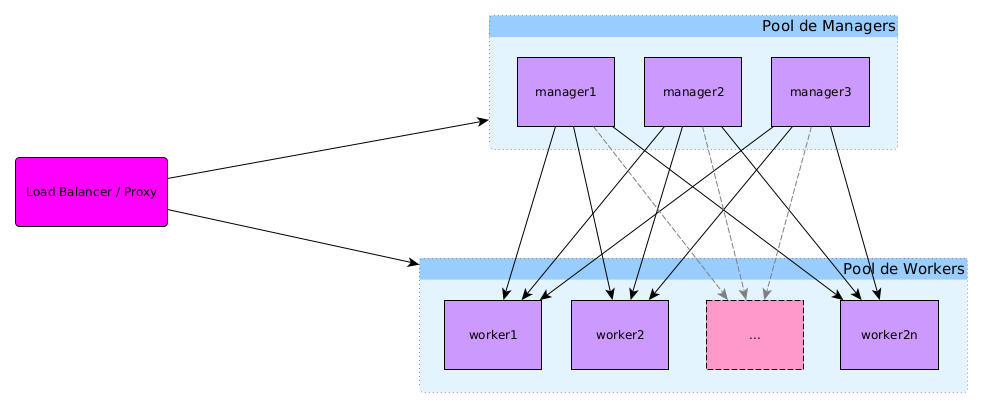
Description de l’infrastructure
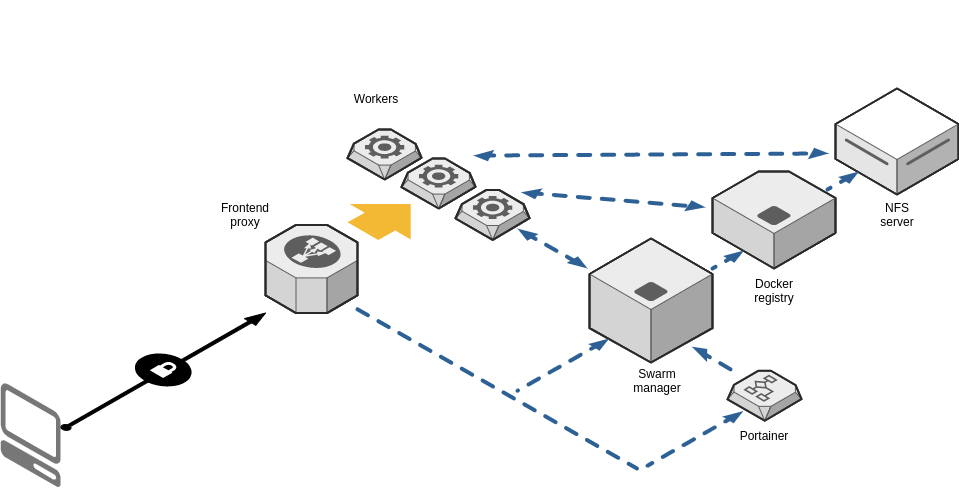
L’infrastructure générale mise en œuvre est composée des éléments suivants :
- Proxy frontend : gère la connexion sécurisée aux applications depuis l’extérieur pour donner accès aux applications et services hébergées sur le cluster. Il joue également le rôle de répartiteur de charge et de firewall du cluster en limitant l’accès à des machines ou réseaux clients et l'accès à certains ports (80 et 443).
- Le cluster Docker Swarm proprement dit, composé de
- 1 ou plusieurs « workers » qui exécutent les conteneurs des différents services du cluster, l'infrastructure de démonstration en possède 2, mais d’autres peuvent être ajoutés « à chaud »
- 1 « manager » qui fournit les fonctionnalités suivantes
- L'orchestrateur des stacks et services du cluster (Docker Swarm)
- Le registre et dépôt des images Docker custom utilisées par les services et conteneurs (Docker Registry)
- Le partage de fichiers entre le « manager » et les « workers » via un serveur NFS
- Une application web de gestion du cluster (Portainer)
- L'exécution de tâches de gestion sur les différentes machines du cluster avec l’outil Ansible
- La construction des images Docker avec l’outil Docker Compose
- D'autres applications web de gestion ou de monitoring selon les besoins qui apparaîtront lors de l'utilisation du cluster
D'autres applications externes au cluster peuvent lui être connectées, par exemple
- l'authentification SSO via l'IDP Shibboleth UCLouvain
- un cluster de base de données (MySQL, Percona, PostgreSQL…)
- un serveur Gitlab pour la récupération du code des applications…
- …
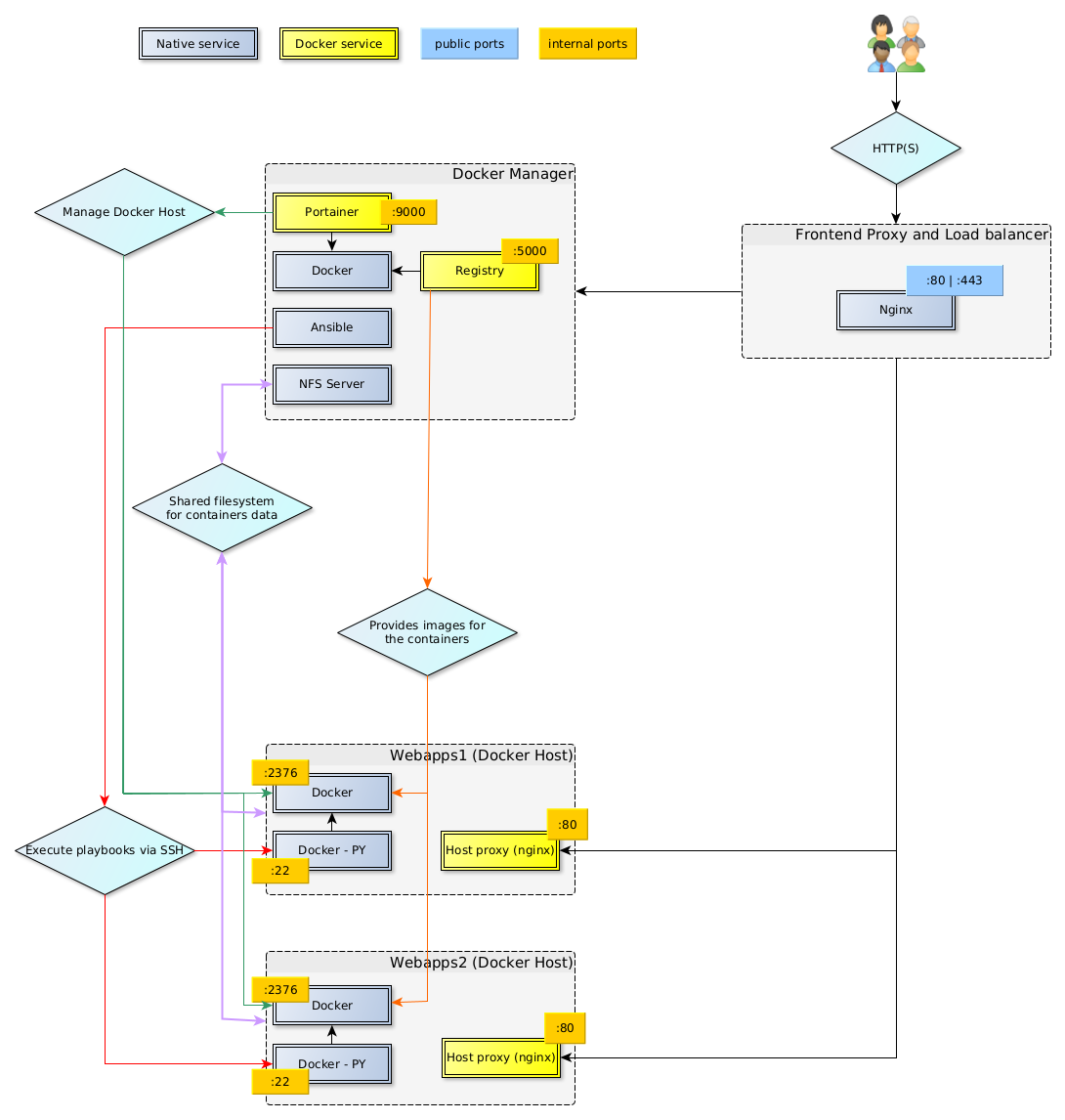
Les machines du cluster
L'infrastructure de démonstration est mise en place dans le cloud Open Nebula géré par SIPR et est composée des éléments suivants :
- 1 machine virtuelle Debian GNU/Linux1 pour le manager du cluster – qui hébergent les conteneurs des services des applications ;
- 2 machines virtuelles Debian GNU/Linux pour les workers.
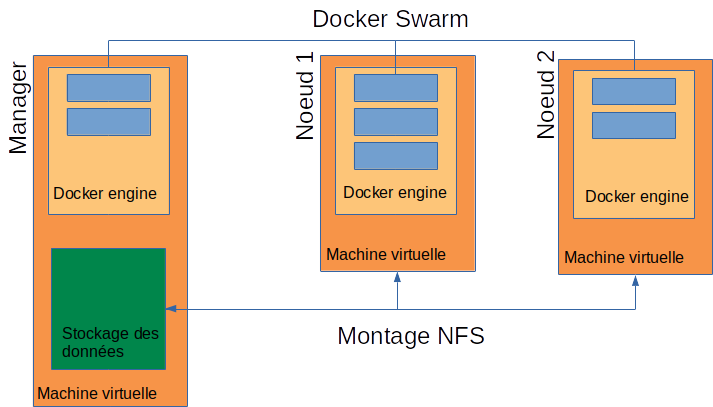
Load balancing et proxys
La répartition de charge et le reverse proxy se fait à deux niveaux dans l’infrastructure :
- Un niveau « externe » situé devant le cluster qui permet de gérer les certificats SSL, les règles spéciales de droits d’accès et les noms de domaine des applications. Il est chargé de répartir la charge entre les différentes machines du cluster. Il permet également d’accéder aux applications web de gestion et de monitoring du cluster.
