Docker, Docker Swarm et les infrastructures à base de conteneurs
- Conteneurs et machines virtuelles deux approches de la virtualisation
- Docker
- Docker Compose
- Docker Swarm
Conteneurs et machines virtuelles deux approches de la virtualisation
Ces 10 dernières années, la virtualisation d’infrastructure informatique, jusqu’alors dominée par les machines virtuelles, a connu un grand changement, et les technologies basées sur les conteneurs sont devenues un incontournable pour de nombreuses applications : développement, hébergement d’application web, calcul intensif, IoT, déploiement d’applications…
Si l’on peut faire remonter l’origine des mécanismes d’isolation de conteneurs à la commande chroot introduite en 1982 dans les systèmes UNIX, c’est au début des années 2000 que cette technologie va prendre sa forme actuelle avec des solutions telles que Linux-VServer (2000), Free BSD Jail (2000), OpenVZ (2005) ou Solaris Containers (2004)1.
Introduite en 2013, Docker n’est pas la seule solution de conteneur existant sur le marché, mais elle reste l'une des plus populaires. Parmi ses concurrents, on peut citer LXC (pour Linux Container) et son successeur LXD (Linux Container Daemon), CoreOS rkt (ou simplement Rkt), OpenVz, Apache Mesos, Podman ou encore containerd.
Devant ce grand nombre de solutions, l'Open Container Initiative (OCI) de la Linux Foundation définit des spécifications afin de garantir l’interopérabilité entre les solutions à base de conteneurs. Elle a défini des spécifications pour le format d’image OCI image-spec le l’environnement d’exécution runtime-spec – basé sur runC développé initialement par Docker.
Conteneurs et machines virtuelles : quelles différences ?
Conteneurs et machines virtuelles sont deux solutions de virtualisation d’infrastructure informatique et permettent d’isoler le fonctionnement d’un programme, donnant l’impression qu’il s’exécute dans un environnement dédié2.
- Une machine virtuelle (VM) virtualise le hardware afin d’exécuter un système d’exploitation complet qui permettra lui-même l’exécution des programmes. Un hyperviseur3 permet alors de contrôler les différentes VM sur une machine hôte.
- Un conteneur (ou conteneur d’application) virtualise uniquement un système d’exploitation qui permettra l’exécution des programmes. Un moteur de conteneurs permet alors de contrôler les différents conteneurs sur une (ou plusieurs) machine·s hôte·s.
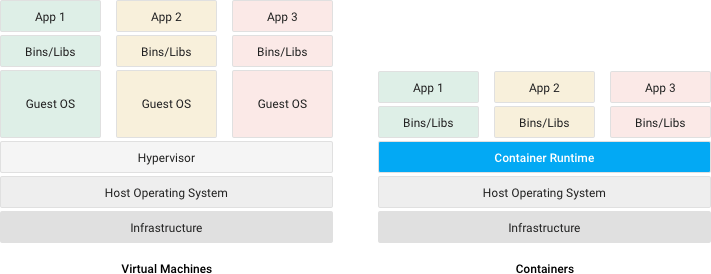
Illustration : Différences entre conteneurs et machines virtuelles – source : documentation du cloud Google
Les infrastructures « cloud » peuvent mettre en œuvre ces 2 mécanismes pour déployer les applications : des machines virtuelles déployées sur un hyperviseur vont servir d’hôtes pour un environnement d’exécution de conteneurs tel que Docker.
Dans les deux cas (machine virtuelle ou conteneur), un orchestrateur peut-être utilisé pour gérer l’infrastructure :
- Un orchestrateur de machines virtuelles (Vagrant, Open Nebula, Open Stack…) permet de gérer un ou plusieurs hyperviseurs (KVM, Virtualbox, VMWare...) et d'y déployer des machines virtuelles.
- Un orchestrateur de conteneurs (Docker Compose, Docker Swarm, Kubernetes, Podman, Amazon ECS, Azure Container Service…) permet de déployer et de gérer les conteneurs sur plusieurs systèmes hôtes.
Note : Certains orchestrateurs comme Vagrant, Open Nebula ou Terraform permettent de gérer tant des VM que des conteneurs.
Avantages et limites des conteneurs
Les conteneurs offrent des avantages par rapport aux machines virtuelles. En voici quelques uns :
- Abstraction : les conteneurs suppriment la dépendance envers l’infrastructure et le besoin d'interagir directement avec le système hôte.
- Automatisation et portabilité : les conteneurs facilitent l’automatisation des tâches (déploiement, mise à jour…) et augmentent ainsi la portabilité des applications.
- Sécurité et isolation : la sécurité des applications conteneurisées (isolation, réseau, pare-feu, accès aux données…) est gérée au niveau de la plateforme, en dehors des conteneurs, ce qui réduit fortement la complexité de leur mise en œuvre. De plus, chaque conteneur s’exécute dans un environnement isolé des autres réduisant ainsi l’impact d’un problème.
- Déploiement sur le cloud : la portabilité des conteneurs et la division des applications en services indépendants permet un déploiement facilité dans le cloud.
- Usage réduit des ressources système : les conteneurs constituent une solution de virtualisation plus légère et avec moins de perte de performances que les machines virtuelles.
