Perspectives
- Mise en place d'une infrastructure de production
- Monitoring, alertes et logs
- Étude de solution pour résoudre le problème du partage de données entre les noeuds du cluster
- Vers une infrastructure de production
- Vers une infrastructure basée sur Kubernetes et Rancher
- Vers la mise en place d’un cloud d’entreprise basé sur les conteneurs dans l'infrastructure SIPR
Mise en place d'une infrastructure de production
Bien que l'infrastructure Docker Swarm mises en place dans le cadre de mon brevet soit parfaitement fonctionnelle, il est possible de l'améliorer et de lui ajouter certains mécanismes permettant de mieux la gérer en production.
Dans ce chapitre, je donne des pistes et des propositions pour de telles améliorations.
Le proxy interne du cluster
Le principal problème du reverse proxy interne que j'ai mis en place est qu'il ne permet pas une détection automatique des services déployés. Une autre de ses limitations est que si l'un des services exposés via mon proxy vient à ne plus répondre pour une raison ou pour une autre, c'est l'entièreté du proxy qui refusera de redémarrer. Cette situation peut se produire simplement si une pile applicative est arrêtée ou détruite et que le fichier de configuration du site correspondant n'a pas été supprimé du disque.
Corriger ces quelques problèmes n'est pas impossible, mais requierait la mise en place de mécanismes qui existent déjà au sein d'autres solutions de reverse proxy.
Les principales solutions de reverse proxy utilisées avec les conteneurs Docker sont les suivantes :
- Nginx : solution de serveur web, reverse proxy et répartiteur de charge open source très légère et très performante
- Caddy : un serveur web open source très léger utilisant HTTPS par défaut
- Traefik : un reverse proxy / répartiteur de charge open source conçu pour faciliter le déploiement d’application en micro services via des API
- HAProxy : une solution de proxy et répartiteur de charge performante
- Nginx Proxy Manager : proxy nginx avec une interface web de gestion des sites et configurations
- Nginx Unit : version de nginx spécialisée pour les applications web et fournissant une API REST de contrôle et de configuration
- nginx-proxy : reverse proxy basé sur nginx et intégrant une détection automatique des conteneurs exposés
| Solution | Détection auto. |
|---|---|
| Nginx | non |
| Nginx Unit | non |
| HAProxy | non |
| Nginx Proxy Manager | non |
| Traefik | oui |
| Caddy | oui (*) |
| nginx-proxy | oui |
(*) avec un module complémentaire
Les solutions les plus adaptées a Docker sont Caddy, Traefik et nginx-proxy.
Parmi ces solutions, Traefik est la plus perfectionnée et offre des fonctionnalités adaptées à la mise à disposition de microservices sous forme d'API, mais nginx-proxy est de loin la plus simple à mettre en place. C'est à elles deux que je vais m'intéresser dans la suite, et plus spécifiquement à nginx-proxy.
Solution n°1 : nginx-proxy
Dans ce projet, j'ai décidé de me baser sur nginx-proxy afin de remplacer mon reverse proxy maison. Il s'agit d'un reverse proxy basé sur Nginx et qui est capable de détecter les conteneurs automatiquement sans nécessiter ni rechargement du service ni génération de configuration en interrogeant directement le daemon Docker.
Afin d'assurer la détection automatique des services exposés, nginx-proxy repose sur la déclaration de variables d'environnement :
VIRTUAL_HOSTest le fqdn via lequel le service est appelé depuis l'extérieur du SwarmVIRTUAL_PROTOest le protocole avec lequel appeler le service à l'intérieur du Swarm (https ou http), par défaut il est identique à celui utilisé depuis l'extérieur du SwarmVIRTUAL_PORTest le port sur lequel est accessible le service dans le Swarm, par défaut il est identique à celui utilisé depuis l'extérieur du Swarm
Mais pour que nginx-proxy puisse joindre les services, il faut encore les connecter sur un réseau overlay partagé avec celui-ci. Le proxy détecte les services exposés via le socket Docker de la machine et sur base des variables d'environnement défines plus haut. Ensuite, un système de templates permet de générer les configurations de sites.
Note: Nginx proxy peut gérer le renouvellement automatique des certificats SSL soit via letsencrypt soit via ACME. Il peut aussi utiliser des certificats pré-générés fournis dans des fichiers locaux.
Voici un exemple de fichier de déploiement du proxy :
## docker-compose-proxy.yml
version: '3.7'
services:
# Déclaration du service du proxy
nginx-proxy:
image: nginx-proxy/nginx-proxy
container_name: nginx-proxy
restart: unless-stopped
ports:
- target: 80
published: 80
mode: host
protocol: tcp
- target: 443
published: 443
mode: host
protocol: tcp
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ${PWD}/certs:/etc/nginx/certs
networks:
- proxy
# Declaration du réseau overlay sur lequel les services exposés doivent être connectés
networks:
proxy:
name: proxy
attachable: true
driver: overlay
driver_opts:
encrypted: 1
Remarquons qu'on aurait également pu utiliser la commande docker secret pour ajouter les certificats et clés privées au proxy.
Exemple de fichier docker-compose qui ajoute le réseau proxy et les variables d'environnement nécessaire pour connecter un service nommé webserver au reverse proxy.
## docker-compose.proxy-override.yml
version: '3.7'
networks:
proxy:
name: proxy
external: true
services:
webserver:
environment:
- VIRTUAL_HOST=wp.dckr.sisg.ucl.ac.be
- VIRTUAL_PROTO=https
- VIRTUAL_PORT=443
networks:
- proxy
Les fichiers SSL du serveur sont fournis via dckr.sisg.ucl.ac.be.cert et dckr.sisg.ucl.ac.be.key pour l'ensemble des applications du serveur.
Voici un autre exemple complet qui déploie un service NodeRed (une plateforme de développement low code basée sur nodejs) :
version: "3.7"
services:
node-red:
image: nodered/node-red:latest
environment:
- TZ=Europe/Amsterdam
# ports:
# - "1880:1880"
networks:
- node-red-net
- proxy
volumes:
- node-red-data:/data
environment:
- VIRTUAL_HOST=nodered.docker.localhost
- VIRTUAL_PROTO=http
- VIRTUAL_PORT=1880
volumes:
node-red-data:
networks:
node-red-net:
proxy:
name: proxy
external: true
Ou encore le fichier permettant de déployer le site de mon brevet sur mon poste :
version: '3.7'
services:
mdbook-app:
image: private-registry:5000/fminne/brevet:latest
build: .
environment:
- VIRTUAL_HOST=brevet.docker.localhost
- VIRTUAL_PROTO=http
- VIRTUAL_PORT=80
networks:
- proxy
networks:
proxy:
name: proxy
external: true
Note: Du fait du mécanisme très simple pour la détection et l'exposition des services, nginx-proxy peut s'utiliser tant en mode Compose qu'en mode Swarm.