- Un niveau « interne » situé dans le cluster qui permet de joindre les applications déployées sur ce dernier. Celui-ci utilise le DNS interne de Docker pour joindre les services des stacks applicatives. Il permet également de limiter les ports ouverts sur les machines du cluster et évite d’exposer tous les conteneurs à l’extérieur du cluster. Ce proxy est exposé au proxy extérieur via le port 80 et aux services du cluster via un réseau interne à Docker. Pour l’utiliser, les services devant être accédés depuis l’extérieur du cluster devront s’y connecter.
Les solutions de proxy et load balancing qui ont été envisagées dans le cadre de ce brevet sont :
- NGINX : solution de serveur web, reverse proxy et répartiteur de charge open source très légère et très performante
- Caddy : un serveur web open source très léger utilisant HTTPS par défaut
- Traefik : un reverse proxy / répartiteur de charge open source conçu pour faciliter le déploiement d’application en microservices
- HAProxy : une solution de proxy et répartiteur de charge performante
| Solution | Externe | Interne |
|---|---|---|
| NGINX | oui | oui |
| HAProxy | oui | non |
| Traefik | (oui) | oui |
| Caddy | oui | oui |
Ayant déjà une expérience de NGINX, j’ai préféré utiliser ce dernier pour l'infrastructure de démonstration, mais les deux autres solutions pourraient être envisagées pour une future infrastructure.
Remarque :
- En production, HAProxy (en cours de mise en place pour l’infrastructure SIPR) pourrait remplacer NGINX
- Docker Swarm effectue lui-même un routage interne ainsi qu’une répartition de charge entre les conteneurs (tâches) d’un service
SCHEMA PROXY FRONT END
Utilisation de l’infrastructure de démonstration
L’infrastructure de démonstration mise en place dans le cadre de ce brevet est utilisée activement depuis 2019 pour le déploiement de stacks applicatives dans le cadre du développement du nouveau portail UCLouvain en Drupal 9.
Voici par exemple les stacks déployées afin de fournir un site Drupal ainsi que l’authentification SAML (via Shibboleth) associée :
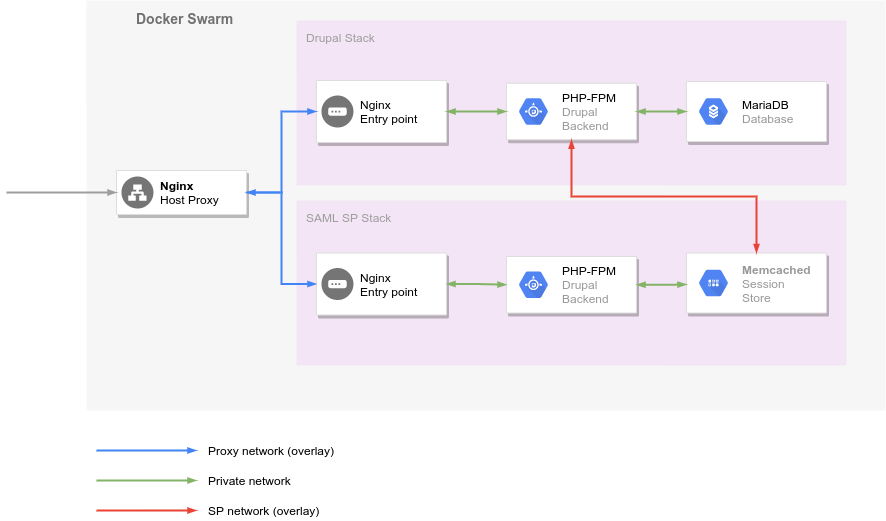
Une stack Drupal peut-être déployée pour chaque développement ou plateforme de démonstration spécifique. La stack SAML SP est commune à l’ensemble des stacks Drupal déployées.
En plus de ces stacks destinées au développement du portail, l’infrastructure héberge aussi d’autres stacks applicatives : blog, outils de développement, gestionnaire de base de données…
Cette infrastructure a également servi de modèle à une infrastructure similaire utilisée pour la mise en place d’un cluster ElasticSearch. Ce cluster est au cœur de la nouvelle application du service bibliothèques de l'UCLouvain et qui doit être mise en production début 2022 afin de succéder à VIRTUA.
Mise en place de l’infrastructure
1. Infrastructure de machines virtuelles dans Open Nebula
Mise en place de 4 machines virtuelles Debian dans OpenNebula par SIPR : 3 pour le cluster Docker Swarm, une pour le proxy frontal.
Configuration des machines :
- manager du Swarm : 4 cœurs, 16 Go RAM, 20Go pour le système, 40 Go pour /var/lib/docker 2, 20 Go pour le partage avec les nœuds /dockerdata-ceph
- workers du cluster : 4 cœurs, 16 Go RAM, 20 Go pour le système 3
- proxy Nginx : 4 cœurs, 8 Go RAM, 20 Go pour le système
2. Le stockage partagé
Pour le partage des fichiers des applications, un volume Ceph est monté sur le nœud manager à l’emplacement /dockerdata-ceph.
Ce point de montage est partagé avec les hôtes depuis le manager via le protocole NFS.
Remarques :
- Le partage du point de montage via NFS depuis le manager plutôt que depuis l’infrastructure NFS fournie par SIPR a été préférée pour des raisons de performances.
- La gestion des permissions sur les fichiers est mise en place en utilisant les groupes POSIX et le système d'ACL4 de Debian.
- Le nombre de nœuds hôtes du cluster pourra être doublé en production si la charge le nécessite ou pour assurer une redondance des services en cas de perte d’un data center.
2.1. Configuration de la gestion via les ACL
sudo apt install acl
#check if acl supported by filesystem
sudo tune2fs -l /dev/vdd1
# set group as "sticky"
sudo chmod g+s docker /dockerdata-ceph
# set group default acls
sudo setfacl -Rdm g:docker:rwx /dockerdata-ceph/
Dans cette configuration, le groupe docker est appliqué automatiquement à tous les fichiers et répertoires et reçoit les droits rwx sur ceux-ci afin que les conteneurs puissent lire et écrire sans problème sur le système de fichier partagé.
2.2. Configuration du partage NFS
Export du répertoire /dockerdata-cephvia NFS depuis le manager /etc/exports
/dockerdata-ceph 10.1.4.64(rw,no_subtree_check,no_root_squash,async) 10.1.4.65(rw,no_subtree_check,no_root_squash,async)
Le choix du flag async sur le serveur a été fait afin de fournir les performances nécessaires sur l'infrastructure. Cette option peut poser des problèmes lors de l’écriture des fichiers, mais ceux-ci sont mitigés par le fait qu’un seul hôte écrit à la fois sur le montage.
Montage sur les workers /etc/fstab
10.1.4.63:/dockerdata-ceph /dockerdata-ceph nfs defaults,noatime
syncandasynchave different meanings for the two different situations.
syncin the client context makes all writes to the file be committed to the server.asynccauses all writes to the file to not be transmitted to the server immediately, usually only when the file is closed. So another host opening the same file is not going to see the changes made by the first host.Note that NFS offers "close to open" consistency meaning other clients cannot anyway assume that data in a file open by others is consistent (or frankly, that it is consistent at all if you do not use
nfslockto add some form of synchronization between clients).
syncin the server context (the default) causes the server to only reply to say the data was written when the storage backend actually informs it the data was written.asyncin the server context gets the server to merely respond as if the file was written on the server irrespective of if it actually has written it. This is a lot faster but also very dangerous as data may have a problem being committed!In most cases,
asyncon the client side andsyncon the server side. This offers a pretty consistent behaviour with regards to how NFS is supposed to work.
3. Installation et configuration de Docker et du Docker Swarm
L'installation de Docker sous Debian se fait en suivant la documentation officielle5.
Configuration de Docker dans le fichier /etc/default/docker
# Docker Upstart and SysVinit configuration file
#
# THIS FILE DOES NOT APPLY TO SYSTEMD
#
# Please see the documentation for "systemd drop-ins":
# https://docs.docker.com/engine/admin/systemd/
#
# Customize location of Docker binary (especially for development testing).
#DOCKERD="/usr/local/bin/dockerd"
# Use DOCKER_OPTS to modify the daemon startup options.
#DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4"
# If you need Docker to use an HTTP proxy, it can also be specified here.
#export http_proxy="http://127.0.0.1:3128/"
# This is also a handy place to tweak where Docker's temporary files go.
#export DOCKER_TMPDIR="/mnt/bigdrive/docker-tmp"
DOCKER_OPTS="--config-file=/etc/docker/daemon.json"
Options du daemon Docker dans /etc/docker/daemon.json
{
"storage-driver": "overlay2",
"graph": "/var/lib/docker",
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "2"
},
"debug": false
}
Installation de docker-py sur les hôtes Docker
apt-get install python-pip
pip install docker-py
Initialisation du mode swarm sur le manager6 :
docker swarm init --advertise-addr <internal_server_ip>
Exemple :
$ docker swarm init --advertise-addr 192.168.99.100
Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c \
192.168.99.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Le nom des nœuds peuvent être obtenus via :
docker node ls
Sur les workers, la commande suivante permet de rejoindre le cluster.
$ docker swarm join \
--token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c \
192.168.99.100:2377
This node joined a swarm as a worker.
4. Portainer, Registry, Swarmpit et Docker-Compose
4.1. Installation de Portainer sur le manager
1ʳᵉ étape : instanciation du conteneur Portainer
docker volume create portainer_data
docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v /opt/portainer-data:/data portainer/portainer
2ᵉ étape : lancement de Portainer via Systemd7
Configuration /etc/systemd/system/portainer.service
[Unit]
Description=Portainer
After=dkm_registry.service
Requires=docker.service
[Service]
ExecStartPre=/usr/bin/docker stop dkm_portainer
ExecStartPre=/usr/bin/docker rm dkm_portainer
ExecStart=/usr/bin/docker run -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v /opt/portainer-data:/data --name dkm_portainer portainer/portainer
;ExecStart=/usr/bin/docker start dkm_portainer
ExecStop=/usr/bin/docker stop dkm_portainer
[Install]
WantedBy = multi-user.target
Activation du service
systemctl enable portainer.service
systemctl start portainer
systemctl status portainer
Remarque : cette configuration n’est plus optimale aujourd’hui, le lancement automatique du conteneur pouvant être géré directement par Docker.