- Cycle de vie des applications : les conteneurs facilitent et accélèrent le cycle de vie des applications du développement au déploiement en production. Ils facilitent en particulier le déploiement et la mise à jour de piles applicatives sur un cluster ou sur un grand nombre de systèmes en parallèle (par exemple pour l'IoT).
- Architecture en micro-services : légers et portables, les conteneurs simplifient la mise en place d’infrastructure en micro-services4.
Mêmes s’ils peuvent fortement faciliter leur travail, les conteneurs ne sont pas la solution miracle à tous les problèmes d’un sysadmin ou d’un développeur !
Bien qu’ils isolent les applications entre elles et réduisent ainsi les dangers pour l’infrastructure dans son ensemble, les conteneurs ne résoudront pas les problèmes de sécurité d’une application ! Si une faille permet d’exposer, par exemple, les données des utilisateurs d’un CMS, ce sera toujours le cas dans une infrastructure en conteneurs. En d’autres termes, une application mal écrite restera une application mal écrite même si elle s’exécute dans un conteneur.

Illustration : Isolation d’une application mal écrite dans un conteneur, mème humoristique inspiré de la tapisserie de Bayeux, auteur inconnu
De même, s’ils facilitent la mise en place de micro-services, les conteneurs ne transformeront pas magiquement une application monolithique en micro-services ! Cela requiert un travail au niveau du design des applications elles-mêmes.
Malgré un mythe persistant, les conteneurs ne peuvent remplacer les machines virtuelles dans tous les cas ! Ils fournissent par exemple moins d’isolation que les machines virtuelles, puisque les conteneurs s’exécutent quand même dans un même système hôte. Si l’isolation d’un système est cruciale, une machine virtuelle reste donc préférable. Là où les conteneurs se révèlent intéressants, c’est qu’ils permettent facilement de mieux isoler entre elles des applications qui s’exécutaient déjà sur un même hôte.
Une autre limitation des systèmes de virtualisation à base de conteneur est que, comme ils opèrent au niveau du système d’exploitation et pas du hardware, il n’est pas possible d’exécuter des conteneurs avec un système d’exploitation différent de celui de leur hôte. Ainsi sous Linux, seuls des conteneurs Linux peuvent être exécutés. Il est toutefois possible d’exécuter des distributions Linux différentes de celle du système hôte, par exemple des conteneurs Debian ou CentOS peuvent sans problème s’exécuter sous Ubuntu, et de même une machine Ubuntu 18.04 peut sans problème exécuter d’autres versions même plus récentes d’Ubuntu. Déployer des conteneurs Linux sous MacOSX ou Windows nécessite donc une machine virtuelle Linux.
Ajoutons à cela que la majorité des solutions de virtualisation à base de conteneurs sont disponibles sous Linux uniquement, puisqu’elles se basent pour la plupart sur les mêmes mécanismes du noyau Linux.
Docker
Pourquoi choisir Docker ?
J'ai choisi Docker pour mon infrastructure pour les raisons suivantes :
- Répandu : Même s’il ne consiste pas le seul environnement d’exécution de conteneur disponible, Docker est de loin le plus populaire et le plus utilisé.
- Standard : Poussé par de grands acteurs comme Google, RedHat ou encore Ubuntu, supporté par le cloud Amazon ou Azure, Docker reste encore un standard de facto pour les infrastructures à base de conteneurs.
- Support : La société Docker Enterprise (rachetée par Mirabilis en 2019) offre du support et des services professionnels autour du Docker Engine.
- Multi-plateforme : Docker propose un environnement d’exécution (Docker Engine) disponible sur la plupart des plateformes (Linux, MacOS X et Windows) via Docker Desktop. Toutefois, l'installation serveur du Docker Engine ne fonctionne que sous Linux pour les conteneurs Linux ou Windows pour les conteneurs Windows. Dans tous les autres cas une VM Linux est requise.
- Multi-architecture : Docker est disponible pour diverses architectures matérielles et peut être déployé tant sur des serveurs que sur de l'IoT.
- Large écosystème : Docker fournit et supporte un large écosystème d’outils qui facilitent grandement le travail des informaticiens qu’ils soient administrateurs système, développeurs, packageurs d’application… Docker est de plus intégré comme backend à de nombreux outils : orchestrateurs (Vagrant), plateformes de CI/CD (Gitlab), outils d’automatisation (Ansible)
- Disponibilité d’applications : De nombreuses applications web sont déjà prêtes à être déployées avec Docker via l’outil
docker compose. Des générateurs de configuration sont également disponibles sur le web. - Orchestrateurs : Des outils d’orchestration de parcs informatiques compatibles Docker sont déjà disponibles comme Kubernetes, Rancher, OpenShift… mais Docker lui-même intègre ses propres orchestrateurs permettant le déploiement sur un cluster via Docker Swarm ou sur une machine locale avec Docker Compose.
- Portabilité dans le cloud : Les conteneurs Docker peuvent être déployés dans le cloud (Azure, Amazon AWS) ou sur des « nano-ordinateurs » (Raspberry Pi, Olimex…) afin de mettre en place des solutions IoT (Internet of Things).