Cette solution a toutefois le défaut de sa simplicité : elle fait perdre la possibilité de générer des configurations spécifiques pour certaines applications. Néanmoins, il est possible d'ajouter des configurations spécifiques en ajoutant des fichiers qui viendront écraser la configuration par défaut d'un VHOST. Il est également possible d'ajouter des sites "à la main", puisque nginx-proxy n'est jamais qu'un proxy Nginx modifiés.
Il n'est pas non plus possible d'exposer 2 ports d'un même service sur des fqdn ou path différents. Si ce genre d'utilisation s'avère nécessaire, il faudra soit ajouter des configurations "à la main" dans nginx-proxy, soit passer à une solution utilisant d'autres techniques (par exemple les labels pouvant être associés à un service), comme Traefik.
Le concepteur de nginx-proxy fournit un outil de génération automatique de configuration pour Nginx nommé
docker-genqui est intégré dans nginx-proxy et pourrait être utilisé pour générer des configurations plus spécifiques.
Configuration du proxy pour les applications lourdes
Nginx-proxy prévoit de pouvoir surcharger les configurations par défaut du reverse proxy, soit globalement, soit pour un vhost donné.
Certaines applications plus lourdes, par exemple Drupal, demandent d'augmenter la taille des buffers de nginx. Il peut aussi être intéressant de modifier les options passées via le proxy.
# proxy.conf
# HTTP 1.1 support
proxy_http_version 1.1;
proxy_buffering off;
proxy_set_header Host $http_host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $proxy_connection;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $proxy_x_forwarded_host;
proxy_set_header X-Forwarded-Proto $proxy_x_forwarded_proto;
proxy_set_header X-Forwarded-Ssl $proxy_x_forwarded_ssl;
proxy_set_header X-Forwarded-Port $proxy_x_forwarded_port;
proxy_set_header X-Original-URI $request_uri;
# Buffers
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
proxy_connect_timeout 300;
proxy_read_timeout 300;
proxy_send_timeout 300;
Le fichier doit être monté dans le container sur le chemin /etc/nginx/proxy.conf :
version: '3.7'
services:
nginx-proxy:
image: nginxproxy/nginx-proxy:latest
container_name: nginx-proxy
restart: unless-stopped
ports:
- target: 80
published: 80
mode: host
protocol: tcp
- target: 443
published: 443
mode: host
protocol: tcp
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ./nginx-data/certs:/etc/nginx/certs
- ./nginx-data/proxy.conf:/etc/nginx/proxy.conf
networks:
- proxy_public
deploy:
mode: global
networks:
proxy_public:
name: proxy_public
# attachable: true
# driver: overlay
# driver_opts:
# encrypted: 1
external: true
Notes :
- Comme pour mon reverse proxy « maison », la récupération de l'IP réelle du client demande de modifier le fichier nginx.conf du service. La manière de procéder est totalement identique (récupérer le fichier original depuis le conteneur, par exemple avec
docker cp), ajouter les lignes manquantes et monter le nouveau fichier à l'emplacement/etc/nginx/nginx.conf. Il est également possible de le faire directement dans un fichier Dockerfile qui construit l'image de nginx-proxy.- nginx-proxy est en développement actif et des nouvelles fonctionnalités s'ajoutent régulièrement. L'état du projet peut être consulté via son dépôt Github.
Pour aller encore plus loin : Traefik
La solution nginx-proxy est tout à fait satisfaisante pour la mise en place d'une infrastructure d'hébergement d'application web de type "single page", blog ou autre CMS. Elle est par contre moins adaptée s'il s'agit de mettre en place une infrastructure donnant accès à des web services via des API REST, GraphQL, SOAP... Dans ce cas de figure, Traefik est la solution la plus adaptée.
La solution la plus adaptée a Docker Swarm est Traefik. Traefik offre une grande souplesse dans la définition des règles de proxy pour les différents services. En particulier, il permet la publication d'un même service sur plusieurs fqdn ou sur des paths différents d'un même fqdn, la publication de plusieurs ports d'un même service sur des endpoints (paths ou fqdn) différents, la gestion fine des droits d'accès... Bref tout ce qui est nécessaire pour fournir à la fois un hébergement d'application web et la publication de services via des API.
Le prix à payer est une plus grande complexité dans sa prise en main.
Contrairement à nginx-proxy qui utilisait des variables d'environnement, Traefik se base sur les labels associés à un service lors de son déploiement. Cela signifie que Traefik ne peut pas être utilisé de manière transparente en mode Compose ou en mode Swarm puisque la déclaration des labels est différente entre ces deux situations.
A titre d'exemple, voici le fichier permettant de déployer Portainer avec Traefik dans un Swarm :
version: '3.2'
services:
agent:
image: portainer/agent:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /var/lib/docker/volumes:/var/lib/docker/volumes
networks:
- agent_network
deploy:
mode: global
placement:
constraints: [node.platform.os == linux]
portainer:
image: portainer/portainer-ce:latest
command: -H tcp://tasks.agent:9001 --tlsskipverify
ports:
- "9443:9443"
- "9000:9000"
- "8000:8000"
volumes:
- portainer_data:/data
networks:
- agent_network
- proxy_net
deploy:
mode: replicated
replicas: 1
placement:
constraints: [node.role == manager]
labels:
- "traefik.enable=true"
- "traefik.docker.network=proxy_net"
- "traefik.http.routers.portainer.rule=Host(`portainer.docker.localhost`)"
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
networks:
proxy_net:
external: true
agent_network:
driver: overlay
attachable: true
volumes:
portainer_data:
Automatiser le renouvellement des certificats TLS avec ACME
Il est aujourd'hui possible de renouveler les certificats des serveurs automatiquement avec ACME. Toutefois cette solution demande des adaptations au niveau du load balancer SIPR. En effet, dans l'implémentation actuelle, le proxy HTTP et la gestion du certificat SSL se font au niveau du load balancer. Or, le renouvellement du certificat via ACME se fera au niveau des conteneurs.