Mise à jour de portainer
docker image pull portainer/portainer
docker kill dkm_portainer
docker rm dkm_portainer
docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v /opt/portainer-data:/data --name dkm_portainer portainer/portainer
Configuration du proxy frontal
Une fois Portainer installé, il restera à définir un site dans le proxy frontal (voir plus loin) afin d'y avoir accès depuis l'extérieur des data center :
upstream portainer_backend {
server dkm-webapps.sipr-dc.ucl.ac.be:9000;
}
server {
listen 80;
listen [::]:80;
server_name portainer.apps.sisg.ucl.ac.be;
# Redirect all HTTP requests to HTTPS with a 301 Moved Permanently response.
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
include /etc/nginx/uclinclude/ssl/apps-ssl.conf;
server_name portainer.apps.sisg.ucl.ac.be;
location / {
include /etc/nginx/uclinclude/access/apps.access.conf;
proxy_pass http://portainer_backend;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM dkm;
proxy_set_header Host $host;
}
}
4.2. Installation du registry
Sources :
- https://www.server-world.info/en/note?os=Debian_9&p=docker&f=6
- https://www.server-world.info/en/note?os=Debian_9&p=ssl
- https://docs.docker.com/registry/deploying/
1ʳᵉ étape : Création d’un certificat auto-signé pour les communications entre les nœuds du cluster et le registry.
Génération de la clé
root@dkm-webapps:/etc/ssl/private# openssl genrsa -aes128 -out dkm-webapps.key 2048
Generating RSA private key, 2048 bit long modulus
......................+++
........................................+++
e is 65537 (0x010001)
Enter pass phrase for dkm-webapps.key:
Verifying - Enter pass phrase for dkm-webapps.key:
Il faut ensuite retirer la pass phrase de la clé :
root@dkm-webapps:/etc/ssl/private# openssl rsa -in dkm-webapps.key -out dkm-webapps-nopass.key
Enter pass phrase for dkm-webapps.key:
writing RSA key
Génération du fichier de demande de certificat (CSR) :
root@dkm-webapps:/etc/ssl/private# openssl req -new -days 3650 -key dkm-webapps-nopass.key -out dkm-webapps-selfsigned.csr
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:BE
State or Province Name (full name) [Some-State]:BW
Locality Name (eg, city) []:LLN
Organization Name (eg, company) [Internet Widgits Pty Ltd]:SISG
Organizational Unit Name (eg, section) []:^C
root@dkm-webapps:/etc/ssl/private# openssl req -new -days 3650 -key dkm-webapps-nopass.key -out dkm-webapps-selfsigned.csr
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:BE
State or Province Name (full name) [Some-State]:BW
Locality Name (eg, city) []:LLN
Organization Name (eg, company) [Internet Widgits Pty Ltd]:UCLouvain
Organizational Unit Name (eg, section) []:SISG
Common Name (e.g. server FQDN or YOUR name) []:dkm-webapps.sipr-dc.ucl.ac.be
Email Address []:info-portail@uclouvain.be
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
Création du certificat auto-signé :
root@dkm-webapps:/etc/ssl/private# openssl x509 -in dkm-webapps-selfsigned.csr -out dkm-webapps-selfsigned.crt -req -signkey dkm-webapps-nopass.key -days 3650
Signature ok
subject=C = BE, ST = BW, L = LLN, O = UCLouvain, OU = SISG, CN = dkm-webapps.sipr-dc.ucl.ac.be, emailAddress = info-portail@uclouvain.be
Getting Private key
Vérification :
root@dkm-webapps:/etc/ssl/private# ls
dkm-webapps.key dkm-webapps-nopass.key dkm-webapps-selfsigned.crt dkm-webapps-selfsigned.csr
2ᵉ étape : Installation du certificat
Sur le manager :
root@dkm-webapps:/etc/ssl/private# mkdir -p /etc/docker/certs.d/dkm-webapps.sipr-dc.ucl.ac.be:5000
root@dkm-webapps:/etc/ssl/private# cp /etc/ssl/private/dkm-webapps-selfsigned.crt /etc/docker/certs.d/dkm-webapps.sipr-dc.ucl.ac.be\:5000/ca.crt
Sur chacun des workers :
root@dkh-webapps[1-2]:/root# mkdir -p /etc/docker/certs.d/dkm-webapps.sipr-dc.ucl.ac.be:5000
root@dkh-webapps[1-2]:/root# cp dkm-webapps-selfsigned.crt /etc/docker/certs.d/dkm-webapps.sipr-dc.ucl.ac.be\:5000/ca.crt
3ᵉ étape : Installation du registry
Récupération de l’image :
root@dkm-webapps:/etc/ssl/private# docker pull registry:2
2: Pulling from library/registry
Digest: sha256:5a156ff125e5a12ac7fdec2b90b7e2ae5120fa249cf62248337b6d04abc574c8
Status: Image is up to date for registry:2
Création du répertoire pour le stockage des données du registry :
mkdir /var/lib/docker/registry
Lancement du registry :
root@dkm-webapps:/etc/ssl/private# docker run -d -p 5000:5000 -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/dkm-webapps-selfsigned.crt -e REGISTRY_HTTP_TLS_KEY=/certs/dkm-webapps-nopass.key -v /etc/ssl/private:/certs -v /var/lib/docker/registry:/var/lib/registry registry:2
4ᵉ étape : Test du registry
Sur la machine manager :
root@dkm-webapps:/etc/ssl/private# docker pull debian:latest
root@dkm-webapps:/etc/ssl/private# docker tag debian dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg
root@dkm-webapps:/etc/ssl/private# docker push dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg
The push refers to repository [dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg]
f715ed19c28b: Pushed
latest: digest: sha256:bbb3345ed2e7548dc7a53385b724374ecfb166489a1066cc31b345d0d767df78 size: 529
root@dkm-webapps:/etc/ssl/private# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
drupal latest e4207c5bbdec 11 days ago 446MB
mariadb latest 67238b4c1da0 5 weeks ago 365MB
nginx latest dbfc48660aeb 6 weeks ago 109MB
dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg latest be2868bebaba 6 weeks ago 101MB
debian latest be2868bebaba 6 weeks ago 101MB
portainer/portainer latest 00ead811e8ae 2 months ago 58.7MB
registry 2 2e2f252f3c88 2 months ago 33.3MB
registry latest 2e2f252f3c88 2 months ago 33.3MB
root@dkm-webapps:/etc/ssl/private# curl -k https://localhost:5000/v2/_catalog
{"repositories":["debian_reg"]}
Sur les workers :
root@dkh-webapps1:~# docker pull dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg
Using default tag: latest
latest: Pulling from debian_reg
Digest: sha256:bbb3345ed2e7548dc7a53385b724374ecfb166489a1066cc31b345d0d767df78
Status: Downloaded newer image for dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg:latest
root@dkh-webapps1:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mariadb <none> 67238b4c1da0 5 weeks ago 365MB
nginx <none> dbfc48660aeb 6 weeks ago 109MB
dkm-webapps.sipr-dc.ucl.ac.be:5000/debian_reg latest be2868bebaba 6 weeks ago 101MB
debian <none> be2868bebaba 6 weeks ago 101MB
registry <none> 2e2f252f3c88 2 months ago 33.3MB
5ᵉ étape : Lancement du registry comme service Systemd
[Unit]
Description=Docker Registry
After=docker.service
Requires=docker.service
[Service]
Type=simple
ExecStart=/usr/bin/docker run -p 5000:5000 -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/dkm-webapps-selfsigned.crt -e REGISTRY_HTTP_TLS_KEY=/certs/dkm-webapps-nopass.key -v /etc/ssl/private:/certs -v /var/lib/docker/registry:/var/lib/registry --name dkm_registry --rm registry:2
[Install]
WantedBy = multi-user.target
Remarque : cette configuration n'est plus optimale aujourd’hui, le lancement automatique du conteneur pouvant être géré directement par Docker.
4.3. Installation du registry
Swarpit est un outil de gestion de cluster Docker Swarm fournissant un monitoring des performance du cluster. Son installation est plutôt simple et rapide grâce à un installateur :
docker run -it --rm \
--name swarmpit-installer \
--volume /var/run/docker.sock:/var/run/docker.sock \
swarmpit/install:1.9
L'installeur pose alors quelques questions permettant la personnalisation de l'outil (nom de la stack Docker Swarm, port sur lequel exposer le service, volume de stockage...). L’installation déploie également un agent sur chacun des noeuds du cluster.
Cet installeur ne permet pas de configurer le redémarrage automatique de la stack en cas de crash. Il faudra donc modifier cela via les outils en ligne de commande ou l'interface web de Portainer.
Il est également possible d'installer Swarpit manuellement en clonant son dépôt git et en adaptant le fichier yaml de description de la stack.
Une fois Swarmpit installé, il est nécessaire de configurer un site dans le proxy :
upstream swarmpit_backend {
server dkm-webapps.sipr-dc.ucl.ac.be:8088;
}
server {
listen 80;
listen [::]:80;
server_name swarmpit.apps.sisg.ucl.ac.be;
# Redirect all HTTP requests to HTTPS with a 301 Moved Permanently response.
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
include /etc/nginx/uclinclude/ssl/apps-ssl.conf;
server_name swarmpit.apps.sisg.ucl.ac.be;
location / {
include /etc/nginx/uclinclude/access/apps.access.conf;
proxy_pass http://swarmpit_backend;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM dkm;
proxy_set_header Host $host;
}
}
4.4. Installation de docker-compose
Deux options :
- installation via Python-Pip
- installation manuelle :
sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
5. Proxy NGINX, SSL et templates
L’infrastructure possède deux niveaux de proxy. Tout d’abord, un proxy frontend est mis en place afin de gérer les connexions SSL, de diriger certaines requêtes vers une application ou ports spécifiques (par exemple applications de gestion sur le manager), de limiter l’accès à certaines applications à des plages d’IP spécifiques, de répartir la charge des applications déployées sur le Swarm entre les workers…
5.1. Proxy frontal
Le proxy frontal (frontend) est un serveur nginx qui a été mis en place en dehors du cluster afin de servir de répartiteur de charge et de point d’entrée des applications hébergées sur l'infrastructure.