- Communauté et documentation : Docker a une large communauté et une grande quantité de documentation (sites web, livres, MOOCS, tutoriels…) est disponible. La documentation officielle est extrêmement complète et est fréquemment mise à jour.
Les technologies derrière Docker
Comme plusieurs autres technologies de conteneurs telles que LXC5, Docker se base sur des mécanismes et services de base du noyau Linux afin d’isoler les applications :
cgroups(control groups) assure la distribution des ressources du système hôte.namespaceassurent l’isolation des processus entre eux.containerdfournit des services nécessaires pour le fonctionnement des conteneurs.
Comme je l'ai déjà évoqué plus haut, Docker est donc une technologie intrinsèquement liée à Linux et ne peut s’exécuter sur les autres systèmes d’exploitation qu’à condition de passer par une machine virtuelle exécutant Linux. Il y a toutefois une exception pour Docker sous Windows qui permet de faire s’exécuter des conteneurs Windows via une implémentation native de runC 6.
Docker s’est vu adjoindre deux standards importants :
- Juin 2015, Open Container Initiative (OCI) : standardise les conteneurs entre les différents moteurs d’exécution existants en définissant des spécifications pour le runtime des conteneurs (Runtime spec) et les images (Image spec).
- Décembre 2016, Container Runtime Interface (CRI) : standardise la gestion des pods (ou stacks) de conteneurs dans le but d’utiliser une interface identique pour les différents moteurs d'exécution (permettant par exemple à Kubernetes d’utiliser Rkt ou Docker de manière identique).
Quelques concepts clés de Docker
- Container : un conteneur Docker est une unité logicielle légère et standardisée qui intègre une application et toutes ses dépendances afin de pouvoir les exécuter sur différents environnements logiciels. Un conteneur isole une application de son environnement et garanti qu’elle se comporte de manière identique sur tous les systèmes hôtes. Cela renforce la sécurité des applications.
- Docker Engine : c’est l’environnement d’exécution des conteneurs Docker. Le Docker Engine fournit aux conteneurs un environnement d’exécution aux propriétés identiques quel que soit le système hôte.
- Docker CLI : c’est l’outil en ligne de commande de Docker. Il propose de nombreuses commandes permettant d’interagir avec le moteur Docker : gérer les réseaux, construire des images, instancier des conteneurs, mettre à jour les services, gérer un cluster Docker Swarm…
- Hôte : machine virtuelle ou physique exécutant le Docker Engine.
- Image : une image Docker est un paquet de programmes exécutable, standalone et léger incluant tout ce qui est nécessaire pour faire fonctionner une application : code, environnement d'exécution, outils et bibliothèques système et configurations. Une image devient un conteneur lorsqu’elle est exécutée par le Docker Engine. Une image doit être construite (build) afin de pouvoir être utilisée.
- Layer : afin de gagner en place et en performance, les conteneurs et images Docker sont divisées en couche appelées layers. Ces couches sont stockées de manière indépendante, ce qui permet de les réutiliser entre plusieurs images. Chaque couche vient ajouter des fonctionnalités et des données à la précédente.
- Dockerfile : les étapes nécessaires à la configuration et à la construction d'une image Docker sont décrites dans un Dockerfile.
- Volume : un volume est un stockage de fichier permanent ou volatile monté dans un conteneur. Un volume peut-être partagé entre plusieurs conteneurs et peut correspondre ou non à un emplacement sur le système de fichier de la machine hôte. Les volumes Docker peuvent également être distants (par exemple en utilisant NFS).
- Réseau : Docker permet de définir des interfaces réseaux virtuelles qui permettent aux conteneurs de communiquer entre eux au sein d’un hôte ou d’une stack ou avec l’extérieur. En particulier, les réseaux de type overlay permettent aux services d’une stack exécutés sur différents nœuds d’un cluster de communiquer entre eux.
- Stack : une stack (pile) est un ensemble de services (c’est-à-dire d'applications qui s'exécutent dans des conteneurs Docker) liés qui partagent une série de dépendances et peuvent être orchestrés (déployés et gérés) ensemble. Dans un Swarm Docker, une stack peut être répartie sur plusieurs hôtes Docker et certains services peuvent être répliqués afin de fournir une répartition de charge. Les stacks permettent la mise en place d’une architecture de type micro-services dans laquelle les composants nécessaires au fonctionnement d’une application (base de données, serveur web, environnement d’exécution PHP…) sont exécutés dans des conteneurs différents.
- Service : un service est un des sous-éléments d’une stack. Un service peut-être répliqué, c’est à dire être rendus par plusieurs containers identiques que l'on nommera des tasks (ou tâches) dans le vocabulaire Docker. Cette réplication permet d’assurer le failover et un load balancing. Lorsque les services sont atomiques (chaque service intégrant une seule fonctionnalité comme un service serveur web, un service base de données et un service environnement d'exécution PHP-FPM), on parle alors de micro-services.