Une solution est de passer à une répartition de charge TCP et laisser le proxy de l'infrastructure gérer les connexions sécurisées.
Une autre, beaucoup plus intéressante, est de déplacer le renouvellement automatique des certificats sur le load balancer de SIPR. Les connexions sécurisées entre ce dernier et les machines du Data Center pourrait se faire avec des certificats internes certifié par une CA interne aux Data Centers.
Les avantages de cette seconde solution sont multiples :
- Éviter la duplication des clés privées et certificats entre le load balancer et les machines du Data Center, et les erreurs que cela peut entraîner
- Permettre le renouvellement automatique des certificats sur le load balancer lui-même, ce qui devrait éliminer les erreurs dues aux certificats expirés
- Permettre un inventaire des différents FQDN utilisant des certificats puisque tous se trouvent sur le load balancer
- Augmenter la sécurité en facilitant la révocation des certificats ou la suppression d'une clé privée
- Déplacer la responsabilité de la gestion des clés et certificats aux équipes applicatives, qui n'ont pas toujours la maîtrise de ces outils et technologies, vers l'équipe système ou sécurité qui les maîtrise
De plus, la CA interne pourrait être utilisée pour générer des certificats pour d’autres usages, par exemple sécurisé les connexions entre les nœuds de notre cluster Docker Swarm.
Note : la tendance actuelle, poussée par les GAFAM, est de réduire la durée de vie de certificats TLS. Passée de 3 ans à 1 an il y a quelques années, il est aujourd'hui question de réduire encore celle-ci à 90 jours. La gestion manuelle du renouvellement des certificats deviendra dès lors quasiment impossible, et l'automatisation du renouvellement sera obligatoire.
Monitoring, alertes et logs
Afin de pouvoir surveiller l'infrastructure et détecter les problèmes, il reste encore à mettre en place des outils de monitoring de l'infrastructure.
Portainer et, surtout, Swarmpit intègrent des fonctionnalités de monitoring, toutefois ces 2 solutions restent limitées. Côté infrastructure, Observium permet de surveiller les machines virtuelles.
Mais il existe d'autres outils spécialisés, standards et mieux adaptés au monde des conteneurs.
Sources de métriques pour Docker
Afin de pouvoir surveiller nos conteneurs et nos machines, nous avons besoin de statistiques et de chiffres. Il existe de nombreuses possibilités pour les obtenir.
Commande stats
Docker fournit des statistiques sur les conteneurs à travers la commande docker stats. Ces statistiques sont toutefois difficilement exploitables pour du monitoring et sont plutôt destinées au debugging des conteneurs.
Commande system info et cadvisor
D'autres métriques peuvent être exposées via les Control-Groups (cgroups) et la commande docker system info --format '{{ .CgroupVersion }}-{{.CgroupDriver }}'. Les données peuvent alors être extraites des fichiers (cpu|io|memory).statde chaque conteneur.
Cela n'est toutefois pas pratique à utiliser si l'on désire un monitoring en temps réel. Une option plus réaliste est d'utiliser cadvisor qui collecte et expose des métriques concernant le système, les VM et les conteneurs.
API de métriques du daemon Docker
Une autre source de métriques est fournie par le démon dockerd lui-même. Pour cela, il est nécessaire d'activer le service dans le fichier daemon.json de Docker :
{
/* ... */
"metrics-addr": "127.0.0.1:9323",
"experimental": true,
/* ... */
}
Il est alors possible d'accéder à ces métriques via une API REST curl -s http://127.0.0.1:9323/metrics.
Note : Il existe d'autres outils comme
ctopqui permettent d'obtenir des informations en temps réel sur les conteneurs exécutés sur un hôte.#!/bin/bash ctop() { docker run --rm -it --name=ctop -v /var/run/docker.sock:/var/run/docker.sock quay.io/vektorlab/ctop } ctop
Monitoring avec Prometheus et Grafana
Il ne reste plus qu'à assembler nos deux sources principales de métriques que sont cadvisor et l'API de métriques de Docker. La solution la plus utilisée pour cela est Prometheus couplé à l'outil de visualisation de données Grafana.
La configuration de Prometheus se fait à travers un fichier prometheus.yml :
# prometheus.yml
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_configs:
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'docker'
static_configs:
- targets: ['<ip-du-serveur-docker-à-monitorer>:9323']
- job_name: 'cadvisor'
static_configs:
- targets: ['<ip-du-serveur-docker-à-monitorer>:8081']
Il faut également déclarer Prometheus comme source de données pour Grafana :
# datasources/prometheus_ds.yml
datasources:
- name: Prometheus
access: proxy
type: prometheus
url: http://prometheus:9090
isDefault: true
Le déploiement des différents services se fait alors via un fichier Docker compose :
# docker-compose.yml
version: '3.9'
networks:
default:
name: monitoring
volumes:
prometheus_data:
grafana_data:
services:
prometheus:
image: prom/prometheus
ports:
- published: 9090
target: 9090
protocol: tcp
volumes:
- type: bind
source: ${PWD}/prometheus.yml
target: /etc/prometheus/prometheus.yml
- type: volume
source: prometheus_data
target: /prometheus
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.retention=72h
networks:
- default
cadvisor:
image: gcr.io/cadvisor/cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
command: -logtostderr -docker_only
networks:
- default
grafana:
image: grafana/grafana
ports:
- 3000:3000
restart: unless-stopped
volumes:
- ${PWD}/datasources:/etc/grafana/provisioning/datasources
- grafana_data:/var/lib/grafana
networks:
- default
Ce fichier déploie Prometheus, cadvisor et Grafana.
Plugins de Grafana
La mise en place du monitoring d'un swarm Docker n'est pas une tâche très compliquée, mais elle est relativement complexe du fait du nombre de service à intégrer et, surtout, du nombre de plugins disponibles pour Grafana ! Trouver le plugin le plus adapté à ses besoins peut-être une tâche longue et fastidieuse faite d'expérimentation et d'essais et erreurs. Il faudra également dans de nombreux cas modifier la configuration de Prometheus et/ou ajouter d'autres sources de données pour Grafana.