Il remplit les rôles suivants :
- Répartition de charge entre les 2 workers du cluster
- Proxy vers les applications hébergées sur le manager du cluster
- Point d’entrée pour les connexions HTTPS pour les domaines *.apps.sisg.ucl.ac.be et *.portail.sisg.ucl.ac.be
- Limitation d’accès aux applications de gestion du cluster
- Isolation des machines du cluster afin d’éviter d’exposer les ports des applications directement au monde extérieur
- Gestion des noms de domaine spécifiques pour certaines applications
Ce service est hébergé sur une machine virtuelle Debian dédiée dans OpenNebula.
La répartition de charge et le failover de Nginx se base sur des pools de machines appelés upstream. Voici la définition de l'upstream permettant l’accès aux applications via les proxies nginx des 2 workers :
# Upstream vers les 2 proxies des workers
upstream dkh_backend {
server dkh-webapps1.sipr-dc.ucl.ac.be:8080;
server dkh-webapps2.sipr-dc.ucl.ac.be:8080;
}
Voici un upstream permettant d’accéder à l’application Portainer sur le port 9000 du manager du cluster :
#
upstream portainer_backend {
server dkm-webapps.sipr-dc.ucl.ac.be:9000;
}
Certaines configurations ont été placées dans des fichiers inclus dans les définitions des sites :
/etc/nginx/uclinclude/ssl/apps-ssl.conf: définit la configuration de la connection sécurisée SSL/TLS commune à tous les sites/etc/nginx/uclinclude/access/apps.access.conf: définit les droits d'accès pour les applications de management (principalement du filtrage sur l'IP)
Exemples de configuration : domaine *.apps.sisg.ucl.ac.be
# generated 2020-12-14, Mozilla Guideline v5.6, nginx 1.10.3, OpenSSL 1.1.0l, intermediate configuration
# https://ssl-config.mozilla.org/#server=nginx&version=1.10.3&config=intermediate&openssl=1.1.0l&guideline=5.6
# Default server configuration
#
upstream dkh_backend {
server dkh-webapps1.sipr-dc.ucl.ac.be:8080;
server dkh-webapps2.sipr-dc.ucl.ac.be:8080;
}
server {
listen 80;
listen [::]:80;
server_name *.apps.sisg.ucl.ac.be apps.sisg.ucl.ac.be;
client_max_body_size 128M;
# Redirect all HTTP requests to HTTPS with a 301 Moved Permanently response.
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
include /etc/nginx/uclinclude/ssl/apps-ssl.conf;
server_name *.apps.sisg.ucl.ac.be apps.sisg.ucl.ac.be;
client_max_body_size 128M;
location / {
include /etc/nginx/uclinclude/access/apps.access.conf;
include /etc/nginx/uclinclude/html/error_pages.conf;
proxy_pass http://dkh_backend;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM dkh;
proxy_set_header Host $host;
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
}
}
Exemple de configuration : accès à Portainer
upstream portainer_backend {
server dkm-webapps.sipr-dc.ucl.ac.be:9000;
}
server {
listen 80;
listen [::]:80;
server_name portainer.apps.sisg.ucl.ac.be;
# Redirect all HTTP requests to HTTPS with a 301 Moved Permanently response.
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
include /etc/nginx/uclinclude/ssl/apps-ssl.conf;
server_name portainer.apps.sisg.ucl.ac.be;
location / {
include /etc/nginx/uclinclude/access/apps.access.conf;
proxy_pass http://portainer_backend;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM dkm;
proxy_set_header Host $host;
}
}
Notes :
- Pour ce proxy, il a fallu obtenir des certificats SSL avec wildcard. La méthode à utiliser pour créer le fichier CSR (Certificate Signing Request) se trouve dans les documents annexes.
- Les configurations SSL peuvent être générées facilement en se rendant sur le site https://ssl-config.mozilla.org/
- Les modèles et fichiers de configurationpour le proxy frontal se trouvent dans les documents techniques.
5.2. Proxy sur les workers
En plus du proxy frontal discuté plus haut, sur chaque nœud worker, un conteneur NGINX est déployé afin de diriger les requêtes vers le bon service et la bonne stack du Swarm.
Les services devant être accessibles depuis l’extérieur sont connectés sur un réseau docker de type overlay spécifique : UCLouvainProxy.
Cela ajoute une couche d’isolation en n’exposant vers l’extérieur que les ports nécessaires pour l'accès aux applications et pas ceux de l’ensemble des services d’une stack.
Le proxy des workers est un conteneur déployé via les commandes de gestion de Docker Swarm. Il est défini dans le fichier docker-compose-stack.yml :
version: "3.5"
services:
proxy:
image: dkm-webapps.sipr-dc.ucl.ac.be:5000/dkhproxy:latest
deploy:
replicas: 2
placement:
constraints:
- node.role!=manager
build:
context: .
cache_from:
- dkm-webapps.sipr-dc.ucl.ac.be:5000/dkhproxy:latest
env_file:
- dkh_proxy.env
ports:
- target: 80
published: 8080
protocol: tcp
mode: host
- target: 443
published: 8443
protocol: tcp
mode: host
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- type: bind
source: ./entrypoint.sh
target: /usr/local/bin/start_container.sh
- type: bind
source: ./uclouvain.d/
target: /etc/nginx/sites-enabled/
- type: bind
source: ./tpl
target: /templates
networks:
- UCLouvainProxy
networks:
UCLouvainProxy:
external: true
name: UCLouvainProxy
Afin de pouvoir automatiser le déploiement des applications, les configurations des sites accessibles via le proxy sont générés grâce à un système de templates simple basé sur la commande sed.
Template de configuration de site :
# tpl/site.tpl
upstream ${site_name} {
server ${service_name};
}
server {
listen 80;
server_name ${site_name}.${host_name};
client_max_body_size 128M;
location / {
proxy_pass http://${site_name};
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM ${stack_name};
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
proxy_set_header Host $host;
}
}
Script de génération des configurations avec sed :
#generate sites config
serverconf() {
NETWORK_NAME=UCLouvainProxy
PROXY_NETWORK_ID=$(docker network inspect -f {{.Id}} $NETWORK_NAME )
SERVICES=$(docker service ls --format {{.Name}})
EXCLUDE_SERVICE=frontend_proxy
HOST_NAME="apps.sisg.ucl.ac.be"
for SERVICE in $SERVICES
do
if [ $SERVICE != $EXCLUDE_SERVICE ]
then
NETWORK_INSPECT=$(docker service inspect $SERVICE)
if [ -n "$NETWORK_INSPECT" ]
then
NETWORKS_IDS=$( echo $NETWORK_INSPECT | jq -r '.[] | {Spec} | .[] | {TaskTemplate} | .[] | {Networks} | .[] | .[] | {Target} | .[]')
for NETWORK_ID in $NETWORKS_IDS
do
if [ $NETWORK_ID = $PROXY_NETWORK_ID ]
then
STACK_NAME=${SERVICE%"_webserver"}
sed -e "s/\${service_name}/$SERVICE/; s/\${site_name}/$STACK_NAME/; s/\${host_name}/$HOST_NAME/" ./tpl/site.tpl > ./apps.d/$SERVICE.conf
fi
done
fi
fi
done
reload
}
Les configurations de site sont générées dans le répertoire uclouvain.d monté comme volume dans le conteneur du proxy.
Ces configurations sont chargées automatiquement par Nginx lors de son démarrage ou via la commande reload fournie par le script d’automatisation :
reload () {
echo "-- Reload Nginx Server"
stack-exec frontend_proxy service nginx reload
}
La commande stack-exec permet d’exécuter une tâche sur un conteneur sans savoir sur quelle machine du cluster il se trouve. Elle est décrite dans la partie « Évolution de l’infrastructure de démonstration »
Notes :
- Les fichiers de configuration du proxy des workers sont disponibles dans les documents techniques
6. Installation des outils d’automatisation (Ansible et Jenkins)
- installer Ansible sur le manager
- créer l'utilisateur Ansible (ajouter note sur l’échange de clé ssh pas encore fait)
- installer Jenkins + plugin Ansible puis dire qu’on ne l’utilise pas encore
Outils de monitoring
- Swarmpit : outil de management et de monitoring pour Docker Swarm
- Agrégation des logs des conteneurs avec Graylog
- Monitoring avec cadvisor, prometheus et grafana
Évolution de l’infrastructure au cours du temps
L’infrastructure a beaucoup changé depuis le développement initial du projet.
Ce qui est resté constant
- Cluster Docker Swarm de 3 hôtes
- Portainer pour la gestion via une interface web
- Un Registry docker
Ce qui a changé
L'architecture décrite ici a été testée et modifiée pour l’infrastructure de développement du futur portail en Drupal 8.
Au départ, elle se basait sur le build d’images Docker qui intégraient tous les fichiers sources des applications dans l’image et le chargement des dépendances (ici dépendances PHP via le gestionnaire de paquets Composer) devaient être intégrées soit durant le build, soit au démarrage de l’image. Le registry était utilisé pour sauvegarder les modifications successives faites dans les conteneurs et les images. Ces images étaient alors déployées via l’interface web de Portainer.
Dans un second temps, de l’automatisation a été ajoutée via l’utilisation de Ansible et de docker-py pour déployer les conteneurs. Dans cette configuration, toute modification des fichiers sources nécessitait un build des images et un redéploiement sur l’infrastructure. Cette procédure était complexe, lente, lourde et non-standard et pas tenable sur le long terme !
La solution que j’ai proposée a été de passer à l’usage de docker-compose et de monter le répertoire des applications via un volume à l’intérieur du conteneur. Cela se justifiait par le fait que c’est le standard de facto pour le déploiement des applications disponibles en ligne (sur Github et autres plateformes concurrentes).