- Orchestrateur : outil de déploiement et de gestion de conteneurs, Docker en propose deux :
- Docker Compose : orchestrateur permettant de définir et de déployer des applications multi-services (stack) localement sur une machine. Cet outil est construit au-dessus de l'API de Docker. Même s'il peut être utilisé en production, il est plutôt destiné au développement ou à des architectures pour lesquelles Docker Swarm ne peut être utilisé (IoT par exemple).
- Docker Swarm : orchestrateur permettant le déploiement de services sur un cluster de plusieurs machines hôtes appelées nœuds. Docker Swarm est adapté pour les besoins de production.
- Fichier docker-compose.yml : bien que Docker fournisse des commandes nécessaires pour déployer directement des services, ceux-ci peuvent également être définis dans un fichier de configuration
docker-compose.ymlqui reprend la définition de ses images, réseaux, volumes, options d’environnement… nécessaires au déploiement. Il devient alors possible de lancer tous les services en une seule commande avec Docker Compose. Ces fichiersdocker-compose.ymlsont également utilisés pour déployer les services sur un cluster Docker Swarm. - Nœud : hôte d’un cluster Docker Swarm. On distingue deux types de nœuds dans un cluster :
- les managers permettent la gestion du cluster (déploiement des services, états des ressources, création de volumes…),
- les workers exécutent les conteneurs des services.
- Registry et Hub : les images Docker une fois construites peuvent être publiées dans un Registry afin d’économiser du temps lors des déploiements. Le Hub est un Registry public regroupant des images pré-construites et téléchargeables par le Docker Engine.
- RAFT : algorithme utilisé entre les noeuds managers d’un Swarm afin d'arriver à un consensus. Cet algorithme contraint le nombre de nœuds managers nécessaires à garantir l'obtention du consensus en cas de crash de l’un d’entre eux.
Fichier Dockefile
Voici un exemple de fichier Dockerfile permettant de construire une image d'environnement d'exécution PHP :
FROM phpdockerio/php72-fpm:latest
WORKDIR /application
# Fix debconf warnings upon build
ARG DEBIAN_FRONTEND=noninteractive
# Install selected extensions and other stuff
RUN apt-get update \
&& apt-get -y --no-install-recommends install php-memcached php7.2-mysql php-redis php-xdebug php7.2-bcmath php7.2-gd php7.2-intl php7.2-soap php-yaml \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
# Install git
RUN apt-get update \
&& apt-get -y install git \
&& apt-get clean; rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* /usr/share/doc/*
Fichier Docker Compose
Voici un exemple de fichier docker-compose.yml définissant les services nécessaires à l'exécution d'une stack PHP simple composée de 3 services (memcached, webserver et php-fpm) :
version: "3.1"
services:
memcached:
image: memcached:alpine
webserver:
image: nginx:alpine
working_dir: /application
volumes:
- .:/application
- ./phpdocker/nginx/nginx.conf:/etc/nginx/conf.d/default.conf
ports:
- "8084:80"
php-fpm:
build: phpdocker/php-fpm
working_dir: /application
volumes:
- .:/application
- ./phpdocker/php-fpm/php-ini-overrides.ini:/etc/php/7.3/fpm/conf.d/99-overrides.ini
Cette stack peut être déployée localement avec docker-compose ou sur un cluster avec les commandes docker stack du mode swarm de Docker.
Docker et les pratiques Agile et DevOps
Docker, en particulier via des outils comme Docker Compose, est un outil facilitant la mise en place des approches DevOps et Agile de plusieurs manières.
En voici quelques-unes :
- Docker permet d’effectuer la gestion de l’infrastructure comme de la gestion de code. En effet, les fichiers de déploiement docker-compose.yml ou les Dockerfile peuvent être gérés et versionnés dans un outil de partage de code source tel que git. De plus, les opérations sur le Registry utilise un vocabulaire proche de celui des systèmes de gestion de code source (
push,pull,commit). - A travers la gestion des volumes et des fichiers de variables d’environnement, Docker facilite également la gestion des configurations comme du code.
- Docker permet de mettre en place l'intégration continue en facilitant l'automatisation des tests et de la validation par le déploiement d’environnements d’exécution. En poussant cette logique jusqu’au bout, l’infrastructure elle-même pourrait être testée et validée de manière automatique.
- En automatisant la création des environnements d’exécution, Docker permet la mise en place de la livraison et/ou du déploiement continu des applications.
- Les architectures en micro-services permettent également de limiter les risques lors de la mise en production d’une nouvelle version de l’application et limitant les changements sur l’infrastructure à ce qui a été effectivement modifié et en permettant un retour en arrière en cas de problème (via le système de Registry).
- Docker permet le mise à jour « à chaud » des conteneurs en cours d’exécution et facilite donc la mise à jour des piles applicatives.
Note : Ajoutons à cela que des solutions de CI/CD telles que Gitlab-CI s'intègre très simplement dans un environnement Docker et que Gitlab lui-même propose un repository d'images Docker intégré.
Quelles solutions pour un cluster avec Docker ?
Une solution simple pour déployer des stacks de services avec Docker est d’utiliser Docker Compose. Toutefois, même si elle permet de gérer la réplication des services, cette solution ne fonctionne que sur une seule machine hôte et ne permet donc pas d’assurer un fail-over en cas de crash de la machine hôte ou une répartition de charge sur plusieurs hôtes. Cette solution ne peut donc s’appliquer qu’à l’hébergement d’applications non critiques.