Une option est l'utilisation d'une solution clé en main telle que swarmprom ou vegasbrianc/prometheus. Ces solutions sont hélas souvent non mises à jour, mais elles peuvent servir de base à la mise en place du monitoring.
Agrégation des logs
Pour ce qui est de l'agrégation des logs, Docker intègre directement Graylog via le driver gelf1.
{
"log-driver": "gelf",
"log-opts": {
"gelf-address": "udp://1<remote_address>:<remote port>"
}
}
Son intégration à l'infrastructure mise en place par USSI ne devrait donc poser aucun problème.
Étude de solution pour résoudre le problème du partage de données entre les noeuds du cluster
Actuellement, le partage des données de runtime entre les noeuds du swarm se fait grâce au partage NFS d'un volume depuis le manager1 du cluster. Cela permet de très bonnes performances lors des builds, mais l'indisponibilité du manager1 provoquera l'indisponibilité de tous le swarm. Cette solution bien que fonctionnelle n'est pas tellement désirable en production. Ce problème peut être mitigé par la mise en place de mesures en concertation avec l'équipe système :
- le déplacement du manager 1 vers un autre Data Center lors des interventions planifiées
- une procédure pour réinstancier rapidement le manager 1 en cas de crash
- un monitoring méticuleux de l'infrastructure afin de détecter rapidement une indisponibilité
De plus le temps limité nécessaire à la ré-instanciation du manager 1 limite la durée d'indisponibilité des services.
Note: cette situation n'est pas spécifique à mon infrastructure. En effet, la situation serait la même en cas de perte de la plateforme Ceph Gateway qui permet le partage NFS dans les Data Centers, mais avec un plus gros impact puisque c'est l'ensemble des infrastructures applicatives qui dépendent de NFS qui tomberaient (Portail, Moodle...)
Afin de résoudre ce point de rupture, plusieurs solutions peuvent être appliquées selon le type de données.
Docker lui-même fournit des solutions pour stocker et partager les données entre ses conteneurs :
- Données purement statiques pourraient être copiées dans l'image Docker d'une application, mais dans ce cas, le fichier Dockerfile devra être écrit correctement afin d'éviter la reconstruction inutile de layers.
- Les fichiers de configurations peuvent être mis à disposition via la commande
docker config - Les fichiers contenant des données confidentielles (clés, certificats, credentials...) peuvent être rendues disponibles de manière sécurisée via la commande
docker secret - Les données internes générées au runtime par les conteneurs ou durant le build des images peuvent être mises à disposition via des volumes Docker (commande
docker volume)
Ces méthodes permettent d'isoler les données et de ne les rendre accessibles qu'aux seuls conteneurs. Toutefois, cela signifie qu'il est impossible par exemple de modifier en temps réel ces données depuis l'hôte. Or, dans certains cas, ce type de modification est nécessaire afin d'éviter de passer par des opérations longues telles que le build d'images, la copie de fichier dans un volume depuis un conteneur...
Il existe également de nombreuses solutions en dehors de Docker. En voici quelques unes :
- Pour des données où les performances ne sont pas un problème et où l'indisponibilité du volume a peu d'impact, un montage NFS (par exemple depuis le Ceph Gateway de SIPR) est envisageable. Remarquons que le montage NFS peut se faire soit via Docker lui-même, pûisqu'il fournit un driver NFS pour ses volumes, soit directement sur l'hôte en montant un répertoire local dans les conteneurs Docker.
- Pour des données où la redondance et la résistance à un crash sont importantes, une solution comme GlusterFS ou CephFS peuvent être indiquées.
- Pour les données modifiées rarement (exemple uniquement en cas de mise à jour), on pourrait imaginer d'utiliser un mécanisme de synchronisation de système de fichier tel que rsync. Toutefois cette solution requiert un mécanisme d'automatisation pour être vraiment efficace.
Comparaison de solutions de stockage redondant
Solution Performances Redondance Temps réel NFS depuis le manager 1 + - oui GlusterFS - + oui NFS via Ceph Gateway - - oui Synchro via rsync - + non Chacune de ces solutions est indiquées pour certains types d'application :
- NFS depuis la machine de build : infrastructures non critiques où les performances d'écriture sont importantes, en production uniquement s’il est possible de garantir la stabilité et la disponibilité du serveur NFS
- Gluster FS : infrastructure avec N managers, petit nombre de fichier à écrire, ne convient pas si les performances d'écriture sont essentielles
- NFS via Ceph Gateway : production ou performances d'écriture non essentielles
- CephFS : plutôt destiné à des grosses infrastructures, à étudier avec SIPR
- Synchronisation via rsync : uniquement pour les fichiers read-only et lors de l'install; nécessite l'espace disque suffisant sur tous les hôtes
Stockage de fichier redondant avec GlusterFS
Afin d'étudier la possibilité d'ajouter un stockage redondant sur mon infrastructure, j'ai mis en place une petite infrastructure de démonstration avec GlusterFS.
Note: Cette infrastructure n'a au final pas été mise en place car ses performances sont identiques à celles du Ceph Gateway de SIPR pour l'écriture d'un grand nombre de petits fichiers, ce qui la rendait inutilisable pour certaines applications complexes.
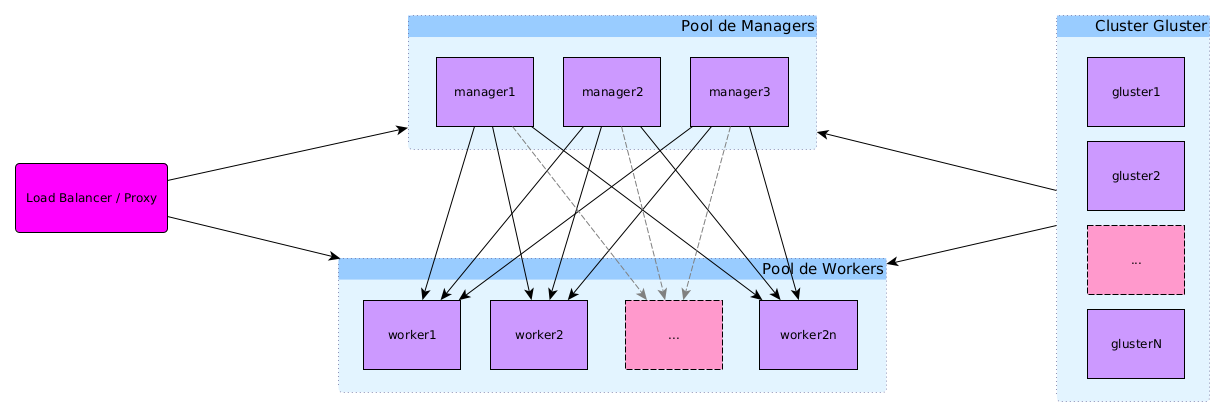
Nombre de noeuds
Le nombre minimum de noeud pour un cluster de production est de 3 afin d'éviter les problèmes de "split-brain", c'est-à-dire une incohérence sur l'état du cluster entre les différents noeuds. Dans mon cas, je me suis toutefois limité à 2 noeuds puisqu'il s'agissait uniquement d'un test.