Pour permettre le déploiement sur la stack Docker Swarm, deux fichiers de configuration docker-compose sont fournis pour chaque stack de services à déployer :
- le premier,
docker-compose.yml, pour l’exécution en local, la préparation des images et leur publication sur le registry via les sous-commandes dedocker-compose - le second,
docker-compose-stack.yml, contient en plus les paramètres nécessaires (contraintes de déploiement, réseaux overlay, utilisation du registry privé…) au déploiement dans Docker Swarm via les sous-commandes dedocker stack
Cela permet de conserver la possibilité d’un déploiement local sans nécessiter, de cluster Docker Swarm, pour le test et le développement…
Une série de scripts bash sont utilisées afin de faciliter encore le déploiement et, surtout, l’exécution de commandes sur un service de la stack déployée via ssh. En effet, il n’est pas possible de savoir sur quel worker du cluster se trouve un service a priori.
Le cœur de la commande est le code ci-dessous :
stack-exec()
{
if [ -z $SERVICENAME ]; then
echo "Missing service name. Abort"
usage
exit 1
fi
SERVICE="${STACKNAME}_${SERVICENAME}"
set -e
echo "-- Execute task on service $SERVICE"
SERVICE_IDS=$(docker service ps $SERVICE --format "{{.Name}}.{{.ID}}" -q --no-trunc -f "DESIRED-STATE=running")
for SERVICE_ID in $SERVICE_IDS
do
NODE_ID=$(docker inspect -f "{{.NodeID}}" ${SERVICE_ID})
NODE_IP=$(docker inspect -f {{.Status.Addr}} ${NODE_ID})
echo "-- Execute task ${@} on container $SERVICE_ID deployed on $NODE_IP "
# here document
ssh -T ${NODE_IP} << EOSSH
docker exec $SERVICE_ID ${@}
EOSSH
done
}
Problèmes et solutions
En cas de redémarrage de l’infrastructure
Si le système de fichiers NFS n’est pas monté, le cluster n’est pas capable de relancer les services.
Après un crash de l’infrastructure :
Il faut relancer le service NFS sur la manager
sudo systemctl restart nfs-kernel-server nfs-server
Ensuite sur chaque worker, il faut remonter le système de fichiers partagé :
sudo mount /dockerdata-ceph
Puis relancer Docker :
sudo systemctl restart docker
De plus, Portainer perd les informations des workers sur son dashboard, il faut donc mettre à jour les Endpoint via l’interface web.
Il faudra automatiser cette procédure.
Configuration des conteneurs
-
timezone
- via DockerFile :
ENV TZ="Europe/Brussels"
- via DockerFile :
-
via docker-compose :
environment: - TZ="Europe/Brussels" -
logs de nginx et php-fpm
-
config buffer nginx :
proxy_buffer_size 128k; proxy_buffers 4 256k; proxy_busy_buffers_size 256k;
Dépendance entre conteneurs
via docker-compose :
services:
web:
# ...
depends_on:
- "php-fpm"
- "database"
utilisation d’un script pour attendre la disponibilité d’un service :
services:
web:
# ...
command: ["./wait-for-it.sh", "php-fpm:9000", "--", "nginx", "-g", "daemon off;"]
Configurations diverses
Par défaut, certaines configurations de nginx ne sont pas suffisantes. C’est par exemple le cas de la taille maximum des requêtes acceptées par nginx via la directive client_body_max_sizeet dont la valeur par défaut est de 2Mo. Cela signifie que quelles que soient les limites de taille d'upload de fichiers fixés par les applications, les proxies nginx (frontend ou dans les stacks) ainsi que les services nginx des stacks elles-mêmes, empêcheront tout upload d’un fichier de taille supérieure à 2Mo.
Il est très simple de résoudre le problème en ajoutant la directive client_body_max_size dans les configurations des sites. Pour l'infrastructure, elle a été fixée à 128Mo pour les sites Drupal ou hébergeant un autre CMS, mais elle pourra être modifiée si nécessaire en production.
Ce qu’il reste à faire
Automatiser l’instanciation du cluster et l’ajout de nœud workers supplémentaires avec Ansible. Cette question sera traitée dans la section « Automatisation de l’instanciation du cluster avec Ansible ».
Automatiser le déploiement d’application :
- Utiliser la composition de fichiers docker-compose pour alléger la configuration des stacks
- Automatiser le déploiement des stacks avec ansible afin de pouvoir l’exécuter depuis une application distante (par exemple Jenkins, Gitlab, ou via des webhooks…)
Ces questions seront traitées dans le chapitre « Livraison continue et déploiement automatique d’applications sur le cluster ».
Gérer la perte du manager.
La perte du manager provoque actuellement un downtime de l’ensemble de l’infrastructure car
- On perd la machine qui assure la gestion du cluster.
- On perd le partage du système de fichiers NFS entre les nœuds du cluster. Si le manager tombe, les workers perdront donc l’accès à leurs données.
Cette question sera abordée plus en détail dans le chapitre des perspectives consacré à la mise en place d'une infrastructure de production.
Monter les volumes NFS directement dans les conteneneurs
Mettre en place des healthchecks spécifiques pour certains conteneurs (Drupal...).
Automatiser l'activation des applications dans les proxies avec Ansible et docker service plutôt que sed et la commande stack-exec, ce qui permettrait de mettre à jour les services nginx des proxies depuis le manager et sans avoir à se connecter sur les conteneurs.
Résolution de problèmes sur l’infrastructure
En cas de problème sur l’infrastructure.
Tous les conteneurs sont instanciés sur un seul des 2 workers
Vérifier le montage NFS sur le worker qui n’a reçu aucun conteneur, si absent sudo mount -a
Un seul replica du proxy des workers a été instancié
Idem que pour le problème précédent
Aucun conteneur ne se lance à part les conteneurs système (registry, portainer...)
C’est probablement un problème avec le serveur NFS sur le manager
- relancer le serveur NFS sur dkm-webapps
systemctl restart nfs-server - remonter système de fichiers sur dkh-webapps1-2
sudo mount -a
Le service du proxy des workers ne démarre pas
Cela est généralement dû à des configurations de site qui pointent vers des services absents et empêchent nginx de démarrer
- supprimer toutes les configurations dans
/dockerdata-ceph/proxy/uclouvain.dsaufapps.sisg.conf - relancer la stack frontend :
- soit faire un update du service via Portainer
- soit faire un update du service via le client ligne de commande Docker
docker service update --force frontend_proxy - soit ré-instancier la stack
(cd /dockerdata-ceph/proxy; docker stack rm frontend; docker stack deploy -c docker-compose.yml frontend)
- une fois le service redémarré, recharger la config des sites via
(cd /dockerdata-ceph/proxy/; sudo -u ansible bin/app serverconf)
Erreur 502 persistante
Généralement due à un problème avec un des niveaux de proxy
- recharger la config
nginxsur le proxy frontal viasystemctl reload nginx - si ça ne suffit pas, recharger la config des sites configurés sur le proxy des workers via
(cd /dockerdata-ceph/proxy/; sudo -u ansible bin/app serverconf)
Désactiver et réactiver un service
# désactiver un service
docker service scale <service_name>=0
# activer le service
docker service scale <service_name>=<number_of_replicas>
# si un seul replica
docker service scale <service_name>=1
Le choix s’était au départ porté sur une distribution Ubuntu 18.04 LTS présentée comme préférable à Debian pour le déploiement de Docker. Néanmoins, une incompatibilité entre la gestion du DNS dans Ubuntu 18.04 et la version du Docker Engine disponible au moment de la mise en place nous à fait choisir Debian GNU/Linux à la place.
Il faudra prévoir un stockage pour /var/lib/docker plus important en production.
Il faudra prévoir un stockage supplémentaire pour /var/lib/docker en production.
« Installation de docker sous debian et ubuntu » https://docs.docker.com/install/linux/docker-ce/debian/
ACL (Access Control List) est un système de gestion fin des droits d’accès aux fichiers. Les droits d’accès y sont définis par des ACE (Access Control Entry) pour un utilisateur ou un groupe. Ce système vient compléter la gestion des permissions POSIX sur les systèmes de type UNIX.
Voir la documentation officielle pour plus de détails https://docs.docker.com/engine/swarm/
Voir https://container-solutions.com/running-docker-containers-with-systemd/
Annexe 3: Automatisation du déploiement du cluster avec Vagrant et Ansible
- Présentation des outils utilisés
- Déploiement d’un cluster Docker Swarm avec Ansible sur le banc de test
- Structure du banc de test vagrant
- Fichier de configuration pour mettre en place un cluster Docker Swarm
- Automatisation de l’initialisation du cluster avec Ansible
- Lancement de l’infrastructure
- Finalisation de l’infrastructure
- Configuration client server NFS
- Proxy sur les workers
- Pour une utilisation hors de Vagrant
Note : A l'origine, mon brevet devait intégrer une automatisation du déploiement des cluster Docker Swarm. Toutefois, ce mécanisme s'est montré inutile tant le déploiement du cluster Docker Swarm est une tâche rapide à effectuer. Ce mécanisme ne trouverait de plus sont utilité que dans le cadre d'une infrastructure permettant le déploiement de cluster Docker et non le déploiement d'application sur un cluster Docker. De plus, les outils de gestion d'hyperviseur intègre de plus en plus souvent des outils permettant le déploiement de cluster Docker. J'ajouterais sont usage en tant que banc de test pour le déploiement d'applications n'est plus nécessaire puisqu'il est possible de déployer en une quinzaine de minutes un cluster Docker avec un seul hôte sur n'importe quelle machine Linux. Il retrouverait cette utilité s'il était possible d'utiliser Vagrant pour déployer directement des machines virtuelles via l'infrastructure Open Nebula de SIPR. J'ajouterais également que l'installation des outils nécessaires au banc de test (Vagrant, Virtual Box ou un autre Hyperviseur) sont plus long que l'installation de Docker lui-même sur la machine. J'ai toutefois laissé les notes que j'avais prises pour cette partie de mon travail en annexe afin qu'elles ne soient pas perdues pour un futur usage.