Au niveau des solutions permettant la mise en place d’un cluster d’hôte pour héberger des services basés sur le moteur Docker, la situation a beaucoup évolué ces derniers mois.
Jusqu’en 2020, l’écosystème des solutions à base de conteneurs proposait de nombreuses solutions de gestion et d’orchestration de cluster Docker :
- Docker Swarm : orchestrateur intégré à Docker et utilisant le même format de fichier de configuration de services que docker-compose
- Mesos : orchestrateur basé sur DC/OS de la Apache Foundation et plutôt destiné au calcul scientifique ou aux applications ayant un temps d’exécution de tâches assez long
- Kubernetes : orchestrateur supportant différents types de conteneurs maintenu par la Linux Foundation et sans doute la solution la plus utilisée à ce jour.
- Rancher : solution d’orchestration commerciale bâtie au-dessus d’une implémentation légère de Kubernetes (RKT) rachetée par SUSE
- Microk8s : solution d’orchestration légère et performante compatible avec Kubernetes, Microk8s est développé et maintenu par Canonical et optimisé pour des hôtes Ubuntu
Il existe également des solutions orientées vers la gestion complète d'une infrastructure de cloud telles que
- OpenShift : solution développée par RedHat et construite au-dessus de Kubernetes et de CoreOS.
- Ksphere : solution développée par D2iQ inc., basée sur Kubernetes et plutôt orientée vers le calcul scientifique.
- Mesosphere/Marathon : solution développée par D2iQ inc., basée sur Apache Mesos (ou Kubernetes) et plutôt orientée vers le calcul scientifique.
A cela s’ajoute des solutions liées à des clouds propriétaires :
- Amazon ECS pour le cloud Amazon EC2
- Azure Container Service pour le cloud Azure
- Google Container Engine pour le cloud Google
Toutefois, l’annonce de l’abandon de Dockershim (la couche permettant l'utilisation de Docker comme environnement d'exécution) dans Kubernetes fin 20207 a créé une certaine panique et a changé ce paysage. Depuis sa version 1.24 sortie en 2022, Kubernetes utilise directement containerd sans passer par Docker8.
Cette décision a donc créé deux écosystèmes différents, avec d'un côté les solutions compatibles avec Docker et de l'autre celles qui ont pris la même direction que Kubernetes. Il faudra sans doute encore attendre quelques mois voire quelques années pour voir quelles seront les conséquences de cette situation.
Solution choisie dans le cadre de ce projet
Le cœur de ce brevet est construit autour de la mise en place d’une infrastructure basée sur Docker Swarm.
Pourquoi ce choix ? Simplement par Docker Swarm est intégré à Docker qui était, au moment du démarrage de ce projet, le moteur de conteneur le plus populaire et ayant, de ce fait, la plus grande communauté et le plus de documentation disponible en ligne. De plus, Docker Swarm utilise des fichiers de déploiement de stack identiques à ceux de Docker Compose, lui-même utilisé pour de nombreuses applications. Cela permet d’écrire des fichiers de déploiement Docker Swarm pour de nombreuses applications et avec un minimum de travail d’adaptation.
Toutefois, je discuterai d’autres solutions dans la section consacrée aux perspectives plus loin dans le présent document.
Ajoutons à cela que l’infrastructure que je mets en place est destinée à des applications métier relativement modestes développées au sein des services informatiques.
Pour une infrastructure plutôt orientée vers l’hébergement d’applications web à destination d’un plus large public, une autre infrastructure, voire l’utilisation d’une solution plus complète comme OpenShift, pourrait être envisagée. Cette situation sort toutefois du propos de ce brevet, mais elle sera évoquée dans la section consacrée aux perspectives.
Docker Compose
Docker Compose est un orchestrateur pour Docker destiné à gérer des piles applicatives sur un seul noeud hôte.
Il peut être utilisé pour :
- déployer des services sur une infrastructure à un seul nœud
- développer et tester des applications déployées via Docker sur sa machine locale
- construire et tester des images Docker
Docker Compose fournit un format de déclaration de pile applicative commun avec Docker Swarm.
Docker Swarm
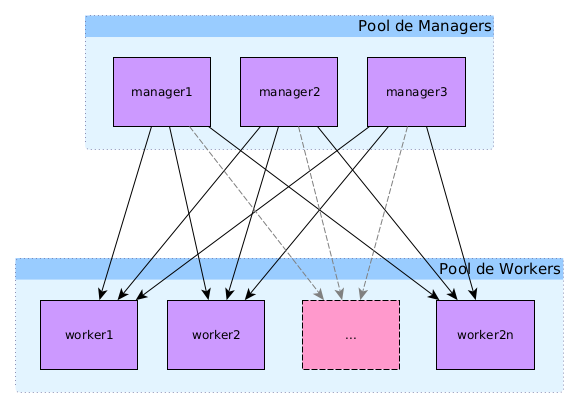
Swarm est un mode d’exécution intégré au Docker Engine pour l’orchestration d’un cluster.