Installer et configurer un cluster glusterfs (Debian 11)
Sur chaque noeud :
sudo apt install glusterfs-server
sudo systemctl start glusterd
sudo systemctl enable glusterd
Note : toutes les commandes suivantes s'effectuent en tant que
rootou viasudo.
Modifier /etc/hosts pour ajouter les nœuds du cluster sur chaque nœud :
## gluster node 1
127.0.0.1 localhost gluster01
<IP GLUSTER NODE 2> gluster02
...
<IP GLUSTER NODE N> glusterN
Enregistrer les nœuds (sur le premier nœud uniquement) :
gluster peer probe gluster02
## ...
gluster peer probe glusterN
Vérifier le statut avec gluster peer status et lister les noeuds dans le pool avec gluster pool list :
gluster pool list
UUID Hostname State
da6f41b1-a3e5-4015-b37e-a08a8e40f5ff gluster02 Connected
b9647657-67ad-4cdf-84cc-532bbc0009ec gluster03 Connected
bb3d1da6-a6fb-4ccb-89af-cae71b326c07 localhost Connected
Volume répliqué avec Gluster
Créer un volume glusterfs répliqué (exemple)
## /data doit être un stockage hors du system root
sudo mkdir -p /data/glusterfs/vol-1/brick
## si /data est dans le système root il faut ajouter force (pour des besoins de test par exemple)
sudo gluster volume create vol-1 replica 3 gluster01:/data/glusterfs/vol-1/brick gluster02:/data/glusterfs/vol-1/brick gluster03:/data/glusterfs/vol-1/brick
sudo gluster volume start vol-1
Test sur tous les hôtes
sudo mkdir -p /mnt/vol-1
sudo mount -t glusterfs gluster01:vol-1 /mnt/vol-1
Pour ajouter dans
/etc/fstab:sudo vim /etc/fstab ## ajouter gluster01:/vol-1 /mnt/vol-1 glusterfs defaults,_netdev 0 0 ## monter les volumes mount -a
Reste encore à gérer les droits d'accès sur le montage :
- Version hardcore :
sudo chmod ugo+rwx /mnt/vol-1 - Version avancée : utiliser les acl POSIX comme pour NFS
Nettoyer après les tests :
## sur tous les hôtes
sudo umount /mnt/vol-1
## sur gluster01
sudo gluster volume stop vol-1
sudo gluster volume delete vol-1
Montage via /etc/fstab et performances pour la production
Les options par défaut de glusterfs sont insuffisantes pour la production.
Au niveau des volumes gluster, les variables de performances sont :
- performance.write-behind-window-size – the size in bytes to use for the per file write behind buffer. Default: 1MB.
- performance.cache-refresh-timeout – the time in seconds a cached data file will be kept until data revalidation occurs. Default: 1 second.
- performance.cache-size – the size in bytes to use for the read cache. Default: 32MB.
- cluster.stripe-block-size – the size in bytes of the unit that will be read from or written to on the GlusterFS volume. Smaller values are better for smaller files and larger sizes for larger files. Default: 128KB.
- performance.io-thread-count – is the maximum number of threads used for IO. Higher numbers improve concurrent IO operations, providing your disks can keep up. Default: 16.
Source : https://www.jamescoyle.net/how-to/559-glusterfs-performance-tuning
Elles peuvent être configurées via le client CLI de gluster :
gluster volume set [VOLUME] [OPTION] [PARAMETER]
Exemple:
gluster volume set myvolume performance.cache-size 1GB
Ou dans le fichier de configuration /etc/glusterfs/glusterfs.vol.
Les options à indiquer dans /etc/fstab sont :
<GLUSTER HOST>:<VOLUME> <MOUNT PATH> glusterfs defaults,direct-io-mode=disable,_netdev 0 0
Configuration afin d'améliorer les performances
gluster volume set vol-1 client.event-threads 32 ## was 2
gluster volume set vol-1 server.event-threads 32 ## was 2
gluster volume set vol-1 features.cache-invalidation on ## was off
gluster volume set vol-1 features.cache-invalidation-timeout 600 ## was 60
gluster volume set vol-1 performance.cache-invalidation on
Consensus et Glusterfs
Comme pour Docker Swarm, un nombre paire de répliques de volumes peuvent causer un "split-brain", c'est-à-dire une situation dans laquelle aucun consensus ne peut être trouvé pour l'état du volume. Il est conseillé d'avoir un nombre impair de noeuds (minimum 3) pour Glusterfs.