Présentation des outils utilisés
Vagrant
Introduction et concepts
D'après la Wikipedia1 :
Vagrant est un logiciel libre et open-source pour la création et la configuration des environnements de développement virtuel. Il peut être considéré comme un wrapper autour de logiciels de virtualisation comme VirtualBox.
[...] Vagrant n'impose plus VirtualBox, mais fonctionne également avec d'autres logiciels de virtualisation tels que VMware, et prend en charge les environnements de serveurs comme Amazon EC2, à condition d'utiliser une "box" prévue pour le système de virtualisation choisi.
[...] Vagrant fournit un support natif des conteneurs Docker à l'exécution, au lieu d'un système d'exploitation entièrement virtualisé. Cela permet de réduire la charge en ressources puisque Docker utilise des conteneurs Linux légers.

Fig.: Instanciation d’un cluster de 3 machines avec Vagrant et Libvirt.
Concepts clés de Vagrant :
- Box : image de machine virtuelle pour Vagrant. Elles peuvent être créées sur mesure, mais le plus simple est d’en télécharger une depuis le hub de Vagrant2
- Vagrantfile : c’est le fichier qui décrit les machines virtuelles à instancier, un Vagrantfile permet les opérations suivantes sur les machines :
- Configuration : nombre de cpu, RAM, configuration du réseau, partage de fichiers (via NFS)…
- Provisionning : le system de provisionning de Vagrant permet d’exécuter des opérations sur les machines avec différent fournisseurs : shell, file, ansible, docker, salt, puppet…
- Déploiement : Vagrant permet le déploiement d’application vers un hébergeur (Heroku, (S)FTP…)
- Provider : fournisseur utilisé pour l’instanciation des machines virtuelles (Virtualbox, Libvirt, VMWare, Amazon EC2, LXC, Docker…)
Hyperviseur
Pour instancier ses machines virtuelles, Vagrant nécessite la présence d’un hyperviseur sur les machines cibles.
Généralement c’est Virtualbox qui est utilisé. Virtualbox est un gestionnaire de machine virtuelle bien connu et disponible pour de nombreuses plateformes.
Toutefois, le support officiel de Virtualbox (appartenant à Oracle) a été abandonné dans les dernières versions de Debian pour lui préférer des solutions totalement libres : l’API de virtualisation Libvirt3 4 et l’hyperviseur QEMU-KVM.

Fig.: libvirt est une couche d’abstraction entre orchestrateurs de machines virtuelles et hyperviseurs.
Note :
- Libvirt peut être appelée depuis de nombreux orchestrateurs (Vagrant, OpenStack…) et supporte de nombreux hyperviseurs (Xen, KVM, LXC…)
- Libvirt et KVM peuvent être utilisés pour déployer des machines virtuelles dans l’environnement OpenNebula 5
Installer Vagrant et libvirt ou VirtualBox
L’idéal est d’installer la dernière version de VirtualBox et Vagrant depuis les sites officiels,
- La version de VirtualBox fournie dans les dépôts de la distribution Ubuntu 18.04 est tout à fait suffisante
- La version de Vagrant fournie par les dépôts d’Ubuntu 18.04 est dépassée et rentrent en conflit avec les plugins officiels, il est donc nécessaire de télécharger la version officielle depuis le site de Vagrant
- Installer le plugin docker-compose pour vagrant via
vagrant plugin install vagrant-docker-compose6. Ce plugin donne accès à une commande de provisionnement pour docker-compose dans les fichiers Vagrantfile. Toutefois, il est tout à fait possible d'installer docker-compose le shell7 - Pour utiliser libvirt au lieu de virtualbox :
- Installer l'environnement libvirt, le gestionnaire de machine virtuelle virt-manager et l'hyperviseur QEMU-KVM :
sudo apt install QEMU-KVM libvirt-daemon-system virt-manager - Installer les headers de libvirt (et les outilsnécessaires pour compiler le plugin libvirt pour vagrant) :
sudo apt install build-essentials libvirt-dev - Installer le plugin libvirt pour vagrant :
vagrant plugin install vagrant-libvirt
- Installer l'environnement libvirt, le gestionnaire de machine virtuelle virt-manager et l'hyperviseur QEMU-KVM :
Utilisation de Vagrant :
# on recupere un vagrantfile definissant la box
vagrant init "ubuntu/xenial64"
# on crée la machine avec virtualbox pour libvirt, utiliser l'option --provider=libvirt
vagrant up --provider=virtualbox
# on se connecte à la machine en ssh
vagrant ssh
# on detruit la box
vagrant destroy
Exemple de configurations de machines virtuelles dans Vagrant pour vmware, virtualbox et libvirt
# Configure CPU & RAM per settings in machines.yml (Fusion)
srv.vm.provider 'vmware_fusion' do |vmw|
vmw.vmx['memsize'] = machine['ram']
vmw.vmx['numvcpus'] = machine['vcpu']
if machine['nested'] == true
vmw.vmx['vhv.enable'] = 'TRUE'
end #if machine['nested']
end # srv.vm.provider 'vmware_fusion'
# Configure CPU & RAM per settings in machines.yml (VirtualBox)
srv.vm.provider 'virtualbox' do |vb, override|
vb.memory = machine['ram']
vb.cpus = machine['vcpu']
override.vm.box = machine['box']['vb']
end # srv.vm.provider 'virtualbox'
# Configure CPU & RAM per settings in machines.yml (Libvirt)
srv.vm.provider 'libvirt' do |lv,override|
lv.memory = machine['ram']
lv.cpus = machine['vcpu']
override.vm.box = machine['box']['lv']
if machine['nested'] == true
lv.nested = true
end # if machine['nested']
end # srv.vm.provider 'libvirt'
Le fichier machine.yml contient les informations de configuration de chacune des machines, par exemple pour la machine manager :
- box:
vmw: "generic/ubuntu1604"
vb: "ubuntu/xenial64"
lv: "generic/ubuntu1604"
name: "manager"
nics:
- type: "private_network"
ip_addr: "192.168.100.100"
ram: "2048"
vcpu: "1"
Ansible
Introduction et concepts
Ansible est un système d’exécution automatique de tâches sur des parcs de machines. Il est en particulier utilisé pour la mise en place du déploiement continu ou la mise à jour d’infrastructure.
- Playbook: définitions de tâches ansible
- Inventaire: liste les machines sur lesquelles les tâches ansible seront exécutées
- Rôles: permettent de regrouper les tâches et dépendances de tâches ansible afin de les réutiliser et de les partager
Le principal avantage de Ansible est qu’il ne requiert pas d’agent spécifique sur les hôtes distants.
Ansible sera utilisé pour initialiser le cluster Docker Swarm sur les différents hôtes :
- configurer et initialiser un ou plusieurs managers
- configurer et initialiser les workers
Étapes du déploiement à automatiser
Il s'agira d'effectuer les tâches suivantes
- Configurer les services Docker sur le manager et les workers
- Initialiser le cluster sur le manager
- Initialiser le cluster sur les workers
- Lancer les conteneurs sur le manager : portainer/portainer-ce et registry:2
- Lancer le conteneur portainer/agent sur les workers
- Générer le proxy nginx sur le manager et le publier sur le registry
- Déployer le proxy nginx sur les workers depuis le registry
Dans un premier temps, le partage des fichiers entre les hôtes pourra être fait à travers le système de fichier de la machine de test (via Vagrant et Virtualbox). Mais par la suite, il devra être déployé sur le cluster lui-même via NFS.
Les outils que j’ai choisis d’utiliser sont :
- Vagrant pour instancier les machines virtuelles de mon infrastructure de test avec Virtualbox et libvirt + QEMU-KVM comme hyperviseur pour héberger les machines virtuelles
- Ansible pour l’automatisation de l’exécution de tâches sur les machines virtuelles
Jenkins
Jenkins est un outil dédier au déploiement et à l’intégration continue…
Déploiement d’un cluster Docker Swarm avec Ansible sur le banc de test
Structure du banc de test vagrant

Fig.: Schéma de l’infrastructure virtuelle de test
Fichier de configuration pour mettre en place un cluster Docker Swarm
Le cluster est composé de 3 nœuds : 1 manager et 2 workers. J’ai choisi d’utiliser la version stable de Debian pour les 3 machines virtuelles. L’hyperviseur utilisé est virtualbox, mais il peut être adapté très simplement pour libvirt.
workers=[
{
:hostname => "worker-1",
:ip => "192.168.100.11",
},
{
:hostname => "worker-2",
:ip => "192.168.100.12",
}
]
manager={
:hostname => "manager",
:ip => "192.168.100.10",
}
Vagrant.configure(2) do |config|
config.vm.box = "debian/stretch64"
# Install docker-py for ansible automation on all hosts
config.vm.provision "shell", inline: <<-SHELL
apt-get update
apt-get install -y python python-pip
pip install docker-py
SHELL
workers.each do |machine|
config.vm.define machine[:hostname] do |node|
node.vm.hostname = machine[:hostname]
node.vm.network "private_network", ip: machine[:ip], name: "ens5"
node.vm.provider "virtualbox" do |vb|
vb.memory = 1024
vb.cpus = 2
end
node.vm.provision "docker"
end
end
config.vm.define manager[:hostname] do |node|
node.vm.hostname = manager[:hostname]
node.vm.network "private_network", ip: manager[:ip], name: "ens5"
node.vm.provider "virtualbox" do |vb|
vb.memory = 1024
vb.cpus = 2
end
node.vm.provision :docker,
images: ["portainer/portainer-ce", "registry:2"]
node.vm.provision :docker_compose
# Initialize swarm cluster
node.vm.provision "ansible" do |ansible|
ansible.playbook = "playbooks/swarm.yml"
ansible.limit = "all"
ansible.extra_vars = {
swarm_iface: "ens5"
}
ansible.groups = {
"manager" => ["manager"],
"worker" => ["worker-[1:2]"],
}
end
end
end
Ce fichier initialise les hôtes avec les fonctionnalités suivantes :
- sur tous les hôtes :
- installation de docker-py pour l’automatisation via ansible
- workers :
- installation de docker
- manager
- installation de docker et ajout des images portainer/portainer-ce et registry:2
- ansible pour l’initialisation du cluster
Automatisation de l’initialisation du cluster avec Ansible
L’initialisation du cluster dans le fichier Vagrant se fait dans la configuration du manager :
node.vm.provision "ansible" do |ansible|
ansible.playbook = "playbooks/swarm.yml"
ansible.limit = "all"
ansible.extra_vars = {
swarm_iface: "eth1"
}
ansible.groups = {
"manager" => ["manager"],
"worker" => ["worker-[1:2]"],
}
end
Attention : l'interface réseau swarm_iface à utiliser pour le cluster est spécifiée dans les variables de Ansible.