Le mode swarm permet :
- la gestion d’un cluster
- la déclaration et le déploiement de services sur le cluster
- le scaling des applications sur le cluster
- la communication réseau entre les hôtes du cluster
- la répartition de charge entre les nœuds du cluster
- la mise à jour des services
Pourquoi choisir Docker Swarm ? Parce que Docker Swarm Rocks !.
Voici les raisons principales qui m'ont amené à choisir cette outil :
- Docker Swarm est intégré à Docker formant une suite complète : Docker comme moteur d'exécution de conteneurs, Docker Compose comme outil de développement et le mode Swarm pour déployer et gérer les applications en production
- Docker Swarm permet de créer un cluster d'une seule machine et de lui adjoindre des machines supplémentaires si nécessaire alors que la plupart des autres systèmes requièrent une machine d'orchestration séparée des autres nœuds du cluster
- Docker Swarm permet de mettre en place plusieurs nœuds manager
- Très simple à comprendre et à utiliser, le mode Swarm est entièrement basé sur le moteur Docker et ne requiert pas d'apprendre de nouveaux concepts
- Mettre en place un cluster prêt pour la production est très rapide environ 2h tout compris (c'est à dire y compris l'installation et la configuration des VM) pour un cluster de 5 machines; le mode swarm lui-même ne prend que 20 minutes pour sa mise en place !
Note : Le mode Swarm de Docker est basé sur le projet open source Swarmkit9.
Noeuds en mode swarm
Dans un cluster en mode swarm, il existe deux types de nœuds10 : manager et worker.
Les nœuds de type manager en charge de maintenir l'état du cluster, planifier les services et servir de point d’entrée à l’API REST de docker. Les managers se basent sur l’algorithme de consensus distribué RAFT pour gérer l’état global du cluster
Les nœuds de type worker en charge d’exécuter les conteneurs et services à la demande des nœuds manager.
Note :
- Les commandes
docker node [COMMAND] [OPTIONS]permettent de gérer les nœuds du swarm.- Il est possible de changer le rôle d’un nœud avec les commandes
docker node promoteetdocker node demote.- Il est possible d’exclure un manager des nœuds disponibles pour le déploiement de service du swarm en mettant sa disponibilité à la valeur
Drainvia la commandedocker node update.
Un cluster Docker Swarm, ou plus simplement swarm, est constitué de plusieurs noeud pouvant exercer le rôle de manager ou de worker (ou les deux). Le rôle des managers est de maintenir l'état du swarm. Celui des workers est d'exécuter les tâches des différents services ou les containers "standalone".
Le swarm le plus simple est un swarm d'une seule machine qui tiendra à la fois le rôle de manager et de worker. A ce nœud, on peut ajouter des noeuds supplémentaires nœuds qui pourront également prendre le rôle de manager et/ou de worker.
Toutefois une telle infrastructure ne permet pas d'avoir de la redondance ou de la répartition de charge entre plusieurs machines, et ne convient donc pas à une infrastructure de production. Un swarm sera donc généralement constitué de plusieurs nœuds.
Dans une telle infrastructure à plusieurs nœuds, au moins un des nœuds devra tenir le rôle de manager (le nombre de manager doit obligatoirement être impair), les autres seront les workers.
Quelques remarques importantes concernant le mode swarm
Nœuds uniquement manager
Il est déconseillé (mais pas interdit) qu'un nœud joue à la fois le rôle de manager et de worker. Pour rendre un nœud "manager only" (c'est à dire qu'il ne pourra pas exécuter les tâches des services), il suffit d'exécuter la commande docker node update --availability drain <NODE>.
Remarque : Cette option ne sera pas implémentée dans les swarms présentés ici afin de permettre le déploiement de services sur les managers également (par exemple pour les applications portainer et swarmpit).
Redondance et consensus
Afin d'assurer une redondance des managers, il est possible d'ajouter d'autres manager au swarm. Toutefois,le nombre de manager doit être impérativement impair afin de garantir le consensus sur l'état du swarm lors de la perte d'un des managers.
En particulier, les managers vont élire un Leader parmi eux via le système de consensus RAFT11 12. Celui-ci sera la référence pour l'état du swarm. S'il devient indisponible, les autres managers éliront un nouveau Leader parmi eux.
Typiquement, le nombre de manager sera de 1, 3 ou 5. Au-delà de 5, les performances du swarm risquent de diminuer à cause de la communication nécessaire entre les managers et il est déconseillé de dépasser 7 managers pour un cluster.
Redondance et distribution des managers
Docker Swarm supporte la perte de (N - 1) / 2 managers, où N est le nombre de managers. Il est donc fortement conseillé que chaque manager se trouve isolé dans un data center différent des autres managers, ceci afin d'éviter que la perte d'un data center contenant plus de (N - 1) / 2 managers ne provoque la perte du consensus sur l'état du swarm. Comme on peut le voir dns le tableau ci-dessous, afin de garantir le fonctionnement optimal du cluster et supporter la perte d'un des managers, le nombre minimum de manager est de 3.
| Nombre de managers | Nombre de managers nécessaires pour garantir le quorum | Nombre de managers pouvant être perdus | Répartition (2 zones) | Répartition (avec 3 zones) |
|---|---|---|---|---|
| 1 | 1 | 0 | 1-0 | 1-0-0 |
| 2 | 2 | 0 | ||
| 3 | 2 | 1 | 2-1 | 1-1-1 |
| 4 | 3 | 1 | ||
| 5 | 3 | 2 | 3-2 | 2-2-1 |
| 6 | 4 | 2 | ||
| 7 | 4 | 3 | 4-3 | 3-2-2 |
| 8 | 4 | 3 | 4-4 | 3-3-2 |
| 9 | 5 | 4 | 5-4 | 3-3-3 |
Note :
- Avec 2 managers, le swarm peut parfaitement fonctionner tant qu'il ne faut pas (ré-)élire un leader entre ceux-ci.