https://docs.gluster.org/en/latest/Troubleshooting/resolving-splitbrain/
Schéma de l'infrastructure avec le cluster Gluster
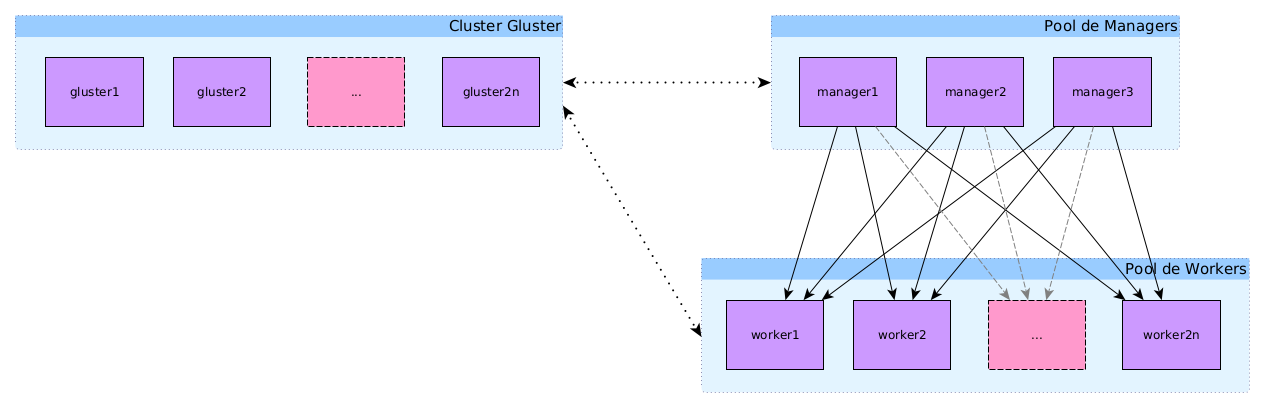
Conclusion
Après plusieurs tentatives infructueuses et la consultation de plusieurs sources, il s'avère que l'utilisation de GlusterFS ne convient pas pour l'écriture d'un grans nombre de petits fichiers. Or, de nombreuses applications PHP modernes utilisent le gestionnaire de paquets composer et vont donc dépendre d'un très grand nombre de tels petits fichiers qui devront être partagés entre les hôtes du cluster.
A titre d'exemple, une installation de Drupal compte plusieurs dizaines de milliers de fichiers ! Cela exclut GlusterFS pour ce type d'application et donc pour mon infrastructure.
Synchronisation via Rsync
Une autre possibilité envisageable dans certains cas est de synchroniser les fichiers source de l'application via rsync après récupération du code source. Une automatisation pourrait être mise en place afin de synchroniser tout changement automatiquement. Ce système très simple et performant ne gère cependant pas les problèmes d'accès concurrent sur les fichiers durant la synchronisation.
Autres solutions envisageables
Après discussion avec l'équipe SIPR, d'autres solutions pourraient être étudiées dans le futur :
- DRBD + GFS2
- CephFS
Autres points d'attention
- Registry centralisé et sécurisé (option celui de gitlab --> permet ci/cd)
- Build via gitlab-ci + scan des images construites
- Sécurisation de la connexion au démon Docker
- Backup : Docker et Baccula
- Intégration à l'infrastructure SIPR : Docker et Open Nebula
- Stockage redondant, quelles solutions ?
- Docker Swarm et le cloud Azure ?
- Passage à Kubernetes
Vers une infrastructure de production
Même si elle pourrait être déployée en production telle quelle, l’infrastructure proposée présente encore quelques problèmes à traiter.
- le point de rupture constitué par la machine manager qui héberge l’orchestrateur et le stockage de fichiers partagé
- la mise à jour des images afin de garantir une sécurité optimale des applications
- l’automatisation de la mise à jour des machines hôtes
Docker Swarm en production
Reste bien dans la course, mais peut-être moins adapté à des infrastructures de grande taille. Néanmoins, il a l'énorme avantage de la facilité de déployer des applications disponibles pour Docker Compose (c'est à dire de nombreuses applications !).
L'infrastructure décrite dans mon brevet pourrait toutefois être facilement industrialisable, par exemple pour l'hébergement web.
Une infrastructure de ce type devrait avoir
- plusieurs nœuds managers : 3 semble un bon compromis entre redondance et performance, mais l'idéal est d'avoir un manager au moins dans chaque Data Center
- un plus grand nombre de nœuds workers
Un registry centralisé
Pourquoi ? Un registry centralisé pourrait avoir de nombreux avantages :
- éviter de devoir construire les images sur chaque infrastructure
- avoir des images à jour
- permettre de forcer la mise à jour des images des services afin de garantir la sécurité
Une solution simple est d'utiliser le registry intégré à Gitlab afin d'assurer la centralisation des images et l'interopérabilité avec Gitlab.
Résoudre le point de rupture du manager
Le point faible de notre infrastructure : le manager et le système de fichiers partagé sont sur une seule et même machine sans redondance. En cas d’indisponibilité de cette machine tout le système s’écroule.
La perte du manager provoque actuellement un downtime de l’ensemble de l’infrastructure car
- On perd la machine qui assure la gestion du cluster. Ce problème peut-être résolu en multipliant le nombre de machine manager et assurer ainsi la redondance. Toutefois, le nombre de machine manager nécessaire est imposé par l'implémentation de l’algorithme de consensus entre les nœuds manager 23.
- On perd le partage système de fichiers NFS entre les nœuds du cluster. Si le manager tombe, les workers perdront donc l'accès à leurs données. Une solution possible est le montage d’un file system partagé depuis le stockage Ceph de SIPR, soit en utilisant NFS (mais nos tests à ce sujet ont mis en évidence des pertes sensibles de performances et ont justifié le partage du file system depuis le manager), soit en passant à un protocole de partage mieux adaptés aux conteneurs comme par exemple GlusterFS4.
Il faudra donc mettre en place une redondance et un fail over soit au niveau du manager, soit au niveau du montage partagé lui-même. Cette question sera abordée plus en détail dans le chapitre des perspectives consacré à la mise en place d’une infrastructure de production.
Solutions testées à ce jour :
- Export NFS depuis un manager : très performant, pas de redondance, perte du cluster en cas de perte du manager
- Export NFS depuis un cluster Ceph : peu performant, pas de redondance, perte du cluster en cas de perte du serveur NFS
- Cluster GlusterFS : peu performant, redondant, ne convient pas pour les builds
A tester :
- Utiliser un répertoire local et utiliser rsync pour synchroniser entre machine : pas temps réel, peu performant
Mise à jour des images et services : la livraison continue appliquée à l’infrastructure
La mise à jour (automatique) des images et le rafraîchissement des services : la livraison continue appliquée à l’infrastructure.
Une manière de résoudre cela est d’automatiser le build des images en utilisant un pipeline Jenkins.