Ce code appelle un fichier playbook ansible swarm.yml (source) qui va effectuer les tâches suivantes :
- la première liste de tâches crée deux groupes à partir de la liste des nœuds manager du cluster :
swarm_manager_operationalqui contient les nœuds manager déjà actifs etswarm_manager_bootstrapqui contient les nœuds manager à activer - la seconde liste effectue la même opération pour les nœuds worker et crée les groupes
swarm_worker_operationaletswarm_worker_bootstrap - si aucun nœud ne se trouve dans le groupe
swarm_manager_operational, le premier nœud du groupeswarm_manager_bootstrapest activé - sur le premier nœud manager actif
swarm_manager_operational[0]on récupère les tokens nécessaires pour que les autres noeuds rejoignent le cluster, soit comme manager (swarm_manager_token), soit comme worker (swarm_worker_token). on récupère agalement la liste des adresses IP des managers - on ajoute les nœuds manager encore inactif au cluster
- on ajoute les nœuds worker inactif au cluster
---
# determine the status of each manager node and break them
# into two groups:
# - swarm_manager_operational (swarm is running and active)
# - swarm_manager_bootstrap (host needs to be joined to the cluster)
- hosts: manager
become: true
tasks:
- name: determine swarm status
shell: >
docker info --format \{\{.Swarm.LocalNodeState\}\}
register: swarm_status
- name: create swarm_manager_operational group
add_host:
hostname: "{{ item }}"
groups: swarm_manager_operational
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
when: "'active' in hostvars[item].swarm_status.stdout_lines"
run_once: true
- name: create swarm_manager_bootstrap group
add_host:
hostname: "{{ item }}"
groups: swarm_manager_bootstrap
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
when: "'active' not in hostvars[item].swarm_status.stdout_lines"
run_once: true
# determine the status of each worker node and break them
# into two groups:
# - swarm_worker_operational (host is joined to the swarm cluster)
# - swarm_worker_bootstrap (host needs to be joined to the cluster)
- hosts: worker
become: true
tasks:
- name: determine swarm status
shell: >
docker info --format \{\{.Swarm.LocalNodeState\}\}
register: swarm_status
- name: create swarm_worker_operational group
add_host:
hostname: "{{ item }}"
groups: swarm_worker_operational
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
when: "'active' in hostvars[item].swarm_status.stdout_lines"
run_once: true
- name: create swarm_worker_bootstrap group
add_host:
hostname: "{{ item }}"
groups: swarm_worker_bootstrap
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
when: "'active' not in hostvars[item].swarm_status.stdout_lines"
run_once: true
# when the swarm_manager_operational group is empty, meaning there
# are no hosts running swarm, we need to initialize one of the hosts
# then add it to the swarm_manager_operational group
- hosts: swarm_manager_bootstrap[0]
become: true
tasks:
- name: initialize swarm cluster
shell: >
docker swarm init
--advertise-addr={{ swarm_iface | default('eth0') }}:2377
when: "'swarm_manager_operational' not in groups"
register: bootstrap_first_node
- name: add initialized host to swarm_manager_operational group
add_host:
hostname: "{{ item }}"
groups: swarm_manager_operational
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
when: bootstrap_first_node | changed
# retrieve the swarm tokens and populate a list of ips listening on
# the swarm port 2377
- hosts: swarm_manager_operational[0]
become: true
vars:
iface: "{{ swarm_iface | default('eth0') }}"
tasks:
- name: retrieve swarm manager token
shell: docker swarm join-token -q manager
register: swarm_manager_token
- name: retrieve swarm worker token
shell: docker swarm join-token -q worker
register: swarm_worker_token
- name: populate list of manager ips
add_host:
hostname: "{{ hostvars[item]['ansible_' + iface]['ipv4']['address'] }}"
groups: swarm_manager_ips
with_items: "{{ ansible_play_hosts | default(play_hosts) }}"
# join the manager hosts not yet initialized to the swarm cluster
- hosts: swarm_manager_bootstrap:!swarm_manager_operational
become: true
vars:
token: "{{ hostvars[groups['swarm_manager_operational'][0]]['swarm_manager_token']['stdout'] }}"
tasks:
- name: join manager nodes to cluster
shell: >
docker swarm join
--advertise-addr={{ swarm_iface | default('eth0') }}:2377
--token={{ token }}
{{ groups['swarm_manager_ips'][0] }}:2377
# join the worker hosts not yet initialized to the swarm cluster
- hosts: swarm_worker_bootstrap
become: true
vars:
token: "{{ hostvars[groups['swarm_manager_operational'][0]]['swarm_worker_token']['stdout'] }}"
tasks:
- name: join worker nodes to cluster
shell: >
docker swarm join
--advertise-addr={{ swarm_iface | default('eth0') }}:2377
--token={{ token }}
{{ groups['swarm_manager_ips'][0] }}:2377
On installe aussi Docker-Py afin de pouvoir automatiser certaines tâches Docker via les plugins Ansible :
# Installation de pyopenssl (on suppose que Python Pip est déjà installé)
- hosts: all
become: true
tasks:
- name: Install pyopenssl
command: pip install pyopenssl
Lancement de l’infrastructure
# instanciation des vm
vagrant up
# après instanciation des vm
vagrant ssh manager
La commande docker node ls permet de lister les hôtes du swarm et de vérifier leur statut :
vagrant@manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
p02s2kqxm09ks721k4glwlnzc * manager Ready Active Leader 19.03.2
6wdzbrh8kdh0gf9doed3unj8e worker-1 Ready Active 19.03.2
x6a0vfv2rrg9lkh0z2refk5rw worker-2 Ready Active 19.03.2
Finalisation de l’infrastructure
Les images docker Portainer et le Registry sont déployés via le fichier Vagrantfile, mais elles pourraient l’être via Ansible.
Que ce soit le cas où non, il reste encore à instancier ces 2 services.
Mise en place de Portainer
Pour Portainer, l’opération est plutôt simple :
# launch portainer on the first manager node
- hosts: swarm_manager_operational[0]
become: true
tasks:
- name: portainer_create_volume
shell: >
docker volume create portainer_data
run_once: true
- name: portainer_run_container
shell: >
docker run -d
-p 8000:8000 -p 9000:9000
--restart=unless-stopped
--name portainer
-v /var/run/docker.sock:/var/run/docker.sock
-v portainer_data:/data
portainer/portainer-ce
run_once: true
Déploiement de Swarmpit
À la main :
git clone https://github.com/swarmpit/swarmpit -b master
docker stack deploy -c swarmpit/docker-compose.yml swarmpit
Avec l'installeur :
docker run -it --rm \
--name swarmpit-installer \
--volume /var/run/docker.sock:/var/run/docker.sock \
swarmpit/install:1.9
Version Ansible :
Mise en place du Registry
L’idée était d’expérimenter le déploiement d'un Registry sur le manager du cluster tel que cela avait été réalisé sur l’infrastructure de démonstration. Toutefois, cela s’est avéré délicat à réaliser : le sécuriser avec un certificat SSL s’est révélé un peu complexe dans les hôtes déployés via Vagrant.
L’utilisation du Registry n’étant pas requise pour la suite, je préfère la laisser de côté pour le moment. De plus ce problème n'existera pas lors du déploiement d’une véritable infrastructure puisque les machines se verront attribuer un fqdn ! Pour contourner le problème, un moyen simple est de déclarer un Registry non sécurisé.
Note : Afin de ne pas multiplier les hôtes inutilement, le Registry est instancié ici sur le manager, mais il pourrait l’être sur un hôte dédié.
Utiliser un Registry sécurisé
L’automatisation de la mise en place du Registry dans l'infrastructure Vagrant est un peu plus complexe. En particulier parce que son utilisation nécessite : un certificat ssl8 et, surtout, un FQDN dédié.
Ansible fournit un plugins pour gérer les certificats SSL. Ce plugin requiert l'installation d'une bibliothèque Python sur les hôtes :
# Installation de pyopenssl (on suppose que Python Pip est déjà installé)
- hosts: all
become: true
tasks:
- name: Install pyopenssl
command: pip install pyopenssl
Il est alors possible de générer le certificat nécessaire sur le manager :
# Création du certificat
- hosts: swarm_manager_operational[0]
become: true
tasks:
- name: ca generate key
openssl_privatekey:
path: /etc/ssl/private/registry_ownca.key
passphrase: ansible
cipher: aes256
size: 2048
- name: registry generate csr
openssl_csr:
path: /etc/ssl/private/docker_registry.csr
privatekey_path: /etc/ssl/private/docker_registry.key
- name: registry generate self-signed crt
openssl_certificate:
path: /etc/ssl/private/docker_registry.crt
csr_path: /etc/ssl/private/docker_registry.csr
ownca_privatekey_path: /etc/ssl/private/registry_ownca.key
ownca_privatekey_passphrase: ansible
# We need to allow IPs for testing on the vagrant machines
subject_alt_name:
- ip:192.168.100.10
provider: ownca
Mais impossible de faire fonctionner ce certificat en dehors de l'hôte local localhost.
Quelques pistes pour contourner ce problème :
- générer le certificat (et sa clé) au préalable à la main sur une autre machine et l'injecter sur les hôtes
- attribuer un fqdn au manager
- en le définissant via le plugin DNS de Vagrant
- en altérant les fichiers /etc/hosts avec Ansible
- en altérant les fichiers /etc/hosts avec le plugin hostsupdater de Vagrant
Une fois généré, le certificat doit alors être copié dans les certificats reconnus par docker sur tous les hôtes. Cela peut se faire en utilisant la commande synchronize de ansible 9.