- L'infrastructure fournie par SIPR n'a que 2 data centers et ne permet donc pas de résoudre ce problème actuellement. Une piste envisagée serait d'étendre le réseau des data centers jusque Woluwé afin de placer un manager là-bas. Une autre option, mais moins pratique, pourrait être de placer un des managers hors des data centers.
- Mon infrastructure de démonstration ne comprend qu'un seul manager. Il serait très simple de remédier à cette situation en convertissant les 2 workers en managers. Je ne l'ai pas fait à ce stade afin de pouvoir effectuer des tests de déploiement basés sur le rôle des noeuds dans le swarm, mais cela pourrait être fait une production. Une autre option serait simplement d'ajouter deux nouveaux noeuds managers au swarm.
Plus d'informations ainsi que les instructions pour un "disaster recovery" ou en cas de perte du quorum (par exemple lors de la perte de plus de (N-1) / 2 managers) peuvent être trouvées dans le guide d'administration de Docker Swarm : https://docs.docker.com/engine/swarm/admin_guide/
Les infrastructures du portail
L'infrastructure de formation du portail est un exemple de swarm constitué d'un seul nœud qui joue à la fois le rôle de manager et de worker.
L'infrastructure de développement du portail est un exemple d'un swarm avec 1 un seul manager et 2 workers.
Dans le cas des infrastructures de production et de QA du portail, le Swarm est constitué de 3 managers et d'un nombre variables de D*n workers où D est le nombre de data centers dans lequel les nœuds sont déployés et n le nombre de nœuds redondants. Pour les infrastructures du portail, à l'état initial, pour QA n = 1, pour la production n = 3 répartis entre les 2 data centers (D = 2 ). Ce qui nous donne respectivement un total de 5 noeuds (3 managers et 2 workers) pour la QA et 9 pour la production (3 managers et 6 workers).
Gérer les noeuds
Voici quelques commandes de gestion d'un Swarm Docker :
- Sortir un noeud worker (sur le worker à sortir) :
docker swarm leave - Rejoindre le swarm comme worker :
- sur le manager :
docker swarm join-token worker(copier la commande obtenue) - sur le worker :
docker swarm join --token <TOKEN> 10.1.4.63:2377(coller la commandede l'étape précédente)
- sur le manager :
- Lister les noeuds du swarm (sur le manager):
docker node ls - Supprimer un noeud fantôme (sur le manager) :
docker node rm <ID>
Services en mode swarm
Le déploiement d’application en mode swarm se fait en créant des services13. Pour cela, on peut utiliser soit la commande docker service create [OPTIONS], soit des fichiers de configuration de services docker-compose.
Chaque service est l’image d’un microservice d’une application. Il peut s’agir, par exemple, d’un serveur web nginx, d’un environnement d’exécution php ou d’une base de données.
Chaque service nécessite la définition d’une image Docker et de la commande à exécuter dans cette image. On peut aussi spécifier pour chaque service les ports exposés, le réseau à utiliser pour communiquer avec d’autres services du Swarm, des ressources CPU ou mémoire allouées, le nombre de répliques (replicas dans le vocabulaire de Docker)…
Pour chaque service, le manager va planifier (schedule) une tâche par réplique du service, chaque tâche exécutant un conteneur.
Chaque nœud manager est composé
- d'un orchestrateur qui crée les tâches
- d'un allocateur d’adresse IP
- d'un dispatcheur qui assigne les tâches aux différents nœuds
- d'un planificateur (scheduler) qui lance l’exécution des tâches
Chaque nœud worker comprend le worker proprement dit qui va chercher les tâches qui lui sont assignées auprès du dispatcheur et d’un exécuteur qui exécute les tâches proprement dites.
Les services peuvent être répliqués sur 1 ou plusieurs nœuds, c’est-à-dire qu’il exécutera une tâche sur chacun de ces nœuds. Un service global sera répliqué sur tous les nœuds du swarm.
Déploiement et gestion d’un cluster en mode swarm
La mise en place d’un cluster en mode swarm est assez simple14 :
- Déployer les hôtes du cluster (des machines Linux)
- Installer Docker sur les hôtes
- Ouvrir les ports nécessaires à Docker
- Initialiser le cluster sur le nœud manager
docker swarm init [OPTIONS] - Exécuter la commande pour rejoindre le cluster sur les nœuds workers
docker swarm join [OPTIONS]
Une fois ces opérations effectuées, il est alors possible de gérer les services sur le cluster a l'aide des commandes docker service [COMMAND] [OPTIONS] ou de gérer les stacks avec les commandes docker stack [COMMAND] [OPTIONS].