Source : https://blog.nimbleci.com/2016/08/31/how-to-build-docker-images-automatically-with-jenkins-pipeline/
Vers une infrastructure basée sur Kubernetes et Rancher
De « Docker Swarm is dead ? » à « Kubernetes will drop Docker support ! » : (r)évolutions et troubles dans le petit monde des conteneurs
Plusieurs annonces récentes posent question quant à l’avenir de la solution proposée dans ce brevet :
- Fin 2019, la maintenance de l’orchestrateur Docker Swarm annoncée jusque fin 2022 qui laissait penser à un abandon de cette solution suite au rachat de Docker Enterprise par Mirantis et de nombreuses rumeur annoncaient même la mort de Docker Swarm567
- Début 2020, toutefois, l’annonce de la continuation du développement et du support de Docker Swarm par Mirantis8 est venue contredire les rumeurs de fin 2019
- Fin 2020, l’annonce de l’abandon du support du moteur Docker par Kubernetes au profit d’autres solutions respectant la spécification CRI (Container Runtime Interface)9 10 est venue semer le trouble dans le petit monde des conteneurs. De son côté, la société Mirantis a annoncé dans les semaines suivantes qu'elle continuerait le développement d'une version compatible avec la spécification CRI de l'interface Docker pour Kubernetes.
- Depuis 2022, l'abandon de Docker au profit de containerd dans Kubernetes est effectif.
À ce stade, l’infrastructure mise en place dans le présent projet n’est pas directement menacée par ces bouleversements, et elle reste parfaitement indiquée tant pour l’infrastructure webpps que pour son utilisation pressentie pour le futur portail web de l'UCLouvain.
Toutefois, Docker Swarm présente quelques limitations par rapport à Kubernetes pour une utilisation sur des infrastructures à plus grande échelle. En particulier, il n’est pas compatible avec autant de solution d’hébergement cloud que Kubernetes et ses dérivés.
Ce chapitre s’intéressera donc à quelques considérations importantes en vue d’un passage à une infrastructure basée sur Kubernetes.
L’écosystème Kubernetes
De nombreuses solutions existent pour la gestion de cloud] que cela concerne les environnements d’exécution, les orchestrateurs, les stockages ou encore le provisioning… La CNCF (Cloud Native Computing Foundation) dresse un portrait de toutes ces solutions11. Parmi celles-ci, les plus représentées font partie de l’écosystème Kubernetes.
Kubernetes a été initialement développé par Google et est soutenu par les gros acteurs du monde Linux dont RedHat, Ubuntu, la Apache Foundation… C’est aujourd’hui le leader des orchestrateurs de conteneurs basés sur Docker.
Il a l'avantage de reposer et de proposer une série d’API et de spécifications standardisées qui ont permis l'émergence d'une grande quantité de solution compatibles et d’orchestrateurs alternatifs.
Kubernetes est un système extrêmement personnalisable, en particulier via ses 3 définitions d’interface :
- Container Network Interface (CNI) : spécifie les interfaces réseaux utilisables par Kubernetes (p. ex. Calico, Flannel ou Canal)
- Container Runtime Interface (CRI) : spécifie l'interaction avec l’environnement d’exécution des conteneurs et intègre complètement les standards Open Container Initiative (OCI) (par exemple cri-conbtainerd, cri-o ou encore frakti)
- Container Storage Interface (CSI) : spécifie les volumes utilisables comme stockage de Kubernetes
Kubernetes et Docker
Bien qu’il soit une solution concurrente via Docker Swarm, Docker a été utilisé comme environnement d’exécution de conteneurs par défaut de Kubernetes depuis le départ.
Kubernetes en collaboration avec les acteurs liés au développement de plusieurs environnements d'exécution de conteneurs (Core OS, Hyper, Google…) a défini une API pour l’utilisation des conteneurs et la définition des images : la spécification CRI (Container Runtime Interface).
Plusieurs implémentations de cette API ont vu le jour dont les 2 principales sont CRI-Containerd (implémentation au-dessus de containerd) et CRI-O (pour les environnements compatibles avec les standards de l’Open Container Initiative).
De son côté, Docker n’est pas compatible directement avec la spécification CRI et est connecté à Kubernetes via une couche supplémentaire appelée dockershim. Mais, depuis la mise en place de CRI-Containerd, Docker (lui-même construit au-dessus de containerd) constitue aujourd’hui une surcouche inutile entre Kubernetes et containerd.
Tout cela a amené Kubernetes à abandonner le support de dockershim et, par extension, de Docker lui-même auprofit de containerd.
Kubernetes versus Docker Swarm
Kubernetes est plus perfectionné et plus complet que Docker Swarm. Il est également beaucoup plus flexible puisqu’il permet d’utiliser d’autres moteurs de conteneurs que Docker.
Permet une plus grande configuration des ressources allouées aux conteneurs.
Vocabulaire : service vs pod
Les solutions d’orchestration pour Kubernetes
Il existe de nombreuses implémentations de l'orchestrateur Kubernetes spécialisées selon l'usage qui en est attendu :
| Produit | Types | Éditeur | Description |
|---|---|---|---|
| Kubernetes | dev, prod | Kubernetes | Implémentation officielle via les services kubeadm, kubelet et kubectl. Extrêmement puissante mais, en conséquence, assez difficile à prendre en main. Plutôt destinée à de grosses infrastructures. |
| Minikube | dev | Kubernetes | Orchestrateur destinés aux développeurs et permettant le déploiement d'un cluster local pour tester le déploiement d'applications. Pas adapté à une infrastructure de production. |
| Microk8s | dev, prod | Canonical | Orchestrateur léger maintenu par Canonical. Il était au départ destiné au développement et à l'IoT, mais il convient également aux infrastructures de production. |
| Rancher | prod | Rancher | Orchestrateur complet et performant destiné à des infrastructures de production via le RKT (Rancher Kubernetes Toolkit). |
| OpenShift | prod | RedHat | Plateforme complète destinée à la mise en place d'un cloud kubernetes d'entreprise12. |
| Kind | dev | kind | Alternative à minikube et microk8s pour le test local d'un cluster kubernetes |
| Podman | dev, prod | RedHat | Alternative à Docker et orchestrateur pour Kubernetes |
Il existe d’autres solutions, mais elles sont moins répandues que celles citées ci-dessus. Ajoutons que des solutions de gestion de cloud intègre parfois la gestion de conteneurs, par exemple OpenNebula.
Les deux candidats les plus appropriés pour une infrastructure du type de celle étudiée ici sont Rancher et Microk8s.
- Microk8s a l’avantage de pouvoir fonctionner tant sur la machine d’un développeur que pour le déploiement sur une infrastructure cloud ou pour le déploiement sur des devices IoT.