# Dans le code qui suit, swarm.manager est le fqdn attribué au registry
- hosts: all
tasks:
- name: Create docker certificates folder
shell: mkdir -p /etc/docker/certs.d/swarm.manager\:5000/
- hosts: swarm_manager_operational[0]
tasks:
- name: Copy certificate in docker certificates folder
copy:
src: /etc/ssl/private/docker_registry.crt
dest: /etc/docker/certs.d/swarm.manager\:5000/ca.crt
- name: Transfer certificate from manager to workers
synchronize:
src: /etc/ssl/private/docker_registry.crt
dest: /etc/docker/certs.d/swarm.manager\:5000/ca.crt
Une fois le certificat installé sur les hôtes, il reste à lancer le service du Registry :
# Lancement du registry sur le manager
- hosts: swarm_manager_operational[0]
become: true
tasks:
- name: registry_run_registry
shell: >
docker run -d -p 5000:5000
--restart=always
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/docker_registry.crt
-e REGISTRY_HTTP_TLS_KEY=/certs/docker_registry.key
-v /etc/ssl/private:/certs
-v /var/lib/docker/registry:/var/lib/registry
registry:2
run_once: true
Utiliser un Registry non sécurisé
Bien que cela ne soit pas recommandé, Docker offre la possibilité d'utiliser un Registry non sécurisé
Créer le Registry
# Lancement du registry sur le manager
- hosts: swarm_manager_operational[0]
become: true
tasks:
- name: registry_run_registry
shell: >
docker run -d -p 5000:5000
--restart=always
-v /var/lib/docker/registry:/var/lib/registry
registry:2
run_once: true
Il suffit alors de déclarer le registry dans la configuration de Docker sur chacun des hôtes du cluster (où 10.0.0.1 est l’IP du manager dans le cluster)
{
"insecure-registries" : ["10.0.0.1:5000"]
}
Cette opération pourrait être réalisée via Ansible.
Configuration client server NFS
La création et le partage du point de montage NFS entre les hôtes peut se faire facilement avec Ansible10.
EN CONSTRUCTION
Inventaire des hôtes (peut-être généré directement à partir de l’inventaire des nœuds Docker) :
[nfs_server]
10.0.0.1
[nfs_clients]
10.0.0.2
10.0.0.3
Template de configuration du server NFS exports.j2 :
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
/dockerdata 10.0.0.1/24(rw,no_subtree_check,no_root_squash,async)
Sur le manager :
---
- hosts: nfs_server
remote_user: ubuntu
sudo: yes
tasks:
- name: Create mountable dir
file: path=/share state=directory mode=777 owner=root group=root
- name: make sure the mount drive has a filesystem
filesystem: fstype=ext4 dev={{ mountable_share_drive | default('/dev/xvdb') }}
- name: set mountpoints
mount: name=/share src={{ mountable_share_drive | default('/dev/xvdb') }} fstype=auto opts=defaults,nobootwait dump=0 passno=2 state=mounted
- name: Ensure NFS utilities are installed.
apt: name={{ item }} state=installed update_cache=yes
with_items:
- nfs-common
- nfs-kernel-server
- name: copy /etc/exports
template: src=exports.j2 dest=/etc/exports owner=root group=root
- name: restart nfs server
service: name=nfs-kernel-server state=restarted
Sur les clients :
- hosts: nfs_clients
remote_user: ubuntu
sudo: yes
tasks:
- name: Ensure NFS common is installed.
apt: name=nfs-common state=installed update_cache=yes
- name: Create mountable dir
file: path=/nfs state=directory mode=777 owner=root group=root
- name: set mountpoints
mount: name=/nfs src={{hostvars[groups['nfs_server'][0]]['ansible_eth0']['ipv4']['address']}}:/share fstype=nfs opts=defaults,nobootwait dump=0 passno=2 state=mounted
Proxy sur les workers
Étapes du Déploiement
- Générer les configurations des sites (Ansible)
- Build de l’image si nécessaire (Docker Compose)
- Déploiement du service (Docker Swarm)
Mise à jour des configurations
- Générer les configurations des sites (Ansible)
- Mettre à jour les services (Docker Swarm)
Template :
# templates/nginx_site_template.j2
upstream {{ stack_name }} {
server {{ item }};
}
server {
listen 80;
server_name {{ stack_name }}.{{ host_name }};
client_max_body_size 128M;
location / {
proxy_pass http://{{ stack_name }};
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
proxy_set_header X-NGINX-UPSTREAM {{ stack_name }};
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
proxy_set_header Host $host;
}
}
Playbook pour re-générer et recharger la configuration des proxies.
---
# Reload services for the proxy
- hosts: manager
become: true
tasks:
- name: get all services connected to the proxy network
shell: >
docker network inspect -f {{.Id}} UCLouvainProxy
register: proxy_services
- name: check directory exists
stat:
path: ../sites
register: sites_dir
- name: find existing configurations
find:
paths: ../sites
patterns: "*.conf"
register: files_to_delete
- name: delete existing configurations
file:
path: "{{ item.path }}"
state: absent
with_items: "{{ files_to_delete.files }}"
- name: generate new configurations
template:
src: ../templates/nginx_site_template.j2
dest: ../sites/{{ stack_name }}.conf
with_items: proxy_services.output.lines
vars:
host_name: apps.sisg.ucl.ac.be
stack_name: {{ item | regex_replace('^(.+)_(.+)$', '\\1') }}
when: item != "frontend_proxy"
- name: reload proxy service containers
shell: >
docker service update --force frontend_proxy
Note: version complète de l'update de service, si la version simplifiée ne fonctionne pas avec la version de Docker installée :
- name: get id of proxy service
shell: >
docker stack services frontend --filter "name=frontend_proxy" --format "{{.ID}}"
register: proxy_service_id
- name: reload proxy service containers
shell: >
docker service update --force {{ proxy_service_id.output }}
Pour une utilisation hors de Vagrant
Il n'est actuellement pas possible d’utiliser Vagrant pour instancier des machines dans OpenNebula. Afin de pouvoir automatiser la mise en place du cluster sur une infrastructure en dehors de Vagrant, plusieurs étapes supplémentaires sont donc nécessaires.
En effet, nous nous sommes basés sur le mécanisme de provisionning de Vagrant pour installer de nombreuses dépendances dont docker et docker-compose de manière « implicite ».
Playbooks pour l’installation des services
Un playbook Ansible supplémentaire permettra de le faire playbooks/baseinstall.yml :
---
# Installation des packages de base nécessaires
- hosts: all
become: true
tasks:
- name: Install packages that allow apt to be used over HTTPS
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- apt-transport-https
- ca-certificates
- curl
- gnupg-agent
- software-properties-common
- python-apt
- git
Un playbook Ansible supplémentaire permettra de le faire playbooks/dockerinstall.yml :
---
# Installation de docker et docker-py sur des hôtes Debian et Ubuntu
- hosts: all
become: true
tasks:
- name: Add an apt signing key for Docker
apt_key:
url: https://download.docker.com/linux/debian/gpg
state: present
when: ansible_distribution == 'Debian'
- name: Add apt repository for stable version
apt_repository:
repo: deb [arch=amd64] https://download.docker.com/linux/debian {{ansible_lsb.release}} stable
state: present
when: ansible_distribution == 'Debian'
- name: Add an apt signing key for Docker
apt_key:
url: https://download.docker.com/linux/ubuntu/gpg
state: present
when: ansible_distribution == 'Ubuntu'
- name: Add apt repository for stable version
apt_repository:
repo: deb [arch=amd64] https://download.docker.com/linux/ubuntu {{ansible_lsb.release}} stable
state: present
when: ansible_distribution == 'Ubuntu'
- name: Install docker and its dependecies
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- docker-ce
- docker-ce-cli
- containerd.io
notify:
- docker status
On installe aussi les paquets Python requis pour Ansible playbooks/pythoninstall.yml:
---
# Installation de Python Pip et des paquets nécessaires pour l’automatisation avec Ansible
- hosts: all
become: true
tasks:
- name: Install Python and PIP and pip dependencies
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- python
- python-pip
- name: Install pyopenssl
command: pip install pyopenssl
- name: Install docker-py
command: pip install docker-py
Inventaires et groupes ansibles
Dans le cas de l'automatisation avec Vagrant, le plugin vagrant-ansible se chargeait de définir les machines sur lesquelles effectuer le provisionning. Pour une utilisation grandeur nature, il faudra les définir dans les fichiers de configuration de Ansible.
Vagrant https://fr.wikipedia.org/wiki/Vagrant
Vagrantbox.es http://www.vagrantbox.es/
Site officiel https://libvirt.org/
« Documentation Ubuntu sur libvirt » https://ubuntu.com/server/docs/virtualization-libvirt
« Vagrant OpenNebula Tutorial » https://github.com/marcindulak/vagrant-opennebula-tutorial-centos7
« Vagrant Docker-Compose plugin » https://github.com/leighmcculloch/vagrant-docker-compose
voir https://ermaker.github.io/blog/2015/11/18/install-docker-and-docker-compose-on-vagrant.html et https://docs.docker.com/compose/install/ pour la marche à suivre
Private registry in swarm https://codeblog.dotsandbrackets.com/private-registry-swarm/ et Create your own docker registry https://www.frakkingsweet.com/create-your-own-docker-registry/
StackOverflow – How to copy files between two nodes using ansible https://stackoverflow.com/questions/25505146/how-to-copy-files-between-two-nodes-using-ansible
Setup NFS Server and Client Using Ansible https://advishnuprasad.com/blog/2016/03/29/setup-nfs-server-and-client-using-ansible/
« Wikipedia – Libvirt » https://fr.wikipedia.org/wiki/Libvirt
openssl_certificate – Generate and/or check OpenSSL certificates https://docs.ansible.com/ansible/latest/modules/openssl_certificate_module.html
« Share Compose configurations between files and projects » https://docs.docker.com/compose/extends/