Les étapes du déploiement seront décrites en détail dans la section suivante « Infrastructure de démonstration basée sur Docker Swarm »
Mise à jour des services à chaud
Les services d’une stack peuvent être facilement mis à jour à chaud, par exemple lors d’un changement dans les fichiers de configuration du service.
Prenons comme exemple la modification de la configuration de nginx dans une stack constituée de 3 services : mariadb, php-fpm et nginx.
La première étape consiste à obtenir l’id du service à mettre à jour via la commande docker stack services STACK_NAME :
~$ docker stack services fminne73
ID NAME MODE REPLICAS IMAGE PORTS
cn1jy6ixuy09 fminne73_database replicated 1/1 mariadb/server:latest
iwsqg4zp3i4m fminne73_php-fpm replicated 1/1 dkm-webapps.sipr-dc.ucl.ac.be:5000/drupal_phpfpm73:latest
tb1pfcxly9ea fminne73_webserver replicated 1/1 dkm-webapps.sipr-dc.ucl.ac.be:5000/drupal_webserver:latest
La mise à jour s’effectue alors à l’aide de la commande docker service update [OPTIONS] SERVICE_ID :
~$ docker service update --force tb1pfcxly9ea
tb1pfcxly9ea
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
L’option --force est employée pour forcer le rechargement du service.
Il est également possible de mettre à jour l'image utilisée par un service via la commande docker service update --image SERVICE_ID.
Swarm Routing Mesh et résolution de noms
Docker intègre son propre mécanisme de routing pour joindre les conteneurs quel que soit le noeud sur lequel ils sont déployés. Ce mécanisme appelé Routing Mesh15 est mis en place à travers la définition d'un réseau spécifique, le réseau Ingress.
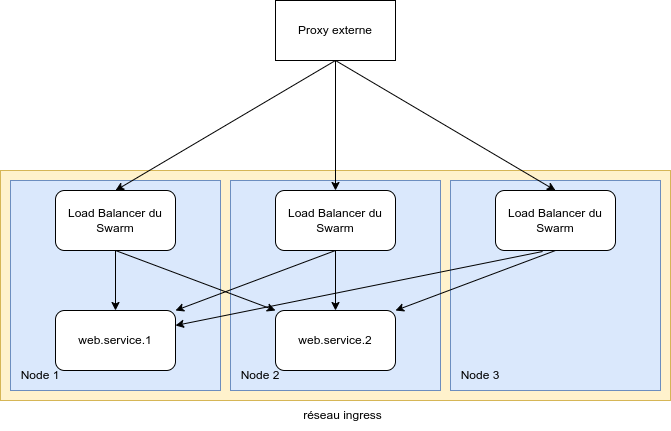
Toute requête adressée sur un port d'un noeud du Swarm sera résolue via ce mécanisme qui intègre un mécanisme de répartition de charge. Il n'est donc pas garanti que le conteneur qui va traiter la requête se trouve sur le noeud qui a reçu la requête.
En plus de ce mécanisme, Docker intègre un système de resolution de nom qui permet joindre n'importe quel service sur base du nom qui lui a été donné lors de son déploiement. Toute requête à ce service passera également par le mécanisme de répartition de charge intégré à Docker Swarm.
Wikipedia OS-level virtualization https://en.wikipedia.org/wiki/OS-level_virtualization
« Difference between Docker and Vagrant » https://www.quora.com/What-is-the-difference-between-Docker-and-Vagrant-When-should-you-use-each-one
Il existe 2 types d’hyperviseur le type 1 (Xen, KVM) s'exécute directement sur une machine physique (hardware), le type 2 (QEMU, VirtualBox, VMware) s'exécute sur un système d’exploitation hôte.
Par opposition à une infrastructure monolithique dans laquelle tous les services d’une application (serveur web, base de données, environnement d’exécution…) sont déployés sur un seul système, les architectures micro-services isolent chaque service dans un conteneur séparé et indépendant, facilitant ainsi leur maintenance (mise à jour, replacement…)
Au départ Docker se basait sur LXC avant de passer à sa propre implémentation : runC.
runc is a CLI tool for spawning and running containers according to the OCI specification https://github.com/opencontainers/runc
Kubernetes Blog « Don't Panic: Kubernetes and Docker » https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/
« Kubernetes is Moving on From Dockershim: Commitments and Next Steps » https://kubernetes.io/blog/2022/01/07/kubernetes-is-moving-on-from-dockershim/
« Swarmkit, a toolkit for orchestrating distributed systems at any scale » https://github.com/docker/swarmkit/
« How nodes work » https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/
« Pour une explication détaillée du consensus Raft » http://thesecretlivesofdata.com/raft/ et https://raft.github.io/
« Raft consensus in swarm mode » https://docs.docker.com/engine/swarm/raft/
« How services work » https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/
« Getting started with swarm mode » https://docs.docker.com/engine/swarm/swarm-tutorial/
Use swarm mode routing mesh https://docs.docker.com/engine/swarm/ingress/