- Rancher pour sa part est simple à mettre en œuvre, mais requiert un outil supplémentaire ou d’installer Rancher en local (ce qui n’est pas nécessairement évident à faire) pour tester les déploiements sur une machine de développement (par exemple minikube ou kind).
De son côté, Kubernetes est plus complexe et plus lourd à mettre en oeuvre. Comme Rancher, il requiert un outil supplémentaire pour les développeurs. Quant à OpenShift son cadre d’application est celui d’un cloud d’entreprise.
Des outils supplémentaires :
- Helm : permet la gestion des applications Kubernetes via un format de paquets appelé Charts et intégrant la gestion des dépendances, la dépréciation, la gestion des sources…
- Terraform : outil permettant la gestion du déploiement d’infrastructure comme du code via son propre langage de déclaration (également compatible avec Docker, et avec les clouds Azure et Amazon)
- Harbor : registre d’applications pour Kubernetes
Rancher : Kubernetes-as-a-service
Rancher est l’un des orchestrateurs Kubernetes les plus utilisés. Il est relativement simple à installer et à prendre en main. C’est de plus une solution qui se prête bien aux petites ou moyennes infrastructures. Il est de ce fait plus adapté pour l'infrastructure visée par ce brevet que OpenShift ou Kubeadm.
La principale limitation de Rancher est qu’il n’est pas officiellement supporté sur toutes les distributions Linux (le site de Rancher fournit une liste des versions supportées). En particulier, il n’est pas officiellement supporté sous Debian13.
Cela ne constitue toutefois pas un problème dans le cadre de l'UCLouvain puisque plusieurs distributions compatibles sont disponibles dans l'infrastructure de SIPR. On pourrait par exemple faire le choix d’une distribution Ubuntu LTS qui est dérivée de Debian et utilise donc les mêmes outils.
Outils :
- Rancher : une interface web
- Rancher CLI : outil de gestion en ligne de commande
- Rancher API Server : ensemble de services web pour la gestion du cluster
- Rancher Agent : agent de contrôle des nœuds du cluster
- Rancher Kubernetes Engine (RKE) : distribution Kubernetes légère et performante intégrée à Rancher et conçue pour s’exécuter dans des conteneurs
Vers la mise en place d’un cloud d’entreprise basé sur les conteneurs dans l'infrastructure SIPR
Voici finalement quelques pistes pour améliorer la prise en charge de Docker dans l'infrastructure système de SIPR.
Docker, Kubernetes et Rancher dans Open Nebula
Tout d'abord, Open Nebula, le logiciel de gestion d'infrastructure utilisé par SIPR, permet d’intégrer Docker et Kubernetes14 et, depuis la version 5.12, Open Nebula prévoit l’intégration de Rancher15.
Voir aussi :
- OpenNebula Kubernetes Appliance : https://docs.opennebula.io/appliances/service/kubernetes.html
- OpenNebula Docker Appliance : https://docs.opennebula.io/appliances/service/docker.html
Backup et conteneurs
Au niveau des backups, Bacula Enterprise, la solution utilisée pour l’infrastructure UCLouvain, propose des solutions de backup et restauration pour les conteneurs :
- Docker Container Backup and Restore https://www.baculasystems.com/docker-container-backup/
- How to Backup and Restore Docker Containers with Bacula Enterprise? https://www.baculasystems.com/how-to-backup-and-restore-docker-containers-with-bacula-enterprise/
- Kubernetes Backup and Restore https://www.baculasystems.com/kubernetes-backup-restore/
- How to Backup and Restore or Migrate a Kubernetes Cluster? https://www.baculasystems.com/how-to-backup-and-restore-kubernetes-clusters/
Vers une intégration des conteneurs dans l'infarstructure SIPR ?
Il est donc tout à fait possible d'intégrer directement les conteneurs dans les pratiques actuelles de SIPR. Toutefois ces outils demandent encore à être testés afin de montrer les adéquations avec les demandes de conteneurs à l'UCLouvain.
Graylog Extended Format logging driver https://docs.docker.com/config/containers/logging/gelf/
L’algorithme utilisé est RAFT, pour plus de détails, voir la page « Raft consensus in swarm mode » de la documentation Docker https://docs.docker.com/engine/swarm/raft/
Les règles concernant le nombre de nœuds manager nécessaire pour garantir le quorum sont définies dans le guide d’administration et de maintenance de Docker Swarm https://docs.docker.com/engine/swarm/admin_guide/
Voir par exemple « Tutorial: Create a Docker Swarm with Persistent Storage Using GlusterFS » https://thenewstack.io/tutorial-create-a-docker-swarm-with-persistent-storage-using-glusterfs/
La fin du support de Docker swarm avait été annoncée pour 2022. Sauf reprise par la communauté ou une société tierce, cela aurait marqué la mort de ce produit. Toutefois la société Mirabilis a par la suite annoncé qu'elle continuerait le développement de Swarm.
What We Announced Today and Why it Matters, November 13, 2019 https://www.mirantis.com/blog/mirantis-acquires-docker-enterprise-platform-business/
Notons que la fin de Docker Swarm est une rumeur qui revient souvent dans les discussions depuis au moins 2017 https://www.bretfisher.com/is-swarm-dead-answered-by-a-docker-captain/
Mirantis will continue to support and develop Docker Swarm (24/02/2020) https://www.mirantis.com/blog/mirantis-will-continue-to-support-and-develop-docker-swarm/
« Don't Panic: Kubernetes and Docker » https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/
« Kubernetes (Sorta) Drops Docker Support: It's Not as Bad It Sounds » https://www.cbtnuggets.com/blog/devops/kubernetes-sorta-drops-docker-its-not-as-bad-it-sounds
CNCF Cloud Native Interactive Landscape https://landscape.cncf.io/
What is OpenShift? https://www.openshift.com/learn/what-is-openshift
En pratique, il est tout à fait possible d’installer Rancher sous Debian.
Documentation d’OpenNebula, Docker and Kubernetes http://docs.opennebula.io/5.12/advanced_components/applications_containerization/index.html
Intégration de Rancher dans la documentation d’OpenNebula http://docs.opennebula.io/5.12/advanced_components/applications_containerization/rancher_integration.html
Kubernetes dropping Docker runtime support – what it means for enterprises (10/12/2020) https://www.avenga.com/magazine/kubernetes-dropping-docker/